参考までに、Power BIは、Microsoftによって開発されたデータの視覚化および分析ソフトウェアです。 Power BIは、静的およびインタラクティブなデータの視覚化に使用できます。 Power BIで実際の視覚化を作成する前に、PowerBIクエリエディターを使用してデータの前処理を実行できます。
クエリエディタを使用すると、列タイプの変更、欠落している値の処理、行と列の削除、列のピボットとピボット解除、列の分割など、さまざまなデータ変換タスクを実行できます。
この記事では、Power BIクエリエディターを使用して列をピボット、ピボット解除、および分割する方法を説明します。
データセットをクエリエディタにインポートする
この記事で例として使用されているデータセットは、このkaggleリンクを使用してダウンロードできるCSVファイル形式です。 CSVファイルをローカルファイルシステムにダウンロードします。
次に、Power BI Desktopを開き、トップメニューから[データの取得]ボタンをクリックします。ドロップダウンリストから、以下に示すように[テキスト/CSV]を選択します。
Power BIは、データのインポートに時間がかかります。データが読み込まれると、下のウィンドウが表示されます。
データセットには、世界のすべての国の人口、面積、出生率、死亡率、人口密度、1人あたりのGDP、1000人あたりの電話数などに関する情報が含まれています。データをクエリエディタにロードするには、[データの変換]ボタンをクリックします。
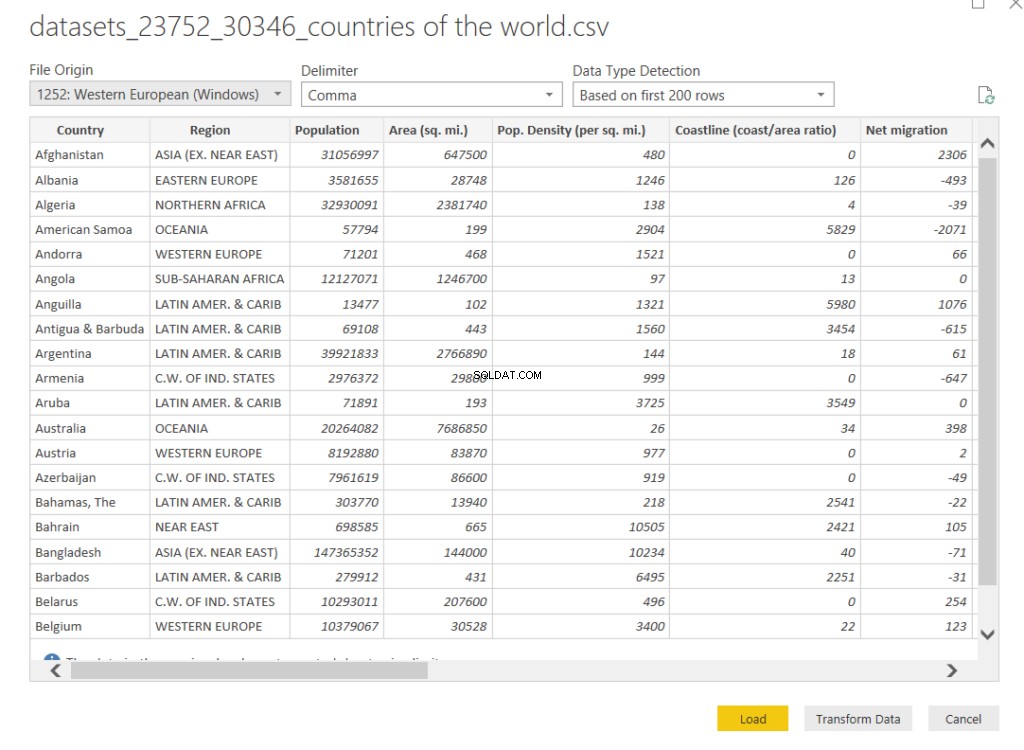
クエリエディタは次のようになります:
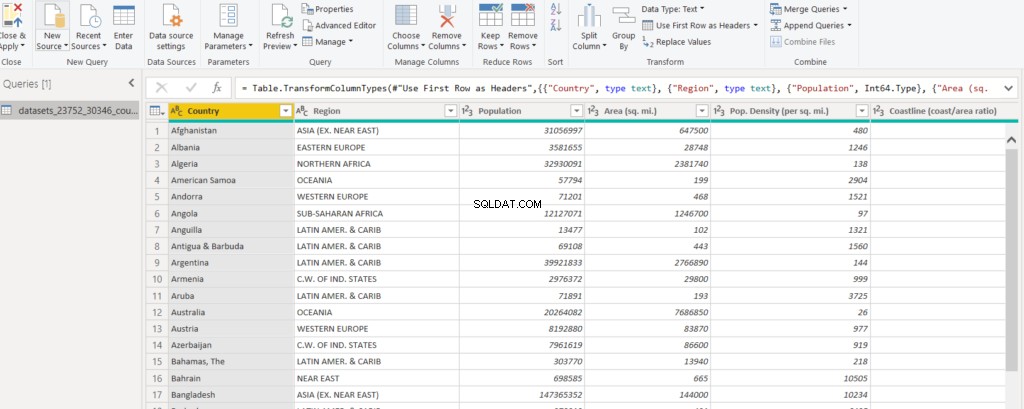
クエリエディタでは、列のピボット、ピボット解除、分割などのさまざまな前処理を実行できます。
ピボット理論とピボット解除理論
実際にPowerBIクエリエディターを使用して列をピボットおよびピボット解除する前に。ピボットを解除する非常に基本的な例を考えてみましょう。
ピボット解除
次の情報を含むデータセットがあると仮定します。次の表の行は国に対応し、列は対応する国の1人当たりGDPと識字率に関する情報を行に示しています。 (注:これらは単なるダミー値であり、実際の値ではありません)
| 国 | 一人当たりGDP | 識字率 |
| フランス | 30,000 | 95% |
| ドイツ | 25,000 | 96% |
1人当たりのGDPなど、単一の列のピボットを解除した場合、ピボットされていない列のあるデータセットは次のようになります。
| 国 | 属性 | 値 | リテラシー |
