インデックスは、SQLデータベースのスピードを向上させます。それらはクラスター化または非クラスター化できます。しかし、それはどういう意味で、それぞれをどこに適用する必要がありますか?
私はこの感覚を知っている。そこに行ったことがある。初めての人は、どのインデックスをどの列に使用するかについて混乱することがよくあります。ただし、専門家でさえ、決定を下す前にこの問題を熟考する必要があり、状況が異なれば、決定も異なります。後でわかるように、クラスター化されたインデックスが非クラスター化されたインデックスと比較して輝いているクエリがあり、その逆もあります。
それでも、まず、それぞれを知る必要があります。同じ情報をお探しの場合は、今日が幸運な日です。
この記事では、これらのインデックスとは何か、およびそれぞれをいつ使用するかについて説明します。もちろん、実際に試すためのコードサンプルもあります。だから、チップやピザ、ソーダやコーヒーを手に入れて、この洞察に満ちた旅に没頭する準備をしてください。
準備はいいですか?
クラスター化インデックスとは
クラスタ化インデックスは、テーブルまたはビューの行の物理的な並べ替え順序を定義するインデックスです。
これを実際の形で見るために、従業員を見てみましょう。 AdventureWorks2017のテーブル データベース。
主キーもクラスター化インデックスであり、キーは BusinessEntityIDに基づいています。 桁。 ORDER BYを使用せずにこのテーブルでSELECTを実行すると、主キーでソートされていることがわかります。
以下のコードを使用して、自分で試してみてください:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
次に、図1の結果を参照してください。
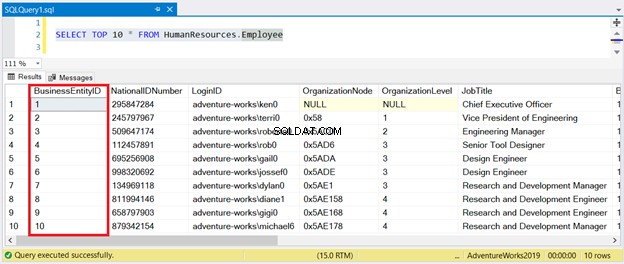
ご覧のとおり、結果セットを BusinessEntityIDで並べ替える必要はありません。 。クラスター化されたインデックスがそれを処理します。
非クラスター化インデックスとは異なり、テーブルごとに1つのクラスター化インデックスのみを持つことができます。 従業員でこれを試してみるとどうなりますか テーブル?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
以下にも同様のエラーがあります:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
クラスター化インデックスを使用する場合
次のいずれかに該当する場合、列はクラスター化インデックスの最適な候補です。
- WHERE句と結合の多数のクエリで使用されます。
- 別のテーブルへの外部キーとして使用され、最終的には結合に使用されます。
- 一意の列の値。
- 値が変わる可能性は低くなります。
- その列は、値の範囲を照会するために使用されます。>、<、> =、<=、BETWEENなどの演算子は、WHERE句の列で使用されます。
ただし、1つまたは複数の列の場合、クラスター化インデックスは適切ではありません
- 頻繁に変更する
- 幅の広いキー、またはキーサイズが大きい列の組み合わせです。
例
クラスター化インデックスは、T-SQLコードまたは任意のSQLServerGUIツールを使用して作成できます。次のように、テーブルの作成時にT-SQLで実行できます。
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
または、ALTERTABLE後を使用してこれを行うことができます クラスタ化インデックスなしでテーブルを作成する:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
もう1つの方法は、CREATECLUSTEREDINDEXを使用することです。
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
もう1つの方法は、SQL ServerManagementStudioやdbForgeStudioforSQLServerなどのSQLServerツールを使用することです。
