文字列の解析は好きですか?その場合、使用する必要のある文字列関数の1つはSQLSUBSTRINGです。これは、開発者があらゆる言語に対して持つべきスキルの1つです。
それで、どうやってそれをしますか?
文字列解析の重要なポイント
構文解析に不慣れであると想定します。覚えておく必要のある重要なポイントは何ですか?
- 文字列に埋め込まれている情報を把握します。
- 文字列内の各情報の正確な位置を取得します。文字列内のすべての文字を数える必要がある場合があります。
- 文字列内の各情報のサイズまたは長さを把握します。
- 文字列内の各情報を簡単に抽出できる適切な文字列関数を使用します。
これらすべての要因を知っていると、SQL SUBSTRING()を使用して引数を渡す準備が整います。
SQLSUBSTRING構文

SQLSUBSTRINGの構文は次のとおりです。
SUBSTRING(文字列式、開始、長さ)
- 文字列式– a リテラル文字列または文字列を返すSQL式。
- 開始 –抽出が開始される番号。また、1ベースです。文字列式引数の最初の文字は0ではなく1で始まる必要があります。SQLServerでは、常に正の数です。ただし、MySQLまたはOracleでは、正または負の場合があります。負の場合、スキャンは文字列の末尾から開始されます。
- 長さ –抽出する文字の長さ。 SQLServerはそれを必要とします。 MySQLまたはOracleでは、これはオプションです。
4SQLSUBSTRINGの例
1。 SQLSUBSTRINGを使用してリテラル文字列から抽出する
リテラル文字列を使用した簡単な例から始めましょう。韓国の有名なガールグループBlackPinkの名前を使用しています。図1は、SUBSTRINGがどのように機能するかを示しています。

以下のコードは、それを抽出する方法を示しています:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
次に、図2の結果セットも調べてみましょう。
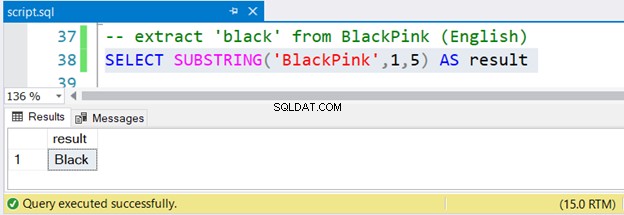
簡単じゃないですか?
黒を抽出するには BlackPinkから 、位置1から開始し、位置5で終了します。 BlackPink 以降 は韓国語です。SUBSTRINGがUnicode韓国語文字で機能するかどうかを調べてみましょう。
(免責事項 :私は韓国語を話したり、読んだり、書いたりすることができないので、ウィキペディアから韓国語の翻訳を入手しました。また、Google翻訳を使用して、どの文字が黒に対応するかを確認しました。 およびピンク 。間違っていたら許してください。それでも、私が明確にしようとしているポイントが来ることを願っています і全体)
韓国語の文字列を取得しましょう(図3を参照)。使用されている韓国語の文字はBlackPinkに翻訳されます:

次に、以下のコードを参照してください。 黒に対応する2文字を抽出します 。
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Nが前に付いた韓国語の文字列に気づきましたか ? Unicode文字を使用し、SQL ServerはNVARCHARを想定しているため、前に Nを付ける必要があります。 。これが英語版の唯一の違いです。しかし、それはうまく動作しますか?図4を参照してください:
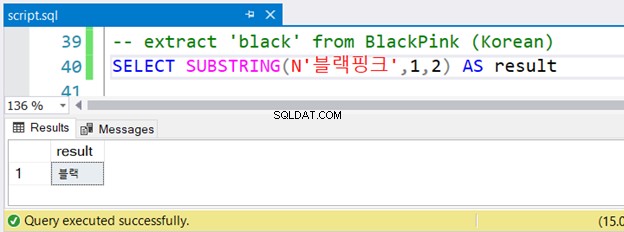
エラーなしで実行されました。
2。負の開始引数を使用したMySQLでのSQLSUBSTRINGの使用
負の開始引数を指定しても、SQLServerでは機能しません。しかし、MySQLを使用してこの例を示すことができます。今回は、ピンクを抽出しましょう BlackPinkから 。コードは次のとおりです:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
それでは、結果を図5に示しましょう:
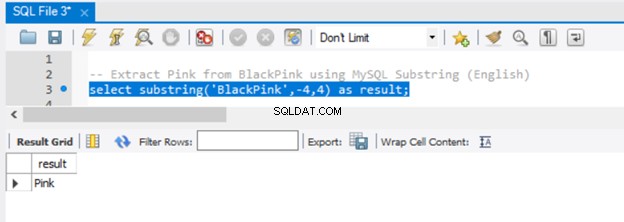
