給与データモデルを使用すると、従業員の給与を簡単に計算できます。このモデルはどのように機能しますか?
小規模または大規模の会社を経営している場合でも、何らかの給与ソリューションが必要です。そこで、給与計算アプリケーションが役に立ちます。さらに、会社が大きくなるほど、従業員の給与計算を処理するのが難しくなります。ここでは、給与申請が必要になります。このようなアプリケーションに必要なすべてのデータを理解しやすくするために、関連するデータモデルについて説明します。
給与データモデルがどのように機能するか見てみましょう!
データモデル
このデータモデルを作成することで、私はすべてのビジネスに一般的に適用できるモデルを作成しようとしました。もちろん、規制や会社の方針などには常に違いがあり、特定の給与のニーズに合わせてモデルをカスタマイズする必要があります。ただし、このモデルに示されている原則は、ほとんどの組織に関連しているはずです。
このモデルはいくつかの仮定で作成されていることに注意する必要があります。
- 雇用契約で合意された給与は年俸です。
- 正味給与(つまり、税金などから一定額が差し引かれます)が従業員に支払われます。
- 給与は毎月支払われます。
データモデルは14のテーブルで構成され、2つのサブジェクト領域に分割されています。
EmployeesSalaries
モデルをよりよく理解するには、各サブジェクト領域を徹底的に調べる必要があります。
従業員
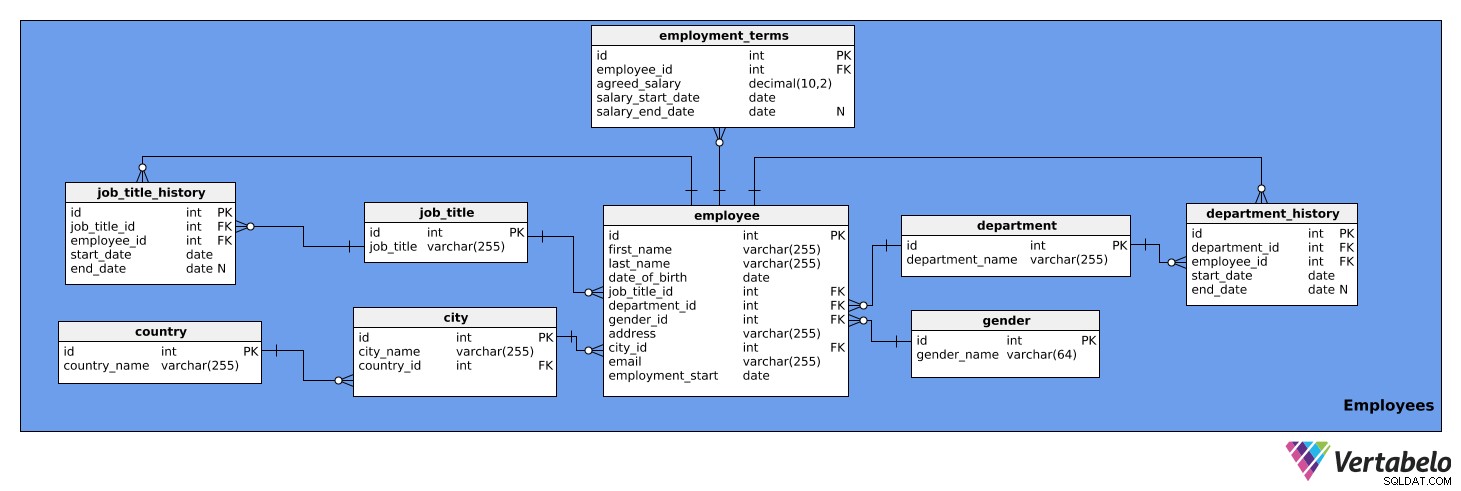
このサブジェクトエリアには、従業員に関する詳細情報が含まれています。 9つのテーブルで構成されています:
Employees-
employment_terms -
job_title -
job_title_history department-
department_history citycountrygender
最初に確認するテーブルは、employee テーブル。これには、すべての従業員とその関連する詳細のリストが含まれています。テーブルの属性は次のとおりです。
-
id–各従業員の一意のID。 -
first_name–従業員の名。 -
last_name–従業員の姓。 -
job_title_id–job_titleテーブル。 -
department_id–departmentテーブル。 -
gender_id–genderテーブル。 address–従業員の住所。-
city_id–cityテーブル。 email–従業員の電子メール。-
employment_start–この人の雇用が開始された日付。
列job_title_idに注意してください およびdepartment_id job_title_history およびdepartment_history テーブル。ただし、情報にすばやくアクセスできるように、これら2つの列をこのテーブルに保持します。
以下はemployment_terms テーブル。雇用契約で合意された各従業員の給与に関するデータと、時間の経過とともにどのように変化したかに関するデータが保存されます。テーブルの属性は次のとおりです。
-
id–雇用条件の各セットの一意のID。 -
employee_id–employeeテーブル。 -
