SQL Serverのパフォーマンスに責任を持つことは、困難な作業になる可能性があります。監視して理解しなければならない領域はたくさんあります。また、これらすべての指標を常に把握し、サーバーで何が起こっているかを常に把握できることが期待されています。 「SQLServerのチューニング」というフレーズを聞いたときに最初に考えることをDBAに尋ねたいと思います。私が得る圧倒的な反応は「クエリチューニング」です。クエリの調整は非常に重要であり、ワークロードは絶えず変化しているため、私たちが直面する終わりのないタスクであることに同意します。
ただし、SQLServerのパフォーマンスについて考えるときに考慮すべき点は他にもたくさんあります。デフォルトから微調整する必要があるインスタンス、OS、およびデータベースレベルの設定がたくさんあります。コンサルタントになることで、私はさまざまな事業分野で働き、あらゆる種類のパフォーマンスの問題に触れることができます。新しいクライアントで作業するときは、常にサーバーのヘルス監査を実行して、自分が何を扱っているかを知るようにしています。これらの監査を実行しているときに、私が繰り返し見つけたものの1つは、SQLServerデータとログファイルが存在するディスクでの過度の読み取りと書き込みの遅延です。
読み取り/書き込みレイテンシ
SQL Serverでディスクの待機時間を表示するには、DMV sys.dm_io_virtual_file_statsにすばやく簡単にクエリを実行できます。 。このDMVは、次の2つのパラメーターを受け入れます。 database_id およびfile_id 。素晴らしいのは、 NULLを渡すことができることです 両方の値として、すべてのデータベースのすべてのファイルのレイテンシーを返します。出力列は次のとおりです。
- database_id
- file_id
- sample_ms
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_written
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
列リストからわかるように、このDMVが取得する非常に有用な情報がありますが、 SELECT * FROM sys.dm_io_virtual_file_stats(NULL、NULL);を実行するだけです。 database_idsを覚えていて、頭の中で数学ができる場合を除いて、あまり役に立ちません。
ファイルの統計情報をクエリするときは、PaulRandalのブログ投稿「SQLServer内からIOサブシステムの待機時間を調べる方法」のクエリを使用します。このスクリプトにより、列名が読みやすくなり、ファイルが存在するドライブ、データベース名、およびファイルへのパスが含まれます。
このDMVを照会することにより、ファイルのI/Oホットスポットがどこにあるかを簡単に知ることができます。書き込みと読み取りの待ち時間が最も長い場所と、どのデータベースが原因であるかを確認できます。これを知っていると、それらの特定のデータベースのチューニングの機会を検討し始めることができます。これには、インデックスの調整、バッファプールがメモリの負荷にさらされているかどうかの確認、データベースをI / Oサブシステムのより高速な部分に移動すること、データベースをパーティション化してファイルグループを他のLUNに分散することなどが含まれます。
したがって、クエリを実行すると、レイテンシーに対してミリ秒単位で多くの値が返されます。どの値が適切で、どの値が不良ですか?
良い値と悪い値は何ですか?
SQLskillsに質問すると、次のようなことがわかります。
- すばらしい:<1ms
- 非常に良い:<5ms
- 良い:5〜10ミリ秒
- 悪い:10〜20ミリ秒
- 悪い:20〜100ミリ秒
- 本当に悪い:100〜500ミリ秒
- OMG!:>500ミリ秒
Bing検索を実行すると、次のような推奨事項を作成しているMicrosoftの記事が見つかります。
- 良い:<10ms
- わかりました:10〜20ミリ秒
- 悪い:20〜50ミリ秒
- ひどく悪い:>50ms
ご覧のとおり、数値には若干のばらつきがありますが、20msを超えるものは面倒と見なすことができるというのがコンセンサスです。そうは言っても、平均書き込みレイテンシは20ミリ秒であり、組織にとって100%許容可能であり、問題ありません。システムの一般的なI/Oレイテンシーを知っておく必要があります。そうすれば、状況が悪化したときに、正常が何であるかを知ることができます。
読み取り/書き込みの待機時間が悪いのですが、どうすればよいですか?
