はじめに
開発者は、いわゆるアドホッククエリを回避するために、ストアドプロシージャを使用するように言われることがよくあります。 これにより、プランキャッシュが不必要に肥大化する可能性があります。繰り返し発生するSQLコードの記述に一貫性がない場合、または動的SQLをオンザフライで生成するコードがある場合、SQLServerは個々の実行ごとに実行プランを作成する傾向があります。これにより、全体的なパフォーマンスが低下する可能性があります:
-
コードを実行するたびにコンパイルフェーズを要求します。
-
再利用できない可能性のあるプランハンドルが多すぎるプランキャッシュを肥大化させます。
アドホックワークロードに最適化
過去にこの問題が処理された1つの方法は、アドホックワークロード用にインスタンスを最適化することです。これを行うことは、インスタンス上のほとんどのデータベースまたは最も重要なデータベースが主にアドホックSQLを実行している場合にのみ役立ちます。
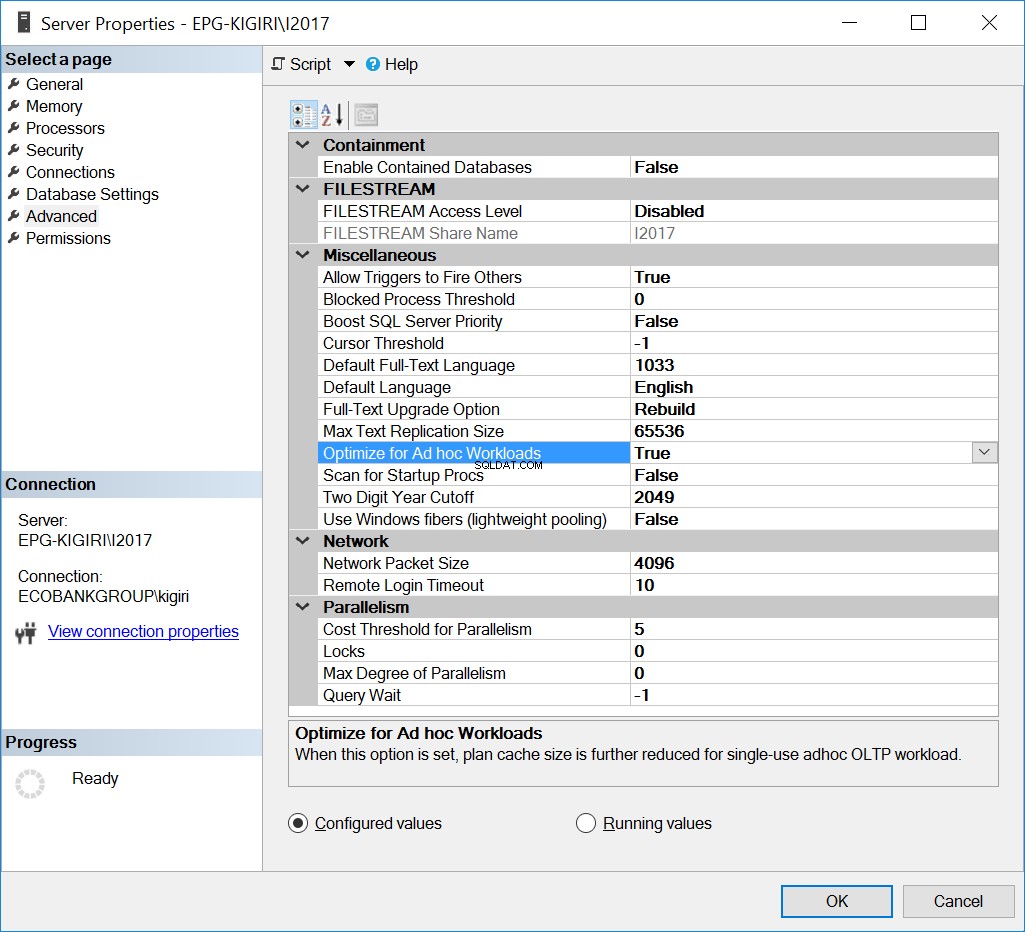
図。 1アドホックワークロード用に最適化