agreed_salary–雇用契約に記載されている給与。 -
salary_start_date–合意された給与の開始日。 -
salary_end_date–合意された給与の終了日。給与に計画的な変更がない可能性があるため、これはNULLになる可能性があります。
job_title 表は、さまざまな会社の従業員に割り当てることができる役職のリストです。アナリスト、ドライバー、秘書、ディレクターなど。テーブルには次の属性があります。
-
id–各役職の一意のID。 -
job_title–役職の名前。これは代替キーです。
また、各従業員の役職履歴を保存するためのテーブルも必要です。従業員は社内で昇進、降格、または再配置できるため、これが必要です。 job_title_history テーブルはこの情報を管理し、次の属性で構成されます:
-
id–役職履歴エントリの一意のID。 -
job_title_id–job_titleテーブル。 -
employee_id–employeeテーブル。 -
start_date–従業員が最初にその役職に就いた日付。 -
end_date–従業員がその役職をやめたとき。従業員が現在その役職を保持している可能性があるため、これはNULLになる可能性があります。
job_title_idの組み合わせ 、employee_id 、およびstart_date 上記の表の代替キーです。従業員は、特定の日付に1つの役職のみを割り当てることができます。
次の表はdepartment テーブル。これにより、IT、経理、法務など、会社のすべての部門が一覧表示されます。これには、次の2つの属性が含まれます。
-
id–各部門の一意のID。 -
department_name–各部門の名前。これは代替キーです。
従業員は社内の部門を変更することもできます。したがって、department_history テーブル。このテーブルには、次のものが格納されます。
-
id–その部門の履歴エントリの一意のID。 -
department_id–departmentテーブル。 -
employee_id–employeeテーブル。 -
start_date–従業員が部門で働き始めた日付。 -
end_date-従業員がその部門での作業を停止した日付。従業員はまだそこで働いている可能性があるため、これはNULLになる可能性があります。
department_idの組み合わせ 、employee_id 、およびstart_date 代替キーです。従業員は一度に1つの部門でしか働くことができません。
次に説明する表は、city テーブル。これは、関連するすべての都市のリストです。次の属性があります:
-
id–各都市の一意のID。 -
city_name–都市の名前。 -
country_id–countryテーブル。
country 次のモデルはテーブルです。これは単なる国のリストであり、次の情報が含まれています。
-
id–すべての国の一意のID。 -
country_name–国の名前。これは代替キーです。
このサブジェクトエリアの最後のテーブルはgender テーブル。この表には、すべての性別がリストされています。次の属性が含まれています:
-
id–すべての性別の一意のID。 gender_name–性別の名前。