サーバーで読み取りと書き込みの待機時間が悪いことがわかった場合は、問題を探し始めることができる場所がいくつかあります。これは包括的なリストではありませんが、どこから始めればよいかについてのガイダンスです。
- ワークロードを分析します。インデックス作成戦略は正しいですか?適切なインデックスがないと、ディスクから読み取られるデータがはるかに多くなります。シークの代わりにスキャンします。
- 統計は最新ですか?統計が悪いと、実行計画の選択が悪くなる可能性があります。
- 実行計画の不備を引き起こしているパラメータスニッフィングの問題がありますか?
- バッファプールは、たとえば肥大化したプランキャッシュからのメモリプレッシャーにさらされていますか?
- ネットワークの問題はありますか? SANファブリックは正しく機能していますか?ストレージエンジニアにパスとネットワークを検証してもらいます。
- ホットスポットを別のストレージアレイに移動します。場合によっては、すべての問題を引き起こしているのは、単一のデータベースまたは少数のデータベースである可能性があります。それらを別のディスクセット、またはSSDなどのより高速なハイエンドディスクに分離することが、最良の論理ソリューションである可能性があります。
- データベースをパーティション分割して、面倒なテーブルを別のディスクに移動し、負荷を分散させることはできますか?
待機統計
ファイルの統計を監視するのと同じように、待機の統計を監視することで、環境のボトルネックについて多くのことを知ることができます。別の素晴らしいDMV( sys.dm_os_wait_stats )があるのは幸運です )最後の再起動以降、または最後に待機がリセットされてから収集された、利用可能なすべての待機情報をプルするクエリを実行できます。ディスクのパフォーマンスに関連する待機もあります。このDMVは、次のような重要な情報を返します。
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
SQL Server 2014マシンでこのDMVをクエリすると、771の待機タイプが返されました。 SQL Serverは常に何かを待っていますが、心配する必要のない待機がたくさんあります。このため、PaulRandalからの別のクエリを利用します。彼のブログ投稿「WaitStatistics、またはどこが痛いのか教えてください」には、私たちが本当に気にしない多くの待機を除外した優れたスクリプトがあります。 Paulはまた、一般的な問題のある待機の多くをリストし、一般的な待機のガイダンスを提供します。
待機統計が重要なのはなぜですか?
特定のイベントの待ち時間が長いことを監視すると、問題が発生したときに通知されます。何が正常で、いつ物事がしきい値または痛みのレベルを超えるかを知るためのベースラインが必要です。 PAGEIOLATCH_XXが本当に高い場合 そうすれば、SQLServerはデータページがディスクから読み取られるのを待たなければならないことがわかります。これは、ディスク、メモリ、ワークロードの変更、またはその他の多くの問題である可能性があります。
私が一緒に働いていた最近のクライアントは、いくつかの非常に異常な動作を見ていました。データベースサーバーに接続し、作業負荷の下でサーバーを監視できるようになると、すぐにファイル統計、待機統計、メモリ使用率、tempdb使用量などのチェックを開始しました。すぐに目立ったのは WRITELOG 最も一般的な待機です。この待機はディスクへのログフラッシュに関係していることを知っており、トランザクションログファットのトリミングに関するPaulのシリーズを思い出しました。高いWRITELOG 待機は通常、トランザクションログファイルの書き込み待ち時間が長いことで識別できます。そこで、ファイル統計スクリプトを使用して、ディスクの読み取りと書き込みの待機時間を確認しました。その後、データファイルで高い書き込みレイテンシを確認できましたが、ログファイルでは確認できませんでした。 WRITELOGを見ると 待機時間は長くなりましたが、待機時間(ミリ秒)は非常に短かったです。しかし、ポールのシリーズの2番目の投稿の何かがまだ私の頭の中にありました。 「1000カットによる死」を除外するために、データベースの自動拡張設定を確認する必要があります。データベースのデータベースプロパティを見ると、データファイルが1MBずつ自動拡張するように設定されており、トランザクションログが10%自動拡張するように設定されていることがわかりました。どちらのファイルにも、未使用のスペースはほとんどありませんでした。私が見つけたものと、これがどのように彼らのパフォーマンスを殺していたかをクライアントと共有しました。私たちはすぐに適切な変更を加え、テストを進めました。ちなみに、はるかに優れています。悲しいことに、私がこの正確な問題に遭遇したのはこれだけではありません。また、データベースのサイズが66 GBだったときは、1MBの増加でそこに到達しました。
データのキャプチャ
多くのデータ専門家は、ファイルをキャプチャし、分析のために定期的に統計を待機するプロセスを作成しています。待機統計は累積的であるため、それらをキャプチャして、1日の異なる時間間、または特定のプロセスの実行前後のデルタを比較する必要があります。これはそれほど複雑ではなく、人々がこれをどのように達成したかを共有する利用可能な多数のブログ投稿があります。重要なのは、このデータを監視できるように測定することです。昨日のデータを知らない限り、データベースサーバーの状況が良くも悪くも今日はどうやってわかりますか?