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
基本的に、このオプションは、コンパイル済みプランスタブと呼ばれるプランの部分バージョンを保存するようにSQLServerに指示します。スタブは、プラン全体よりもはるかに少ないスペースを占有します。
この方法の代わりに、かなり残酷に問題に取り組み、時々プランキャッシュをフラッシュする人もいます。または、より慎重に、DBCCFREESYSTEMCACHEを使用して「シングルユースプラン」をフラッシュします。すでにご存知かもしれませんが、プランキャッシュ全体をフラッシュすることには欠点があります。
ストアドプロシージャとパラメータの使用
ストアドプロシージャを使用することで、アドホックSQLによって引き起こされる問題を事実上排除できます。ストアドプロシージャは1回だけコンパイルされ、同じプランが同じまたは類似のSQLクエリの後続の実行に再利用されます。ストアドプロシージャを使用してビジネスロジックを実装する場合、SQL Serverによって最終的に実行されるSQLクエリの主な違いは、実行時に渡されるパラメータにあります。プランはすでに配置されており、使用できる状態になっているため、SQL Serverは、渡されたパラメーターに関係なく同じプランを使用します。
歪んだデータ
特定のシナリオでは、処理しているデータが均等に分散されません。これを実証できます–まず、テーブルを作成する必要があります:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); 私たちの表には、さまざまな国のクラブ会員のデータが含まれています。多くのクラブ会員はガーナ出身ですが、他の2か国にはそれぞれ10人と2人の会員がいます。議事に焦点を合わせ続けるために、そして簡単にするために、私は3つの国だけを使用し、同じ国から来たメンバーには同じ名前を使用しました。また、ID列にクラスター化インデックスを追加し、CountryCode列に非クラスター化インデックスを追加して、さまざまな値に対するさまざまな実行プランの効果を示しました。
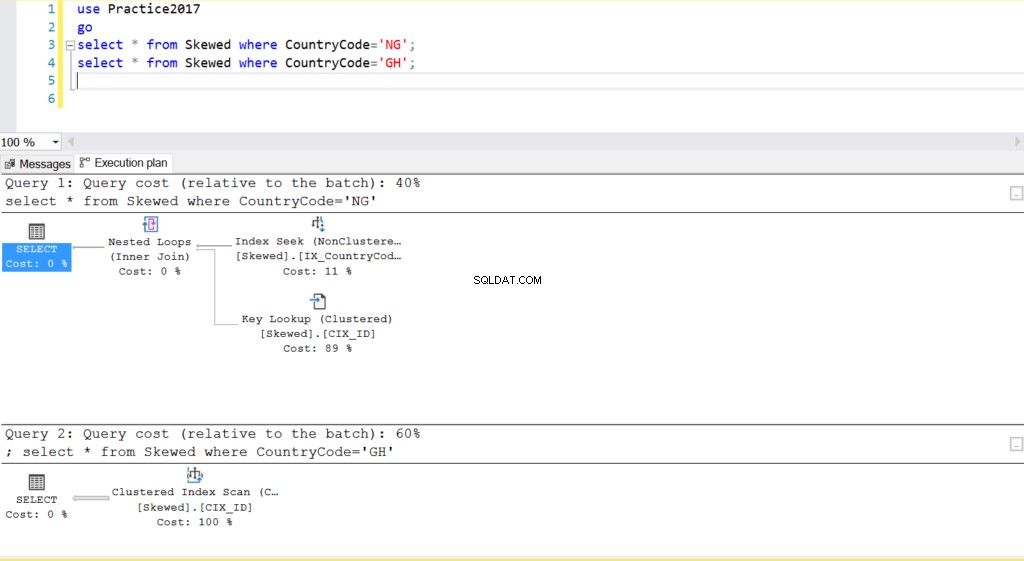