| フランス | 一人当たりGDP | 30,000 | 95% |
| ドイツ | 一人当たりGDP | 25,000 | 96% |
「一人当たりGDP」列が「属性」と「値」の2つの列に置き換えられていることがわかります。 「属性」列の値は、ピボットされていない列名に対応しますが、「値」列には、ピボットされていない列に以前存在していた値が含まれます。ピボットされていない列は1つだけなので、「属性」列の値は常に同じになります。また、ピボットされていない列が1つあるデータセットの行数は同じままです。
次に、2つの列のピボットを解除するとどうなるかを見てみましょう。元のデータセットの1人当たりGDPと識字率の両方の列のピボットを解除します。ピボットされていない列が2つあるデータセットは次のようになります。
| 国 | 属性 | 値 |
| フランス | 一人当たりGDP | 30,000 |
| フランス | 識字率 | 95% |
| ドイツ | 一人当たりGDP | 25,000 |
| ドイツ | 識字率 | 96% |
上記のデータセットでは、国名ごとに、[属性]列に2つの一意の値(1人あたりのGDPと識字率)が含まれていることがわかります。 「値」列には、属性に対応する値が含まれています。行数が2倍になっていることに注意してください。同様に、3つの列のピボットを解除すると、データセットの行数が3倍になります。