SQL Sentryはどのように役立ちますか?
よろしくお願いします! SQL Sentry Performance Advisorはレイテンシーをもたらし、ダッシュボードの前面と中央で待機します。異常は簡単に見つけることができます。履歴モードに切り替えて前のトレンドを確認し、それを前の期間と比較することもできます。これらの「何が起こったのか」を分析するとき、これは貴重であることがわかります。瞬間。 「昨日の午後3時頃、システムがフリーズしたようです。何が起こったのか教えていただけますか?」という電話がありました。ええと、確かに、プロファイラーを引き上げて、時間を遡らせてください。 Performance Advisorのような監視ツールを使用している場合は、その履歴情報をすぐに利用できます。
ダッシュボードのチャートとグラフに加えて、高ディスク待機、高VLFカウント、高CPU、低ページ寿命などの条件に対して組み込みのアラートを使用する機能があります。また、独自のカスタム条件を作成することもでき、SQL Sentryサイトの例またはConditionExchangeを通じて学ぶことができます(Aaron Bertrandがこれについてブログに書いています)。 SQLServerエージェントアラートに関する前回の記事でこれのアラート側に触れました。
Performance Advisorの[ディスクスペース]タブでは、自動拡張設定や高いVLFカウントなどを簡単に確認できます。知っておく必要がありますが、そうでない場合は、1MBまたは10%の自動成長は最適な設定ではありません。これらの値が表示された場合(パフォーマンスアドバイザーがそれらを強調表示します)、適切な調整を行うための時間をすばやくメモしてスケジュールすることができます。合計VLFの表示方法も気に入っています。 VLFが多すぎると、非常に問題になる可能性があります。キンバリーの投稿「トランザクションログVLF–多すぎるか少なすぎるか?」を読む必要があります。まだ行っていない場合。
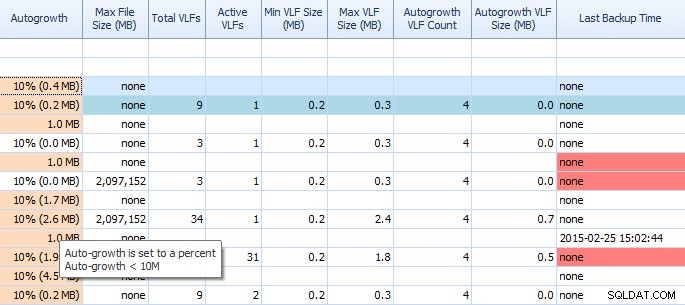 PerformanceAdvisorの[ディスクスペース]タブの部分グリッド
PerformanceAdvisorの[ディスクスペース]タブの部分グリッド
Performance Advisorが支援できるもう1つの方法は、特許を取得したDiskActivityモジュールを使用することです。ここで、F:のtempdbでかなりの書き込み遅延が発生していることがわかります。これは、ディスクグラフィックの下にある太い赤い線でわかります。また、F:がディスクが赤で表されている唯一のドライブ文字であることに気付くかもしれません。これは、ドライブのパーティションがずれていることを視覚的に示しており、I/Oの問題の原因となる可能性があります。