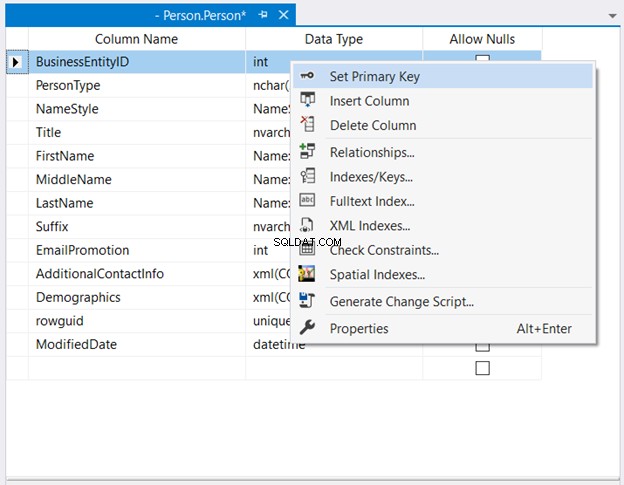
オブジェクトエクスプローラー 、データベースとテーブルノードを展開します。次に、目的のテーブルを右クリックして、デザインを選択します。 。最後に、主キーにしたい列を右クリックします>主キーを設定します>変更をテーブルに保存します。
下の図2は、 BusinessEntityIDの場所を示しています 主キーとして設定されます。
単一列のクラスター化インデックスを作成する以外に、複数の列を使用できます。 T-SQLの例を参照してください:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
このクラスター化されたインデックスを作成した後、 Person テーブルは姓で物理的に並べ替えられます 、名 、およびミドルネーム 。
このアプローチの利点の1つは、名前に基づいてクエリのパフォーマンスが向上することです。また、ORDER BYを指定せずに、名前で結果を並べ替えます。ただし、名前が変更された場合は、テーブルを再配置する必要があることに注意してください。これは毎日発生するわけではありませんが、テーブルが非常に大きい場合、影響は非常に大きくなる可能性があります。
非クラスター化インデックスとは
非クラスター化インデックスは、キーと行またはクラスター化インデックスキーへのポインターを持つインデックスです。このインデックスは、テーブルとビューの両方に適用できます。
クラスタ化インデックスとは異なり、ここでは構造がテーブルから分離されています。個別であるため、行ロケーターとも呼ばれるテーブル行へのポインターが必要です。したがって、非クラスター化インデックスの各エントリには、ロケーターとキー値が含まれます。
非クラスター化インデックスは、キーに基づいてテーブルを物理的に並べ替えません。
非クラスター化インデックスのインデックスキーの最大サイズは1700バイトです。含まれる列を追加することで、この制限を回避できます。この方法は、クエリがキーサイズを増やすことなくより多くの列をカバーする必要がある場合に適しています。
フィルター処理された非クラスター化インデックスを作成することもできます。これにより、クエリのパフォーマンスを向上させながら、インデックスのメンテナンスコストとストレージを削減できます。
非クラスター化インデックスを使用する場合
次の条件が当てはまる場合、1つまたは複数の列が非クラスター化インデックスの適切な候補です。
- 1つまたは複数の列は、WHERE句または結合で使用されます。
- クエリは大きな結果セットを返しません。
- 等式演算子を使用したWHERE句の完全一致が必要です。
例
このコマンドは、従業員に一意の非クラスター化インデックスを作成します テーブル:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
テーブルとは別に、ビューの非クラスター化インデックスを作成できます:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
その他の一般的な質問と満足のいく回答
クラスター化インデックスと非クラスター化インデックスの違いは何ですか?
以前に見たものから、クラスター化インデックスと非クラスター化インデックスの違いについてのアイデアをすでに形成できます。ただし、簡単に参照できるようにテーブルに置いておきましょう。
| 情報 | クラスター化されたインデックス | 非クラスター化インデックス |
| 適用対象 | テーブルとビュー | テーブルとビュー |
| テーブルごとに許可 | 1 | 999 |
| キーサイズ | 900バイト | 1700バイト |
| インデックスキーあたりの列数 | 32 | 32 |
| 対象 | 範囲クエリ(>、<、> =、<=、BETWEEN) | 完全一致(=) |
| キーに含まれない列 | 許可されていません | 許可 |
| 条件付きフィルター | 許可されていません | 許可 |
主キーはクラスター化インデックスまたは非クラスター化インデックスのどちらにする必要がありますか?