startパラメーターに-4を渡したため、抽出は文字列の末尾から開始され、4文字逆になります。 SQL Serverで同じ結果を得るには、RIGHT()関数を使用します。
図6に示すように、Unicode文字はMySQLSUBSTRINGでも機能します。
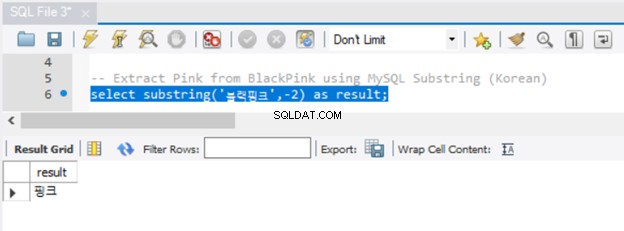
それはうまくいきました。しかし、文字列の前にNを付ける必要がないことに気づきましたか?また、MySQLでサブストリングを取得する方法はいくつかあることに注意してください。すでにSUBSTRINGを見てきました。 MySQLの同等の関数は、SUBSTR()とMID()です。
3。可変の開始引数と長さ引数を使用した部分文字列の解析
残念ながら、すべての文字列抽出で固定の開始引数と長さ引数が使用されるわけではありません。このような場合、ターゲットとする文字列の位置を取得するには、CHARINDEXが必要です。例を見てみましょう:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
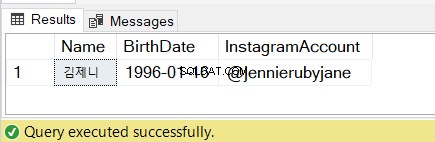
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
上記のコードでは、韓国語の名前、生年月日、Instagramアカウントを抽出する必要があります。
まず、これらの情報を保持するための3つの変数を定義します。その後、文字列を解析して、結果を各変数に割り当てることができます。
開始点と長さを固定する方が簡単だと思うかもしれません。また、手動で文字数を数えることで特定できます。しかし、テーブルにこれらがたくさんある場合はどうなりますか?
分析は次のとおりです。
- 文字列内の唯一の固定項目は@です Instagramアカウントのキャラクター。 CHARINDEXを使用して、文字列内の位置を取得できます。次に、その位置を使用して、残りの開始と長さを取得します。
- 生年月日は、10文字のMM / dd/yyyyを使用した固定形式です。
- 名前を抽出するには、1から始めます。誕生日には10文字と、 @が含まれているためです。 文字、文字列内の名前の最後の文字に到達することができます。 @の位置から 文字、11文字戻ります。 SUBSTRING(@ lineString、1、CHARINDEX(‘@’、@ lineString)-11) 行く方法です。
- 誕生日を取得するには、同じロジックを適用します。 @の位置を取得します 文字を入力し、10文字後方に移動して、誕生日の開始値を取得します。 10は固定長です。 SUBSTRING(@ lineString、CHARINDEX(‘@’、@ lineString)-10,10) 誕生日を取得する方法です。
- 最後に、Instagramアカウントを取得するのは簡単です。 @の位置から開始します CHARINDEXを使用した文字。注:30はInstagramのユーザー名の制限です。
図7の結果を確認してください:
4。 SELECTステートメントでのSQLSUBSTRINGの使用
SELECTステートメントでSUBSTRINGを使用することもできますが、最初に、作業データが必要です。コードは次のとおりです:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
上記のコードは、名前、電子メールアドレス、都市、および郵便番号を含む長い文字列を作成します。 PersonContactsにも保存します テーブル。
それでは、SUBSTRINGを使用してリバースエンジニアリングするコードを作成しましょう:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
固定サイズの列を使用したため、CHARINDEXを使用する必要はありません。
WHERE句でSQLSUBSTRINGを使用する–パフォーマンストラップ?
それは本当です。 WHERE句でSUBSTRINGを使用するのを止めることはできません。これは有効な構文です。しかし、それがパフォーマンスの問題を引き起こす場合はどうなりますか?