図。 22つのクエリの実行計画
CountryCodeがNGとGHであるレコードをテーブルにクエリすると、SQLServerがこれらの場合に2つの異なる実行プランを使用していることがわかります。これは、CountryCode ='NG'の予想行数が10であり、CountryCode ='GH'の予想行数が10000であるために発生します。SQLServerは、テーブル統計に基づいて適切な実行プランを決定します。予想される行数がテーブル内の行の総数と比較して多い場合、SQL Serverは、インデックスを参照するよりも、単に全表スキャンを実行する方がよいと判断します。推定行数がはるかに少ないと、インデックスが役立ちます。
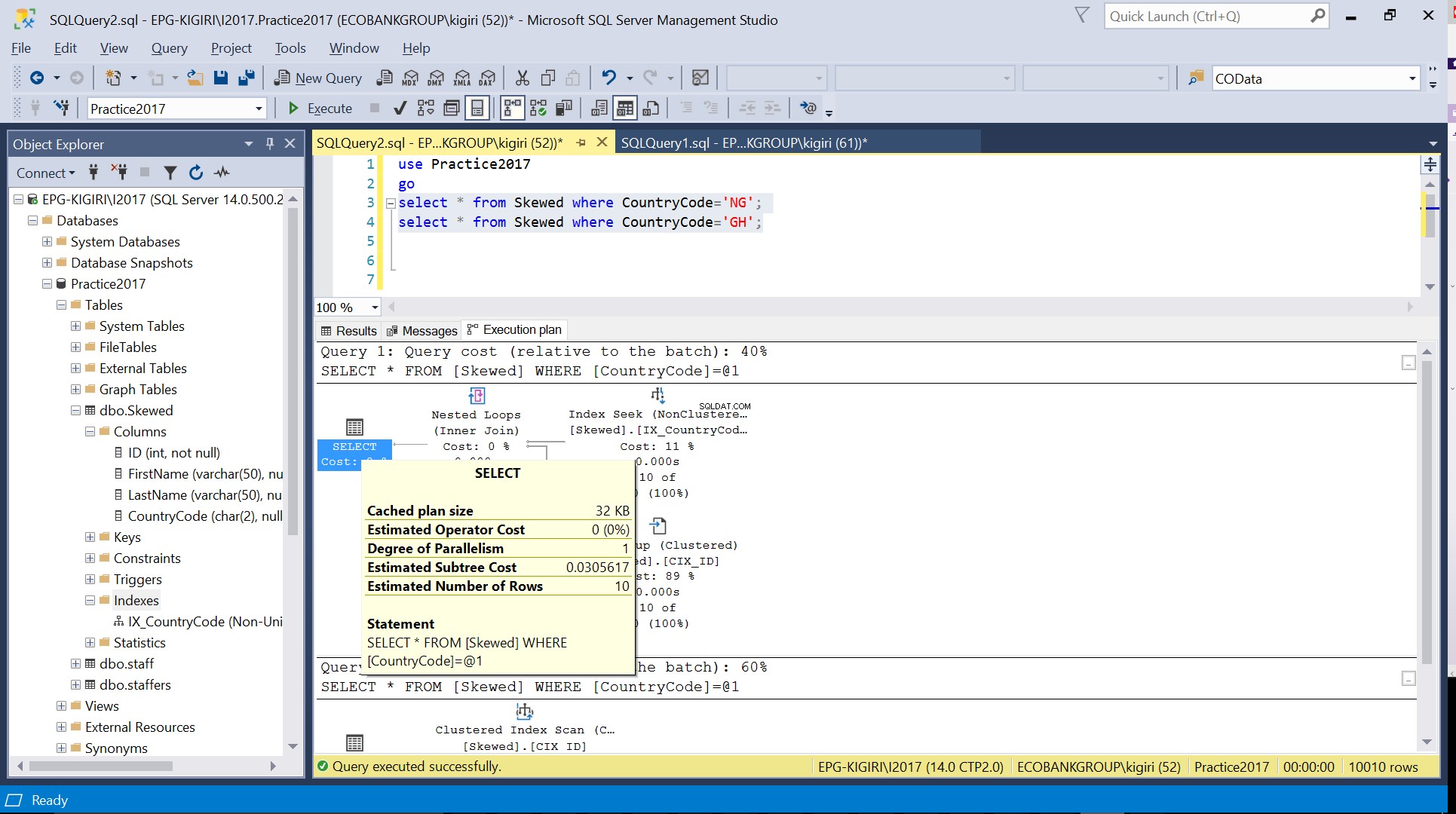
図。 3 CountryCode =’NG’
の推定行数 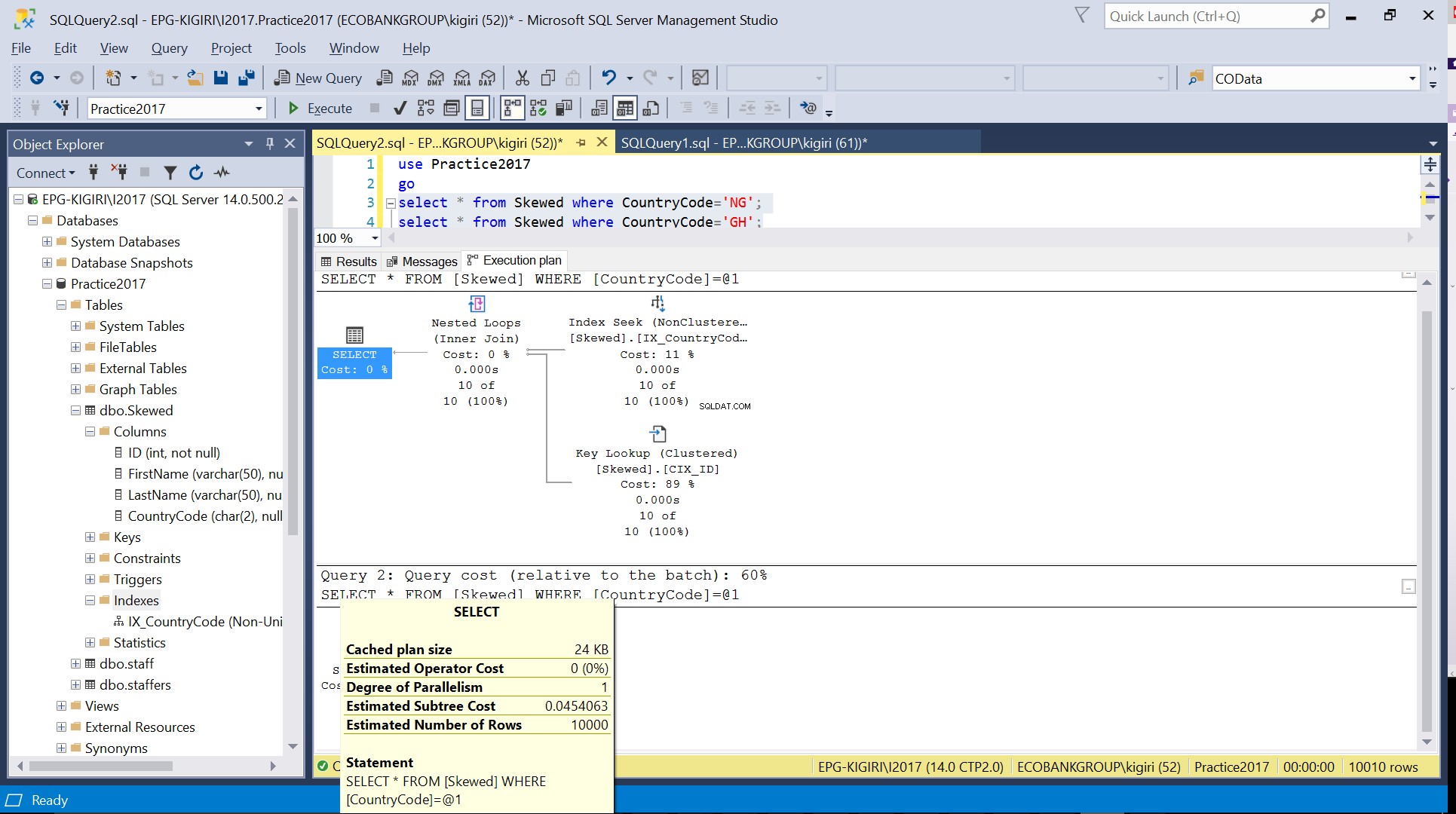
図。 4 CountryCode =’GH’
の推定行数ストアドプロシージャを入力