次に、2番目の主題領域を分析しましょう。
給与
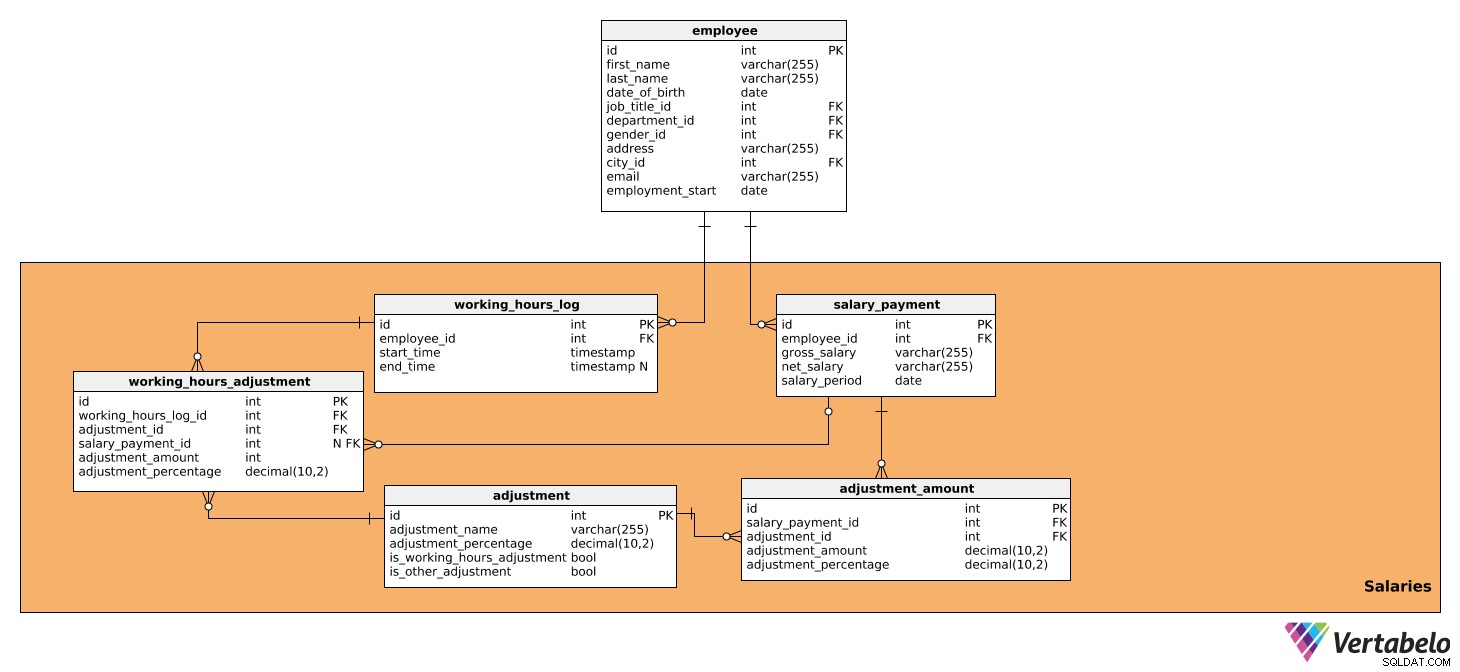
このサブジェクト領域は、すべての期間の給与計算に直接影響するすべてのデータと、支払われる金額を含むテーブルで構成されています。 5つのテーブルで構成されています:
-
salary_payment -
working_hours_log -
working_hours_adjustment adjustment-
adjustment_amount
次に、各テーブルを見てみましょう。
最初のテーブルはsalary_payment 。これには、各従業員に支払われる給与に関連するすべての詳細が含まれ、次の属性があります。
-
id–各給与の一意のID。 -
employee_id–employeeテーブル。 -
gross_salary–さらなる調整の基礎となる総給与。 -
net_salary–正味給与(つまり、さまざまな控除が行われた後に従業員が受け取った金額)。 -
salary_period–給与が計算されて支払われる期間。
2番目はworking_hours_log テーブル。これには、特定の給与調整に影響を与える可能性のある、各従業員の労働時間数に関するデータが含まれています。このテーブルには次の属性があります。
-
id–すべてのログエントリの一意のID。 -
employee_id–employeeテーブル。 -
start_time–従業員がログインした時間、つまりその日の仕事を開始した時間。 -
end_time–従業員がログアウトしたとき。従業員がログアウトするまで正確な時刻がわからないため、NULLになる可能性があります。
次に分析するテーブルは、working_hours_adjustment 。このテーブルは、作業時間に基づく調整の計算でのみ使用されます。つまり、is_working_hours_adjustmentにTRUE値がある場合にのみ使用されます。 adjustment テーブル。属性は次のとおりです。
-
id–調整ごとに一意のID。 -
working_hours_log_id–working_hours_logテーブル。 -
adjustment_id-adjustmentテーブル。 -
salary_payment_id–salary_paymentテーブル。salary_payment_idであるため、この値はNULLになる可能性があります 給与計算を開始するときに、月に1回だけ使用されます。 -
adjustment_amount–調整額。 -
adjustment_percentage–調整のパーセンテージ量。パーセンテージは時間の経過とともに変化する可能性があるため、これは履歴目的で使用されます。
次の表は、adjustment テーブル。これには、給与計算に使用されるすべての調整に関する情報が含まれています。つまり、給与額に影響を与えるすべての税金と拠出金が含まれています。また、ボーナス、残業、病気休暇、産休/育児休暇など、勤務時間と勤務時間に応じたすべての調整が含まれます。そのためには、次のデータが必要です。
-
id–各調整の一意のID。 adjustment_name–その調整を説明する名前。-
adjustment_percentage–特定の調整のパーセンテージ量。 -