そのため、例を使用してそれを証明し、この問題を修正する方法について説明します。ただし、最初にデータを準備しましょう:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
SalesOrderHeaderを台無しにすることはできません テーブルなので、別のテーブルにダンプしました。次に、 SalesOrderIDを作成しました 新しいSalesOrders 主キーをテーブルします。
これで、クエリの準備が整いました。 dbForge Studio for SQLServerを使用しています クエリプロファイリングモードがオンの場合 クエリを分析します。
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
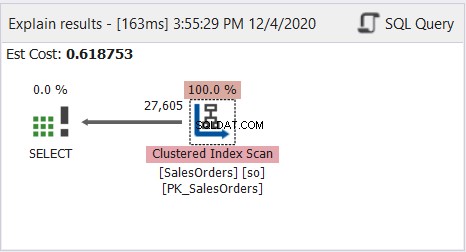
ご覧のとおり、上記のクエリは正常に実行されます。次に、図8のクエリプロファイル計画図を見てください。
平面図は単純に見えますが、クラスター化インデックススキャンノードのプロパティを調べてみましょう。特に、ランタイム情報が必要です:
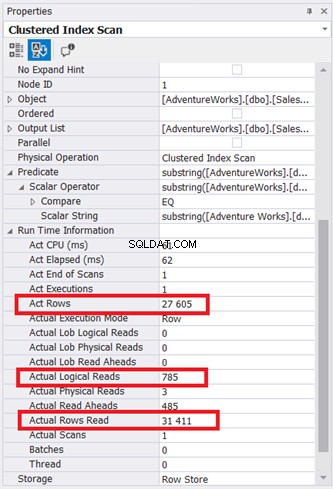
図9は、データベースエンジンによって読み取られた785*8KBページを示しています。また、実際に読み取られた行が31,411であることに注意してください。これは、テーブル内の行の総数です。ただし、クエリは27,605の実際の行しか返しませんでした。
クラスター化されたインデックスを参照として使用して、テーブル全体が読み取られました。
なぜですか?
重要なのは、SQLServerは 4030かどうかを知る必要があるということです。 アカウント番号のサブストリングです。各レコードを読み取って評価する必要があります。等しくない行を破棄し、必要な行を返します。それは仕事を成し遂げますが、十分な速さではありません。
実行速度を上げるために何ができるでしょうか?
WHERE句でSUBSTRINGを避け、同じ結果をより早く達成する
ここで必要なのは、WHERE句でSUBSTRINGを使用せずに同じ結果を取得することです。以下の手順に従ってください:
- 計算列を追加してテーブルを変更します SUBSTRING(AccountNumber、4,4) 方式。 AccountCategoryという名前を付けましょう より良い用語がないため。
- 新しいAccountCategoryの非クラスター化インデックスを作成します 桁。 OrderDateを含める 、 AccountNumber 、および CustomerID 列。
それだけです。
新しいAccountCategoryを適応させるために、クエリのWHERE句を変更します 列:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
WHERE句にSUBSTRINGはありません。それでは、計画図を確認しましょう:
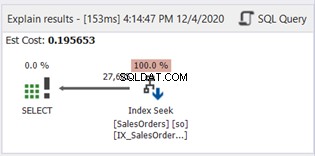
インデックススキャンはインデックスシークに置き換えられました。 SQLServerが計算列に新しいインデックスを使用したことにも注意してください。論理読み取りと実際の行の読み取りにも変更がありますか?図11を参照してください:
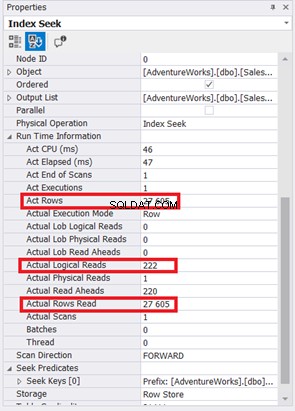
785から222の論理読み取りを減らすことは、元の論理読み取りの3分の1を超える、大幅な改善です。また、実際の行の読み取りを必要な行のみに最小化しました。
したがって、WHERE句でSUBSTRINGを使用することはパフォーマンスに良くなく、WHERE句で使用される他のスカラー値関数にも当てはまります。
結論
- 開発者は文字列の解析を避けられません。その必要性は何らかの形で発生します。
- 文字列を解析する際には、文字列内の情報、各情報の位置、およびそれらのサイズや長さを知ることが不可欠です。
- 解析関数の1つはSQLSUBSTRINGです。解析する文字列、抽出を開始する位置、および抽出する文字列の長さのみが必要です。
- SUBSTRINGは、SQL Server、MySQL、OracleなどのSQLフレーバー間で異なる動作をする可能性があります。
- リテラル文字列およびテーブル列の文字列でSUBSTRINGを使用できます。
- Unicode文字でSUBSTRINGも使用しました。
- WHERE句でSUBSTRINGまたは任意のスカラー値関数を使用すると、クエリのパフォーマンスが低下する可能性があります。インデックス付きの計算列でこれを修正します。
この投稿が役に立った場合は、お好みのソーシャルメディアプラットフォームで共有するか、以下のコメントを共有してください。