主キーは制約です。列を主キーにすると、既存のクラスター化インデックスがすでに配置されていない限り、クラスター化インデックスがその列から自動的に作成されます。
主キーとクラスター化インデックスを混同しないでください。主キーは、クラスター化インデックスキーにすることもできます。ただし、クラスター化インデックスキーは、主キー以外の別の列にすることができます。
別の例を見てみましょう。 人 AdventureWorks201の表 7、 BusinessEntityID 主キー。これは、クラスター化されたインデックスキーでもあります。そのクラスター化されたインデックスを削除できます。次に、姓に基づいてクラスター化されたインデックスを作成します 、名 、およびミドルネーム 。主キーは引き続きBusinessEntityID 列。
しかし、主キーは常にクラスター化する必要がありますか?
場合によります。クラスター化されたインデックスをいつ使用するかについての質問を再検討してください。
多くのクエリのWHERE句に1つまたは複数の列が含まれている場合、これはクラスター化インデックスの候補です。ただし、もう1つの考慮事項は、クラスター化されたインデックスキーの幅です。幅が広すぎる–クラスター化されていない各インデックスのサイズは、存在する場合は増加します。非クラスター化インデックスも、クラスター化インデックスキーをポインターとして使用することに注意してください。したがって、クラスター化されたインデックスキーはできるだけ狭くしてください。
多数のクエリがWHERE句で主キーを使用する場合は、それをクラスター化インデックスキーとしても残します。そうでない場合は、主キーを非クラスター化インデックスとして作成します。
しかし、まだ確信が持てない場合はどうなりますか?次に、列がクラスター化されている場合とクラスター化されていない場合のパフォーマンス上の利点を評価できます。それで、それについての次のセクションに注目してください。
どちらが高速ですか:クラスター化インデックスと非クラスター化インデックスのどちらですか?
良い質問。一般的なルールはありません。クエリの論理読み取りと実行プランを確認する必要があります。
簡単な実験には、 AdventureWorks2017の次の表のコピーが含まれます。 データベース:
- 人
- BusinessEntityAddress
- 住所
- AddressType
スクリプトは次のとおりです:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
上記の構造を使用して、クラスター化インデックスと非クラスター化インデックスのクエリ速度を比較します。
Personのコピーが2つあります テーブル。 1つ目はBusinessEntityIDを使用します プライマリおよびクラスター化されたインデックスキーとして。 2番目はまだBusinessEntityIDを使用します 主キーとして。クラスタ化されたインデックスは、姓に基づいています 、名 、ミドルネーム 、およびサフィックス 。
始めましょう。
姓に基づく完全一致のクエリ
まず、簡単なクエリを作成しましょう。また、STATISTICSIOをオンにする必要があります。次に、結果をstatisticsparser.comに貼り付けて、表形式で表示します。
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
WHERE句がクラスター化されたインデックスキーと一致しないため、最初のSELECTが遅くなることが予想されます。しかし、論理的な読み取りを確認しましょう。
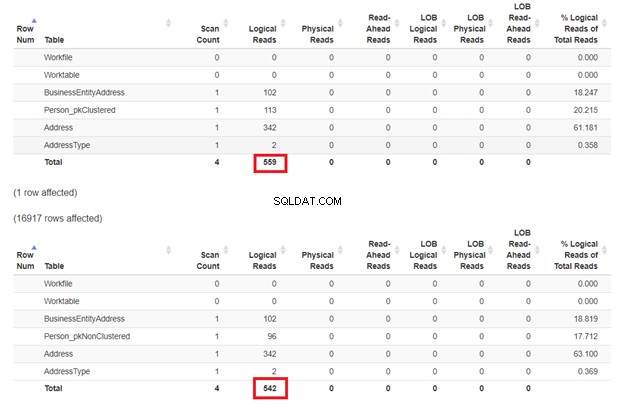
図3で予想されているように、 Person_pkClustered より論理的な読み取りがありました。したがって、クエリにはより多くのI/Oが必要です。理由?テーブルはBusinessEntityIDで並べ替えられます 。ただし、2番目のテーブルには、名前に基づくクラスター化インデックスがあります。クエリは名前に基づく結果を求めているため、 Person_pkNonClustered 勝ちます。論理的な読み取りが少ないほど、クエリは高速になります。