まったく同じクエリを使用して、必要なレコードをフェッチするストアドプロシージャを作成できます。今回の唯一の違いは、CountryCodeをパラメーターとして渡すことです(リスト3を参照)。これを行うと、どのパラメーターを渡しても実行プランが同じであることがわかります。使用される実行プランは、ストアード・プロシージャーが最初に呼び出されたときに返される実行プランによって決定されます。たとえば、最初にCountryCode =’GH’を使用してプロシージャを実行すると、その時点から全表スキャンが使用されます。次に、プロシージャキャッシュをクリアし、最初にCountryCode =’NG’を使用してプロシージャを実行すると、将来的にインデックスベースのスキャンが使用されます。
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
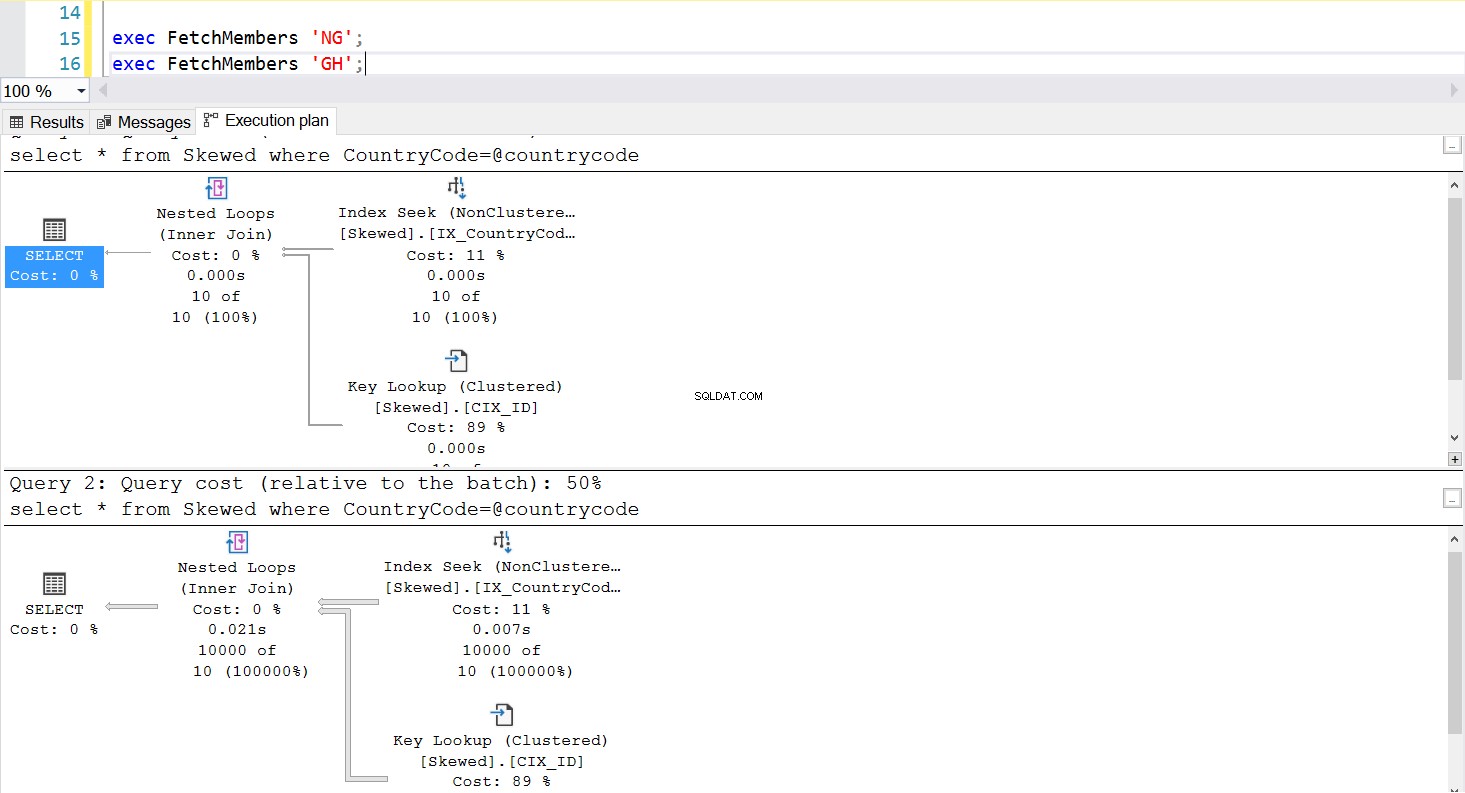
図。 5「NG」を最初に使用した場合のインデックスシーク実行プラン
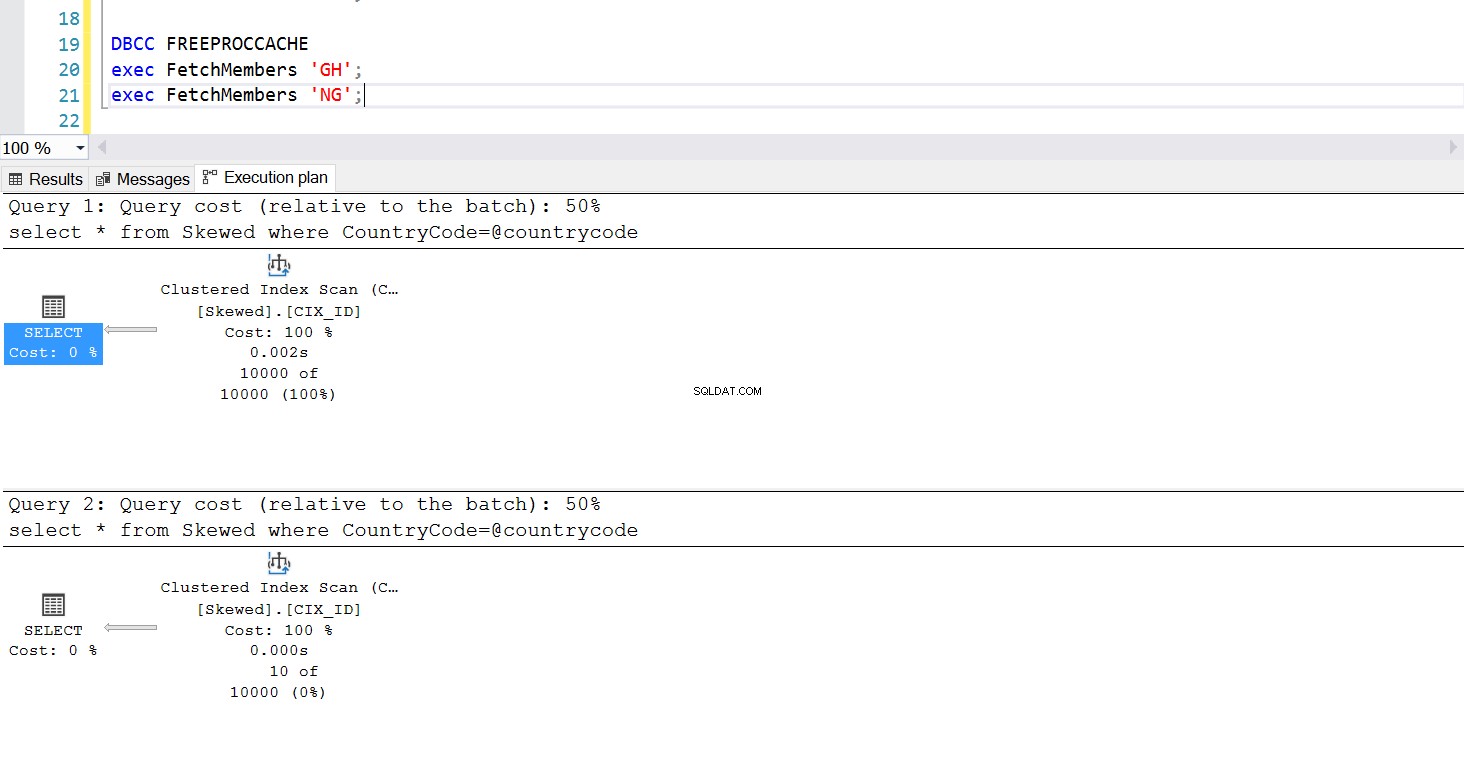