ピボット
ピボットとは、その名前が示すように、ピボットされていないデータセットを元の形式に戻すために使用されるプロセスを指します。たとえば、入力テーブルをピボットすると、次のようになります。
| 国 | 属性 | 値 |
| フランス | 一人当たりGDP | 30,000 |
| フランス | 識字率 | 95% |
| ドイツ | 一人当たりGDP | 25,000 |
| ドイツ | 識字率 | 96% |
「属性」列と「値」列にピボットを適用すると、データセットは次の形式になります。
| 国 | 一人当たりGDP | 識字率 |
| フランス | 30,000 | 95% |
| ドイツ | 25,000 | 96% |
ピボットとアンピボットとは何かがわかったので、PowerBIでそれらを実装する方法を見てみましょう。
PowerBIを使用したピボットとピボット解除
まず、PowerBIクエリエディターを使用して単一の列のピボットを解除する方法の例を見てみましょう。データセットを見ると、「人口」という名前の列が含まれています。 「人口」列のピボットを解除するには、列ヘッダーをクリックして、トップメニューから「変換」オプションを選択します。以下に示すように、いくつかのオプションを含む新しいメニューが上部に表示され、メニューから[列のピボット解除]オプションをクリックしてから、ドロップダウンリストから[列のピボット解除]をクリックします。