他に何が起こっているのですか?図4を確認してください。
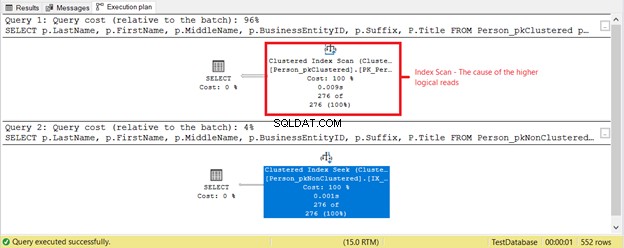
図4の実行プランに基づいて、他に何かが発生しました。クラスター化インデックススキャンがインデックスシークではなく最初のSELECTにあるのはなぜですか。犯人はタイトルです SELECTの列。既存のインデックスのいずれにも含まれていません。 SQL Serverオプティマイザーは、BusinessEntityIDに基づくクラスター化インデックスを使用する方が高速であると判断しました。 次に、SQL Serverはそれをスキャンして正しい姓を探し、名、ミドルネーム、およびタイトルを取得しました。
タイトルを削除します 列であり、使用される演算子は Index Seek 。なんで?残りのフィールドは、姓に基づく非クラスター化インデックスでカバーされているためです。 、名 、ミドルネーム 、およびサフィックス 。 BusinessEntityIDも含まれます クラスター化されたインデックスキーロケーターとして。
ビジネスエンティティIDに基づく範囲クエリ
クラスタ化インデックスは、範囲クエリに適しています。それはいつもそうですか?以下のコードを使用して調べてみましょう。
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
リストには、 BusinessEntityIDsの範囲に基づく行が必要です。 285から290まで。この場合も、2つのテーブルのクラスター化インデックスと非クラスター化インデックスはそのままです。次に、図5の論理読み取りを行います。予想される勝者は Person_pkClusteredです。 主キーはクラスター化インデックスキーでもあるためです。

Person_pkClusteredの論理読み取りが低くなっていますか ?クラスター化インデックスは、このシナリオの範囲クエリでその価値を証明しました。図6で実行計画がさらに明らかになることを見てみましょう。
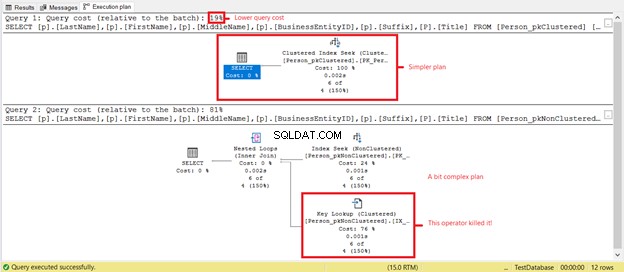
最初のSELECTは、図7に基づいて、より単純な計画とより低いクエリコストを備えています。これは、より低い論理読み取りもサポートします。一方、2番目のSELECTには、クエリの速度を低下させるキールックアップ演算子があります。犯人?繰り返しますが、これはタイトル 桁。クエリの列を削除するか、非クラスター化インデックスの包含列として追加します。そうすれば、より良い計画とより低い論理読み取りが得られます。
クエリは結合と完全に一致します
多くのSELECTステートメントには結合が含まれています。いくつかテストしてみましょう。ここでは、完全一致から始めます:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Person_pkNonClusteredからの2番目のSELECTが必要です。 名前にクラスター化されたインデックスがあると、論理的な読み取りが少なくなります。しかし、それはそうですか?図7を参照してください。
名前の非クラスター化インデックスは問題なく機能したようです。論理読み取りは同じです。実行プランを確認すると、演算子の違いは Person_pkNonClusteredでのクラスター化インデックスシークです。 、および Person_pkClusteredのインデックスシーク 。
したがって、論理読み取りと実行プランを確認する必要があります。
結合を使用した範囲クエリ
私たちの期待は現実とは異なる可能性があるため、範囲クエリで試してみましょう。クラスター化インデックスは、一般的にそれでうまくいきます。しかし、参加を含めるとどうなりますか?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