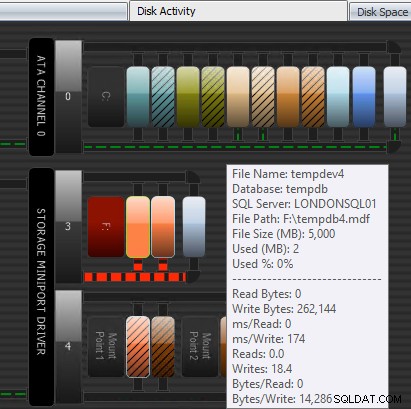
そして、この情報を以下のグリッドで相互に関連付けることができます。問題はそこのグリッドでも強調表示されており、 ms / Writeを確認してください。 列:
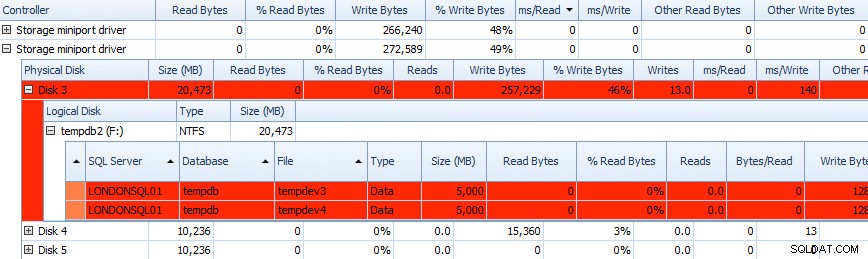 パフォーマンスアドバイザーディスクアクティビティデータの部分グリッド
パフォーマンスアドバイザーディスクアクティビティデータの部分グリッド
この情報をさかのぼって見ることもできます。昨日の午後または先週の火曜日に認識されたディスクのボトルネックについて誰かが不満を言った場合は、ツールバーの日付ピッカーを使用して戻って、任意の範囲の平均スループットと遅延を確認できます。ディスクアクティビティモジュールの詳細については、ユーザーガイドを参照してください。
Performance Advisorには、パフォーマンス、ブロッキング、トップSQL、ディスク/ファイルスペース、およびデッドロックのカテゴリの下に多くの組み込みレポートもあります。以下の画像は、ディスク/ファイルスペースレポートにアクセスする方法を示しています。マウスを数回クリックするだけでレポートを取得できることは、サーバーで何が起こっているか(または何が起こっていたか)をすぐに調べて表示できるため、非常に価値があります。
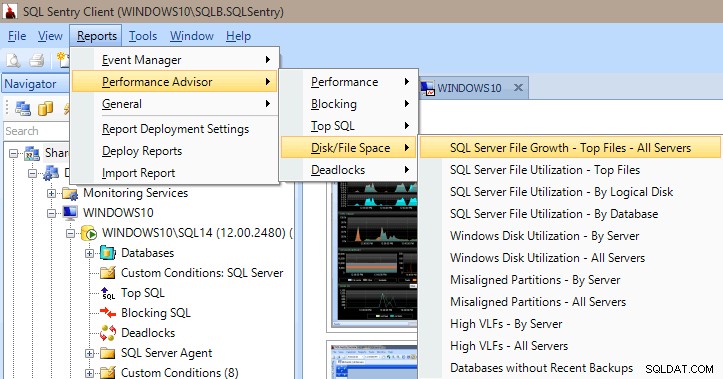
概要
この投稿からの重要なポイントは、パフォーマンスメトリックを知ることです。データの専門家の間でよくある声明は、ディスクが私たちの一番のボトルネックであるということです。サーバーのファイル統計を知ることは、サーバーの問題点を理解するのに大いに役立ちます。ファイル統計と組み合わせて、待機統計も確認するのに最適な場所です。私を含む多くの人々がそこから始めます。 SQL Sentry Performance Advisorのようなツールがあると、問題が発生しすぎる前に、パフォーマンスの問題のトラブルシューティングと発見に大いに役立ちます。ただし、そのようなツールがない場合は、 sys.dm_os_wait_statsに慣れてください。 およびsys.dm_io_virtual_file_stats サーバーの調整を開始するのに役立ちます。