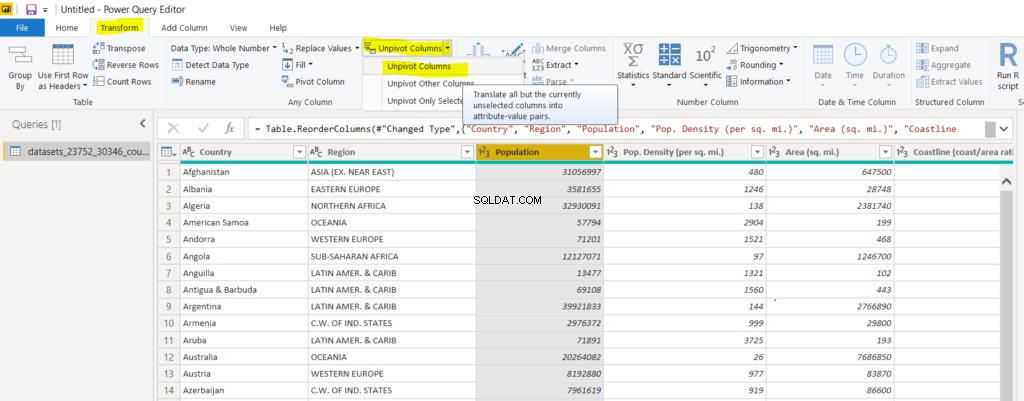
以下に示すように、「Population」列は「Attribute」列と「Value」列に置き換えられます。
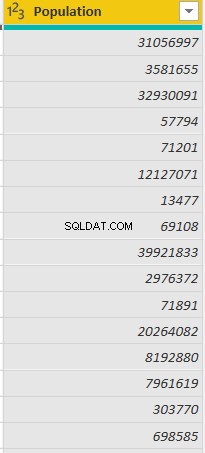
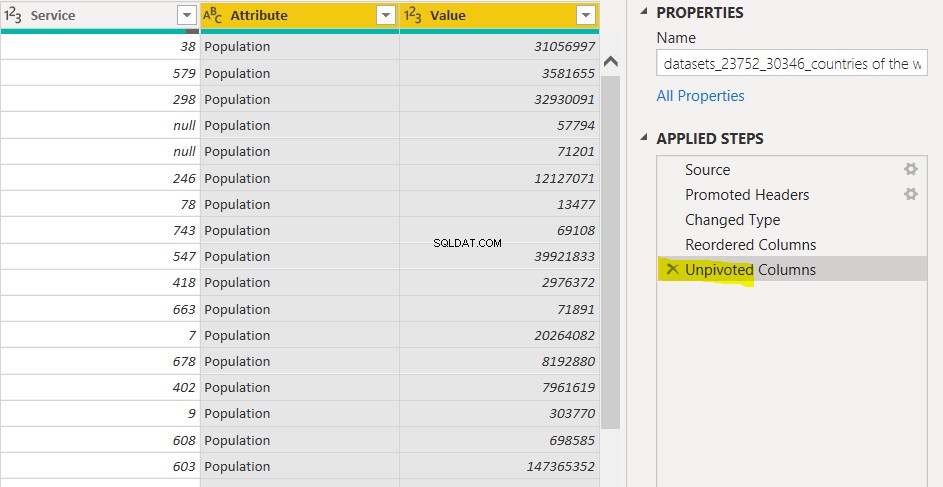
ここで、列をピボットするには、2つのオプションがあります。次のスクリーンショットに示すように、[適用されたステップ]ウィンドウから[xピボットされていない列]オプションをクリックできます。
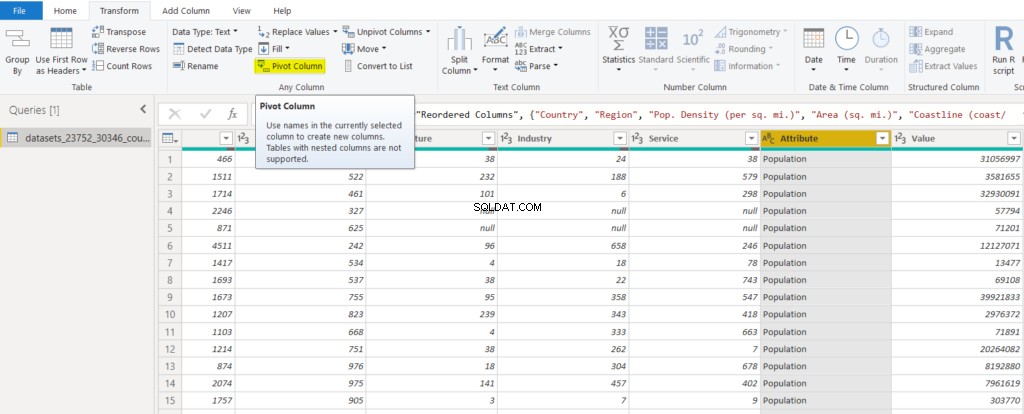
もう1つのオプションは、列を選択してから、以下に示すように、トップメニューから[変換]->[列のピボット]を選択することです。
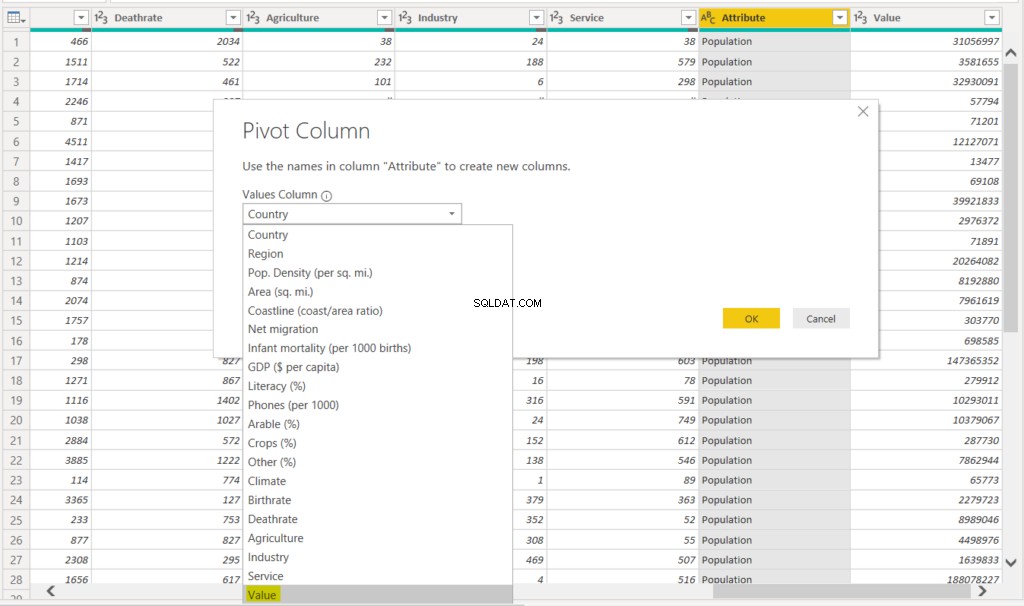
列をピボットするときに、ピボットされていない列の値を含む列を指定する必要があります。この場合、「値」列には、ピボットされていない「属性」列の値が含まれています。次のスクリーンショットを参照してください。
ピボットされた「人口」列は次のようになります:
「Population」列を「Pop」のすぐ横に移動します。次のスクリーンショットに示すように、「人口」列のヘッダーをクリックしてドラッグすることにより、「密度(平方マイルあたり)」列を表示します。
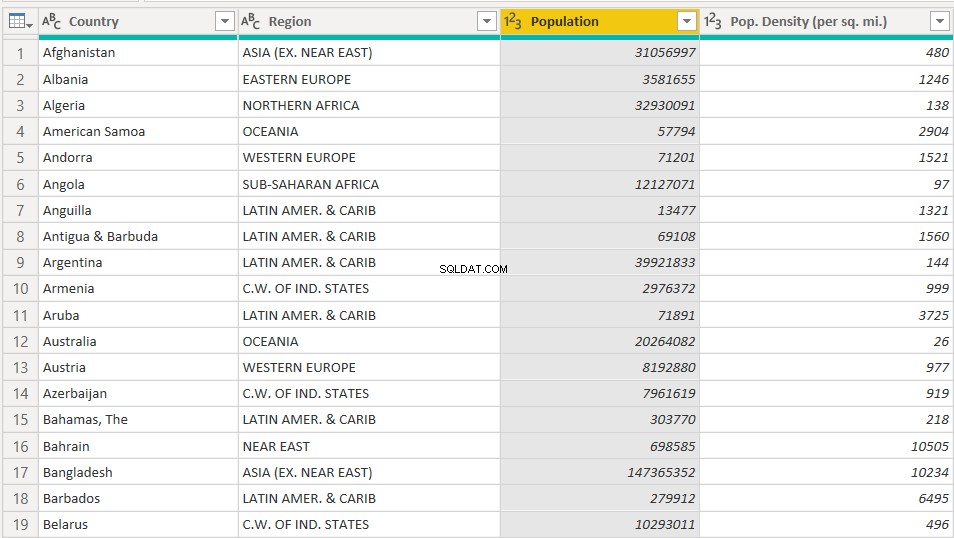
次に、「Population」と「Pop」の2つの列のピボットを解除します。密度(平方マイルあたり)」。以下に示すように、両方の列ヘッダーを選択してから、それらのピボットを解除します。
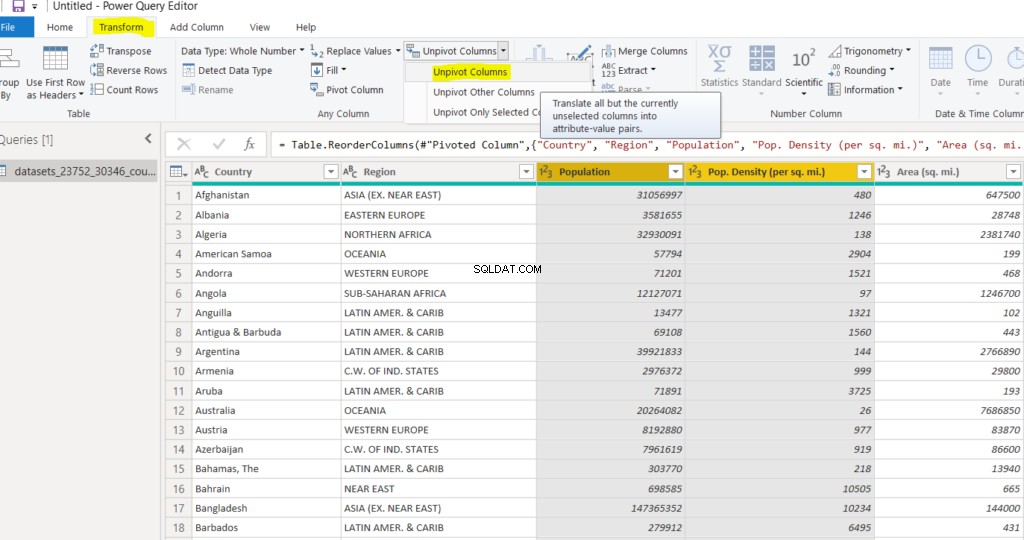
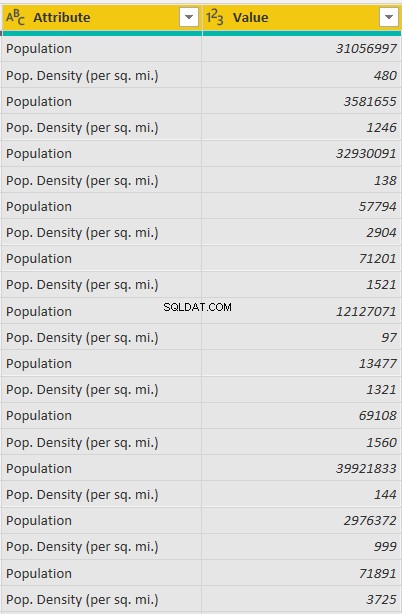
ピボットを解除すると、データセットに次の2つの列が作成されます。 「属性」列に「人口」と「人口」に関する情報が含まれていることがわかります。密度(平方マイルあたり)」。
以下に示すように、両方の列ヘッダーを選択し(CTRL +クリック)、[国]列のすぐ横に列をドラッグします。
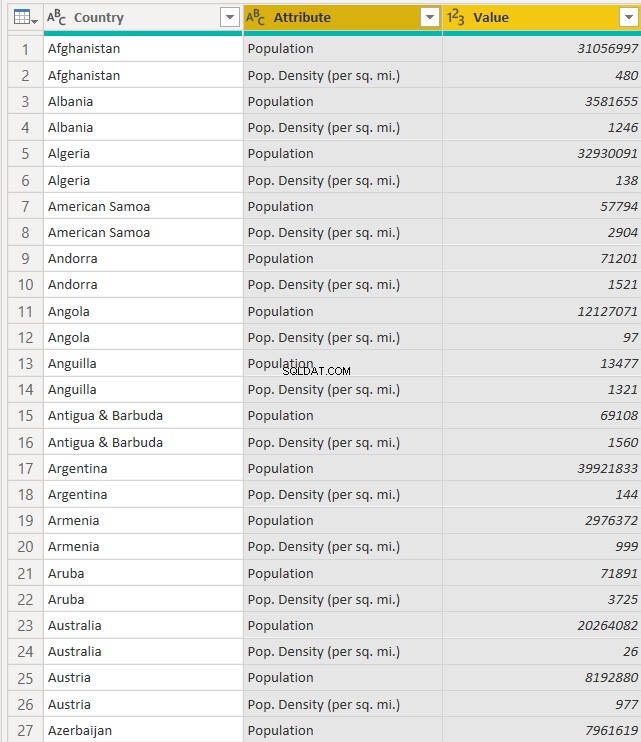
これで、「国」の名前、それらの総人口、および1平方マイルあたりの人口密度を確認できます。 「属性」列には、総人口と1平方マイルあたりの人口密度の2種類の人口が表示されるため、「属性」列の名前を「人口タイプ」に変更してみましょう。列ヘッダー名が更新されたデータセットは次のようになります:
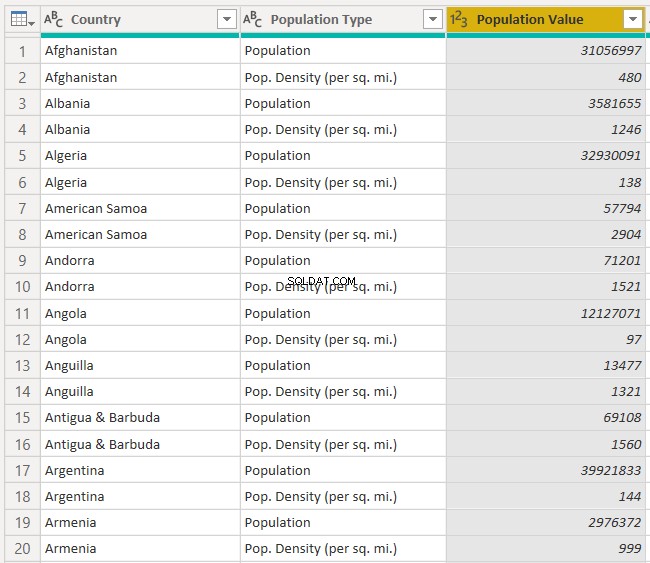
列の分割
列を分割する前に、「人口タイプ」列の一部の値を置き換えます。
「人口タイプ」列の値「人口」は、総人口を示します。値「Population」を「Pop」に置き換えます。 「合計」で、「ポップ」と同じパターンになります。密度(平方マイルあたり)」。次のスクリーンショットに示すように、列の値を置き換えるには、[変換]->[値の置き換え]に移動します。
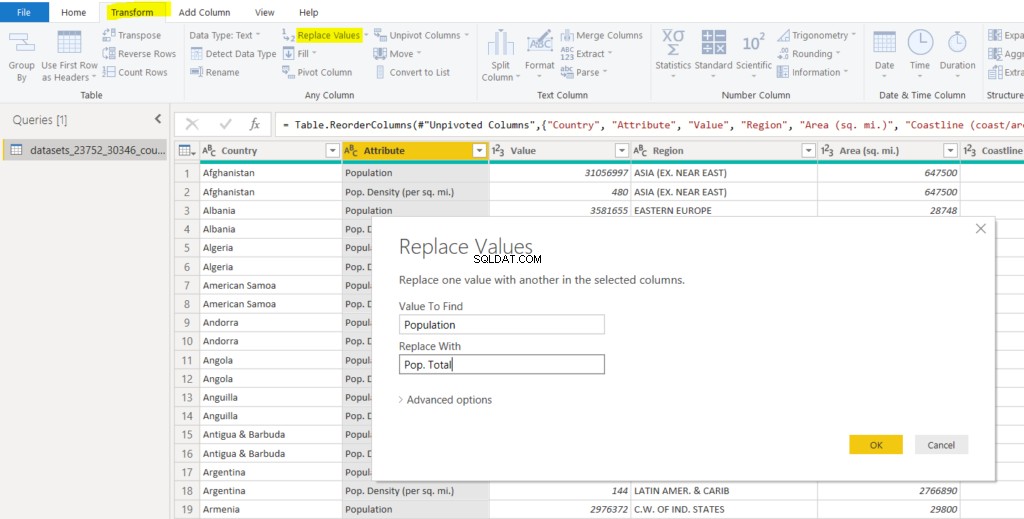
値を置き換えると、データセットは次のようになります。
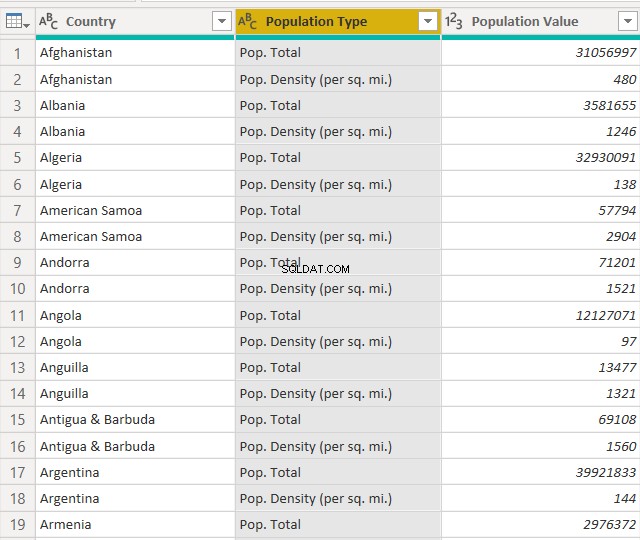
次に、「人口タイプ」列を2つに分割します。最初の5文字が最初の列に追加され、残りの文字が他の列に追加されます。列を分割するには、「変換->列の分割」に移動します。最初の5文字で分割するため、ドロップダウンから[文字数で分割]オプションを選択します。列を最初の5つの左端の文字で分割します。参考までに、次のスクリーンショットをご覧ください。
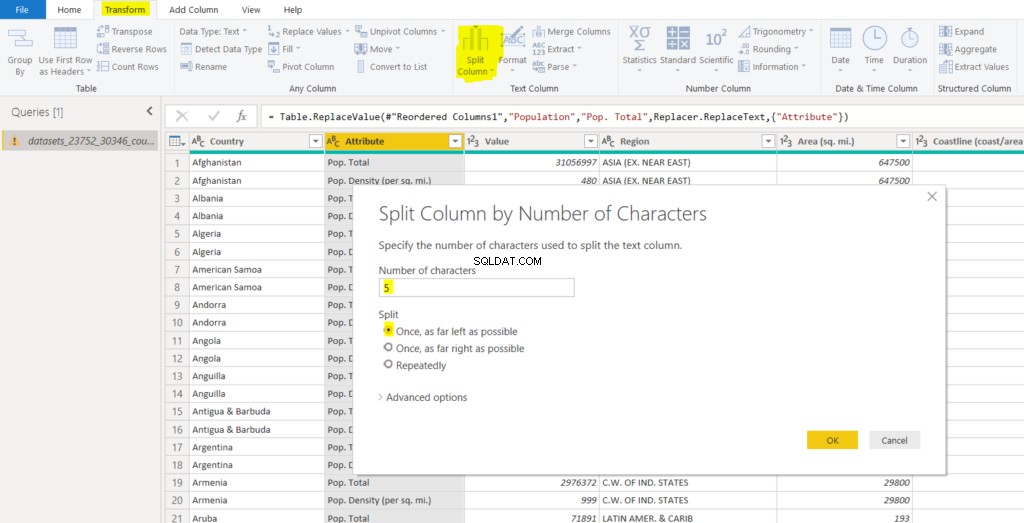