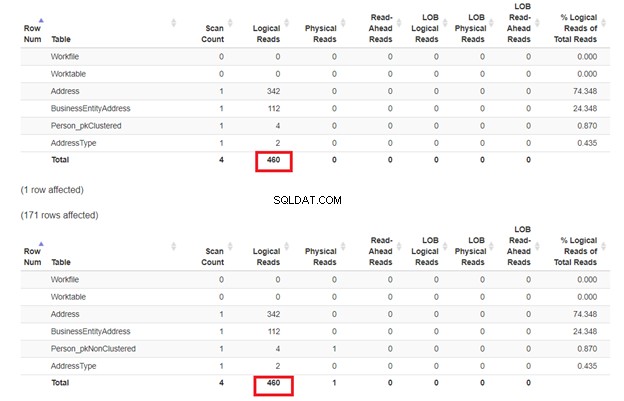
次に、図8のこれら2つのクエリの論理読み取りを調べます。
何が起こったか?図9では、現実は Person_pkClusteredに噛み付いています 。 Person_pkNonClustered と比較して、より多くのI/Oコストが観察されました。 。それは私たちが期待するものとは異なります。ただし、このフォーラムの回答に基づくと、クエリ内のすべての列がインデックスで100%カバーされている場合、非クラスター化インデックスシークはクラスター化インデックスシークよりも高速になる可能性があります。この場合、 Person_pkNonClusteredのクエリ 非クラスター化インデックス( BusinessEntityID )を使用して列をカバーしました - 鍵; 姓 、名 、ミドルネーム 、サフィックス –クラスター化されたインデックスキーへのポインタ)。
パフォーマンスの挿入
次に、同じテーブルでINSERTのパフォーマンスをテストしてみてください。
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
図9は、INSERT論理読み取りを示しています。

どちらも同じI/Oを生成しました。したがって、どちらも同じように機能しました。
パフォーマンスの削除
最後のテストにはDELETEが含まれます:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
図10は、論理読み取りを示しています。違いに注意してください。

Person_pkClusteredでより高い論理読み取りが行われるのはなぜですか ?重要なのは、DELETEステートメントの条件は名前の完全一致に基づいているということです。オプティマイザーは、最初に非クラスター化インデックスに頼る必要があります。それはより多くのI/Oを意味します。図11の実行プランを使用して確認しましょう。
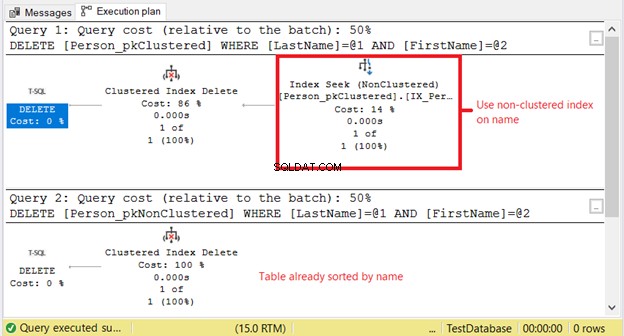
最初のSELECTには、非クラスター化インデックスに対するインデックスシークが必要です。その理由は、姓のWHERE句です。 および名 。一方、 Person_pkNonClustered クラスター化されたインデックスのため、すでに物理的に名前で並べ替えられています。
要点
パフォーマンスの高いクエリを作成することは、運ではありません。クラスター化されたインデックスとクラスター化されていないインデックスを配置するだけでは不十分で、突然、クエリにスピードが加わります。結果セット以外の細部に焦点を合わせるには、レンズとしてツールを使い続ける必要があります。
しかし、これらすべてを行う時間がない場合もあります。それは正常だと思います。しかし、それほど混乱しない限り、次の日に仕事があり、それを解決することができます。これは最初は簡単ではありません。それは実際には混乱するでしょう。また、たくさんの質問があります。しかし、絶え間ない練習で、あなたはそれを達成することができます。だから、あなたのあごを上げてください。
クラスター化インデックスと非クラスター化インデックスはどちらもクエリを強化するためのものであることを忘れないでください。主な違い、使用シナリオ、およびツールを理解することは、高性能クエリのコーディングの探求に役立ちます。
この投稿が、クラスター化インデックスと非クラスター化インデックスに関する最も差し迫った質問に答えることを願っています。読者のために他に何か追加するものはありますか?コメントセクションが開いています。
そして、この投稿が啓発的であると感じたら、お気に入りのソーシャルメディアプラットフォームで共有してください。
インデックスとクエリのパフォーマンスの詳細については、以下の記事をご覧ください。
- クエリをワープスピードする22の気の利いたSQLインデックスの例
- SQLクエリの最適化:クエリを強化するための5つの重要な事実