図。 6「GH」を最初に使用した場合のクラスター化インデックススキャンの実行プラン
ストアドプロシージャの実行は設計どおりに動作しています–必要な実行プランが一貫して使用されます。ただし、データが偏っている場合、1つの実行プランがすべてのクエリに適しているわけではないため、これは問題になる可能性があります。インデックスを使用してテーブル全体とほぼ同じ大きさの行のコレクションを取得することは効率的ではありません。また、フルスキャンを使用して少数の行のみを取得することもできません。これはパラメータスニッフィングの問題です。
考えられる解決策
パラメータスニッフィングの問題を管理する一般的な方法の1つは、ストアドプロシージャが実行されるたびに意図的に再コンパイルを呼び出すことです。これは、プランキャッシュをフラッシュするよりもはるかに優れています。ただし、この特定のSQLクエリのキャッシュをフラッシュする場合を除きます。これは完全に可能です。ストアドプロシージャの更新バージョンを見てください。今回は、OPTION(RECOMPILE)を使用して問題を管理します。図6は、新しいストアドプロシージャが実行されるたびに、渡すパラメータに適したプランを使用することを示しています。
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
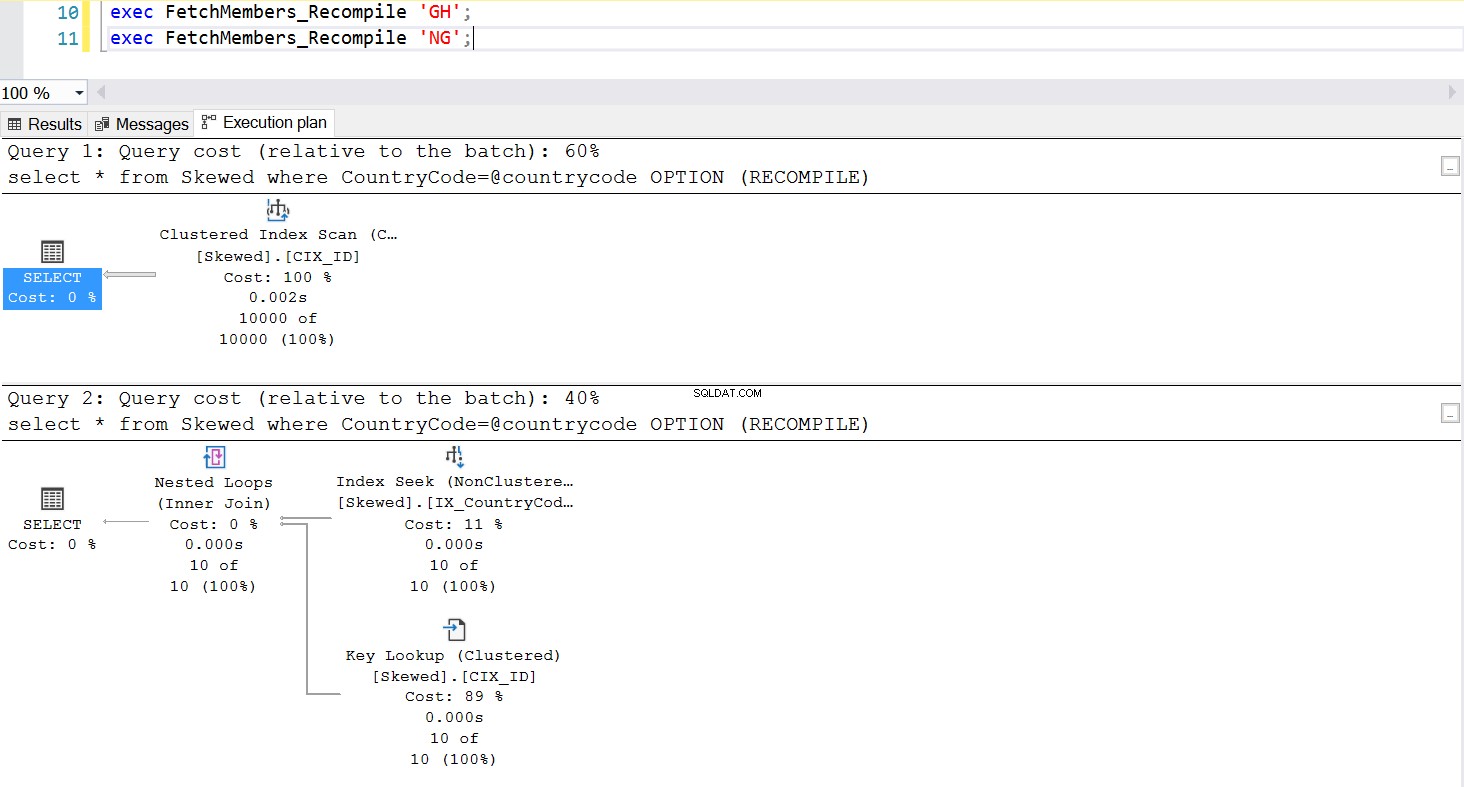
図。 7 OPTION(RECOMPILE)を使用したストアドプロシージャの動作
結論
この記事では、処理するデータが歪んでいる場合に、ストアドプロシージャの一貫した実行計画がどのように問題になるかを見てきました。また、これを実際に示し、問題の一般的な解決策について学びました。この知識は、SQLServerを使用する開発者にとって非常に貴重だと思います。この問題には他にも多くの解決策があります。ブレントオザルはこのテーマをさらに深く掘り下げ、SQLDayポーランド2017でいくつかのより深い詳細と解決策を強調しました。対応するリンクを参照セクションにリストしました。
参照
キャッシュの計画とアドホックワークロードの最適化
パラメータスニッフィングの問題の特定と修正