列が分割されると、次の2つの列が表示されます。
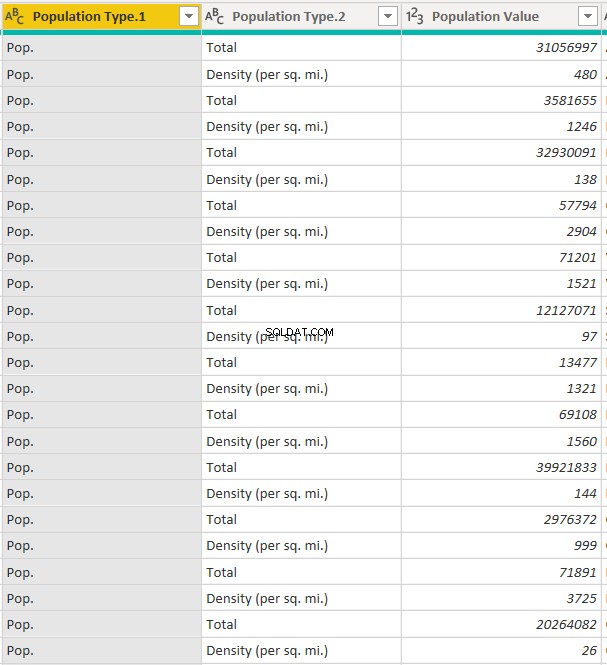
「PopulationType.2」列には、人口のタイプまたは規模に関する情報が含まれているため、必要なのは「PopulationType.2」列だけです。 「PopulationType.1」列をクリックし、「Delete」を選択します。
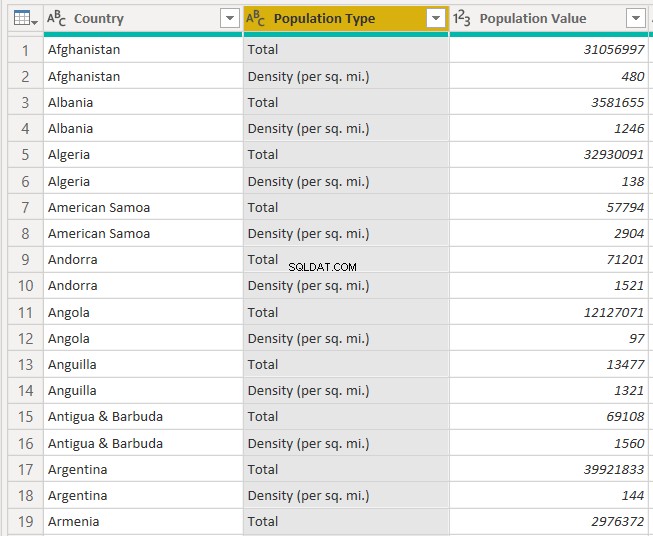
最後に、以下に示すように、「PopulationType.2」列の名前を「PopulationType」に変更できます。
次の図から、国ごとに2つの異なるタイプの人口値があることがわかります。 「人口タイプ」列の「合計」値は、国の総人口を示します。総人口の実際の値は、「人口値」列に保存されます。同様に、「密度(平方マイルあたり)」という値は、この人口値が人口密度を参照していることを示しています。
結論
要約すると、この記事では、PowerBIクエリエディターでピボットとピボット解除を実行する方法を示しています。さらに、明確な例で示されているピボットおよび非ピボット列の背後にある基本的な理論についても説明します。最後に、この記事では、列を分割するプロセスがPowerBIクエリエディターでどのように実装されるかについて説明します。