おそらく、単一または複数のVALUES句を使用してレコードをテーブルに挿入する方法を知っているでしょう。また、SQL INSERTINTOSELECTを使用して一括挿入を行う方法も知っています。しかし、あなたはまだ記事をクリックしました。重複の処理についてですか?
多くの記事がSQLINSERTINTOSELECTをカバーしています。 GoogleまたはBingを使用して、最も気に入った見出しを選択してください。それがどのように行われるかの基本的な例についても説明しません。代わりに、使用方法と重複の処理方法の例が表示されます。 。したがって、INSERTの取り組みからこのおなじみのメッセージを作成できます。
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
しかし、まず最初に。

[sendpulse-form id =” 12989”]
SQL INSERTINTOSELECTコードサンプルのテストデータを準備する
今回はパスタのことを考えています。そこで、パスタ料理のデータを使用します。ウィキペディアで、Webデータソースを使用してPower BIで使用および抽出できる、パスタ料理の優れたリストを見つけました。ウィキペディアのURLを入力しました。次に、ページから2テーブルのデータを指定しました。少しクリーンアップして、データをExcelにコピーしました。
これでデータができました–ここからダウンロードできます。これから2つのリレーショナルテーブルを作成するため、生です。 INSERT INTO SELECTを使用すると、このタスクを実行するのに役立ちます。
SQLServerにデータをインポートする
SQL ServerManagementStudioまたはdbForgeStudiofor SQL Serverのいずれかを使用して、2枚のシートをExcelファイルにインポートできます。
データをインポートする前に、空のデータベースを作成してください。テーブルにdbo.ItalianPastaDishesという名前を付けました およびdbo.NonItalianPastaDishes 。
さらに2つのテーブルを作成
コマンドSQLServerALTERTABLEを使用して2つの出力テーブルを定義しましょう。
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
注:2つのテーブルに作成された一意のインデックスがあります。後で重複レコードを挿入するのを防ぎます。制限があると、この旅は少し難しくなりますが、わくわくします。
準備ができたので、詳しく見ていきましょう。
SQL INSERTINTOSELECTを使用して重複を処理する5つの簡単な方法
重複を処理する最も簡単な方法は、一意の制約を削除することですよね?
間違っています!
固有の制約がなくなると、間違いを犯してデータを2回以上挿入するのが簡単になります。私たちはそれを望んでいません。また、パスタ料理の出所を選択するためのドロップダウンリストを備えたユーザーインターフェイスがある場合はどうなりますか?複製はユーザーを幸せにしますか?
したがって、一意の制約を削除することは、SQLで重複レコードを処理または削除する5つの方法の1つではありません。より良い選択肢があります。
1。 INSERT INTOSELECTDISTINCTの使用
SQLでSQLレコードを識別する方法の最初のオプションは、SELECTでDISTINCTを使用することです。ケースを調査するために、 Originにデータを入力します テーブル。しかし、最初に、間違った方法を使用しましょう:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
これにより、次の重複エラーが発生します:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
SQLで重複する行を選択しようとすると問題が発生します。以前に存在した重複のSQLチェックを開始するために、INSERTINTOSELECTステートメントのSELECT部分を実行しました。
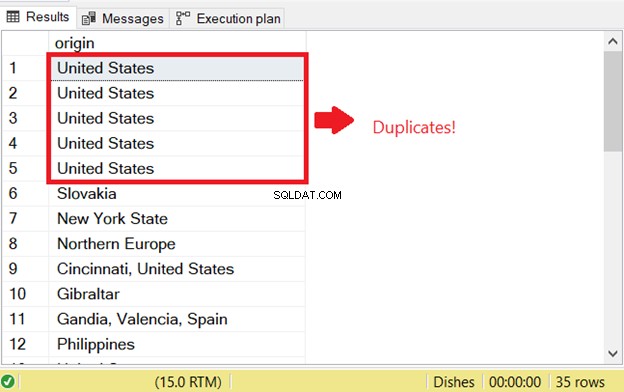
これが、最初のSQL重複エラーの理由です。これを防ぐには、DISTINCTキーワードを追加して、結果セットを一意にします。正しいコードは次のとおりです:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
レコードが正常に挿入されます。そして、 Originは完了です。 テーブル。
DISTINCTを使用すると、SELECTステートメントから一意のレコードが作成されます。ただし、ターゲットテーブルに重複が存在しないことを保証するものではありません。ターゲットテーブルに挿入したい値が含まれていないことが確実な場合に適しています。
したがって、これらのステートメントを複数回実行しないでください。
2。 WHERENOTINを使用する
次に、 PastaDishesにデータを入力します テーブル。そのためには、最初に ItalianPastaDishesからレコードを挿入する必要があります テーブル。コードは次のとおりです:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