is_working_hours_adjustment–これは、調整が労働時間に直接依存する場合のフラグマークです。残業、病気休暇など。 -
is_other_adjustment–これは、しない調整を示すフラグです。 税額控除、社会保障負担金、雇用主負担金など、労働時間に直接依存します。
その後、adjustment_amount テーブル。これは、すでにworking_hours_adjustment つまり、is_other_adjustmentにTRUE値があるもの adjustment テーブル。このテーブルには、次の属性が含まれています。
-
id–各調整額エントリの一意のID。 -
salary_payment_id–salary_paymentテーブル。 -
adjustment_id–adjustmentテーブル。 -
adjustment_amount–計算された各調整の金額。 -
adjustment_percentage-調整のパーセンテージ量。パーセンテージは時間の経過とともに変化する可能性があるため、履歴目的で使用されます。
テーブルのworking_hours_log 、working_hours_adjustment 、adjustment 、およびadjustment_amount 協力して給与を計算します。従業員は毎日、職場に到着したときと退職したときにログに記録します。このデータは、working_hours_log テーブル。たとえば、従業員が1か月間10時間の残業をしており、会社の方針に従って、1時間の残業ごとに1時間あたり20%多く支払われるとします。 adjustment 表を見ると、必要な調整、つまり残業を見つけることができます。これには、一定の割合(20%)が含まれます。 is_working_hours_adjustmentもあります TRUEに設定します。これら2つのテーブルのデータを使用することで、調整を計算し、working_hours_adjustment テーブル。
これで、しない他のすべての調整を計算できます。 労働時間に依存します。これは、adjustment_amount テーブル。上記と同じように、adjustment 表を作成し、必要な調整を見つけます。例:税額控除、社会保障負担金、または雇用主負担金–およびそれらに関連する割合。 is_other_adjustment adjustment これらの調整では、テーブルがTRUEに設定されます。
これらの計算に基づいて、総給与と純給与のデータをsalary_payment テーブル。
この例を確認することで、データモデルのすべてをカバーしました!
給与データモデルは気に入りましたか?
ほぼすべての状況で使用できるモデルを作成しようとしました。ただし、この長さの記事に給与計算に影響を与えるすべての特定のパラメータを含めることは不可能です。一般的な原則をカバーすることにより、私はこのモデルを給与データモデルの強固な基盤として役立つようにしようとしました。
給与データモデルについてどう思いますか?給与のニーズに対するソリューションとして適用できますか?何か違うものを思いついたことがありますか?データモデルを大幅に変更する特定の問題がありますか?コメントセクションであなたの意見を持ってください。