ItalianPastaDishes以降 生データが含まれているため、 Originに参加する必要があります OriginIDの代わりにテキスト 。ここで、同じコードを2回実行してみます。 2回目の実行では、レコードは挿入されません。これは、NOTIN演算子を使用したWHERE句が原因で発生します。ターゲットテーブルにすでに存在するレコードを除外します。
次に、 PastaDishesにデータを入力する必要があります NonItalianPastaDishesのテーブル テーブル。この投稿の2番目のポイントにすぎないため、すべてを挿入することはしません。
アメリカとフィリピンのパスタ料理を選びました。
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
このステートメントから挿入された9つのレコードがあります–以下の図2を参照してください:
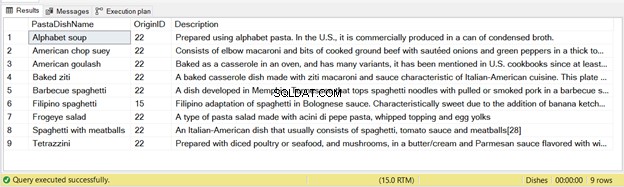
繰り返しになりますが、上記のコードを2回実行すると、2回目の実行ではレコードが挿入されません。
3。 WHERE NOT EXISTS
の使用SQLで重複を見つける別の方法は、WHERE句でNOTEXISTSを使用することです。前のセクションと同じ条件で試してみましょう:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
上記のコードは、図2で見たのと同じ9つのレコードを挿入します。同じレコードを複数回挿入することを回避します。
4。 IF NOT EXISTS
の使用場合によっては、データベースにテーブルをデプロイする必要があり、重複を避けるために同じ名前のテーブルがすでに存在するかどうかを確認する必要があります。この場合、SQL DROP TABLEIFEXISTSコマンドが非常に役立ちます。重複を挿入しないようにするもう1つの方法は、IFNOTEXISTSを使用することです。ここでも、前のセクションと同じ条件を使用します。
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
上記のコードは、最初に9つのレコードの存在をチェックします。 trueが返された場合、INSERTが続行されます。
5。 COUNT(*)=0を使用する
最後に、WHERE句でCOUNT(*)を使用すると、重複を挿入しないようにすることもできます。次に例を示します:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
重複を避けるために、上記のサブクエリによって返されるCOUNTまたはレコードはゼロである必要があります。
注 :dbForge Studio for SQL Serverのクエリビルダー機能を使用して、ダイアグラム内の任意のクエリを視覚的に設計できます。
SQL INSERTINTOSELECTを使用して重複を処理するさまざまな方法を比較する
4つのセクションでは、SELECTステートメントを使用してバルクレコードを挿入するために、同じ出力を使用しましたが、アプローチが異なります。違いは表面的なものなのかと思うかもしれません。 STATISTICS IOからの論理読み取りをチェックして、それらの違いを確認できます。
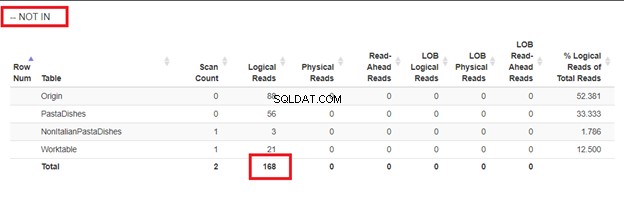
WHERE NOT INの使用:
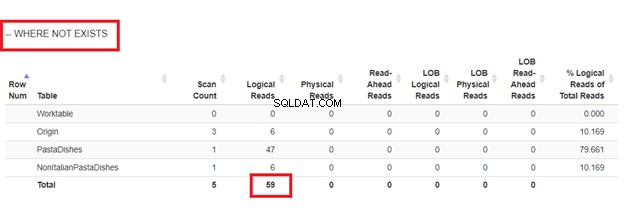
NOT EXISTSの使用:
IF NOT EXISTSの使用:
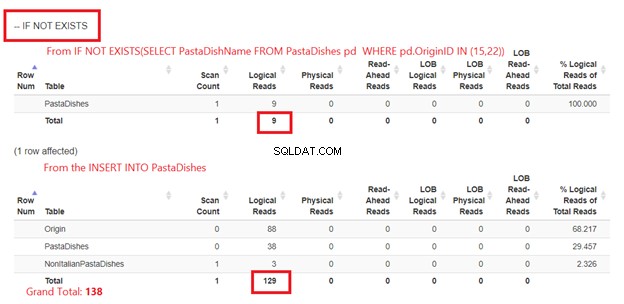
図5は少し異なります。 PastaDishesに対して2つの論理読み取りが表示されます テーブル。 1つ目は、IF NOT EXISTS(SELECT PastaDishName )からのものです。 PastaDishesから WHERE OriginID IN(15,22))。 2つ目はINSERTステートメントからのものです。
最後に、COUNT(*)=0
を使用します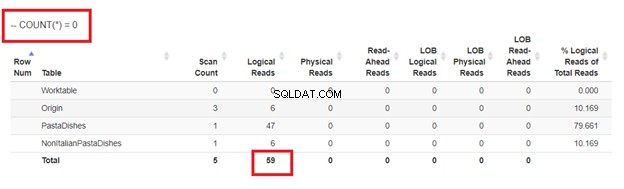
私たちが持っていた4つのアプローチの論理的な読み取りから、最良の選択はWHERE NOT EXISTSまたはCOUNT(*)=0です。実行計画を調べると、同じ QueryHashPlanがあることがわかります。 。したがって、彼らは同様の計画を持っています。一方、最も効率の悪いものはNOTINを使用しています。
それは、WHERE NOTEXISTESがNOTINよりも常に優れていることを意味しますか?まったくありません。
クエリの論理読み取りと実行プランを常に検査してください。
しかし、結論を出す前に、手元のタスクを完了する必要があります。次に、残りのレコードを挿入して結果を調べます。
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
アジアからヨーロッパまでの179のパスタ料理のリストから閲覧すると、私は空腹になります。イタリア、ロシアなどのリストの一部を以下からチェックしてください:

結論
SQL INSERT INTO SELECTで重複を回避することは、結局のところそれほど難しいことではありません。そのレベルに到達するための演算子と関数が手元にあります。実行プランと論理読み取りをチェックして、どちらが優れているかを比較することも良い習慣です。
他の誰かがこの投稿から利益を得ると思う場合は、お気に入りのソーシャルメディアプラットフォームで共有してください。また、忘れてしまったことを追加したい場合は、下のコメントセクションでお知らせください。