前回の投稿では、スカラー集計を特徴とするクエリをオプティマイザーによってより効率的な形式に変換する方法を説明しました。念のため、ここに再びスキーマがあります:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; プランの選択
各ベーステーブルに10,000行があるため、オプティマイザーは、30,000行すべてを集計に読み込むことで最大値を計算する単純なプランを作成します。
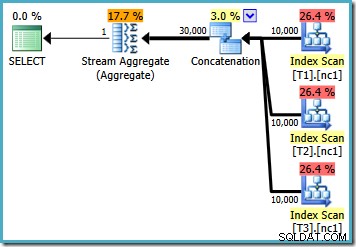
各テーブルに50,000行あるため、オプティマイザーは問題にもう少し時間を費やし、よりスマートな計画を見つけます。各インデックスから(降順で)一番上の行だけを読み取り、それらの3行だけから最大値を計算します:
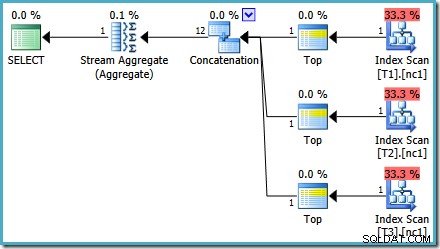
オプティマイザーのバグ
推定について少し奇妙なことに気付くかもしれません 予定。連結演算子は3つのテーブルから1つの行を読み取り、どういうわけか12の行を生成します。これは、2011年5月に報告したカーディナリティ推定のバグが原因で発生するエラーです。SQLServer2014 CTP 1の時点ではまだ修正されていません(新しいカーディナリティ推定が使用されている場合でも)が、最終リリース。
エラーがどのように発生するかを確認するために、50,000行のケースに対してオプティマイザーによって検討されたプランの選択肢の1つに、連結演算子の下に部分的な集計があることを思い出してください。
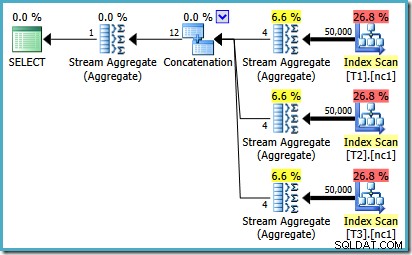
これは、これらの部分的なMAXのカーディナリティ推定です。 障害のある集計。彼らは、結果が1行であることが保証されている4行を推定します。 4以外の数が表示される場合があります。これは、プランのコンパイル時にオプティマイザーが使用できる論理プロセッサーの数によって異なります(詳細については、上記のバグリンクを参照してください)。
オプティマイザは、後で部分集計をトップ(1)演算子に置き換えます。これにより、カーディナリティ推定値が正しく再計算されます。残念ながら、連結演算子は、置き換えられた部分集計の推定値を反映しています(3 * 4 =12)。その結果、3行を読み取り、12を生成する連結になります。
MAXの代わりにTOPを使用する
50,000行の計画をもう一度見ると、オプティマイザーによって検出された最大の改善は、すべての行を読み取り、ブルートフォースを使用して最大値を計算する代わりに、上位(1)演算子を使用することです。同様のことを試し、Topを使用してクエリを明示的に書き直すとどうなりますか?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
新しいクエリの実行プランは次のとおりです。
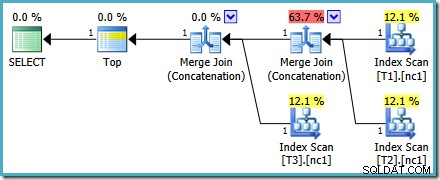
このプランは、オプティマイザーがMAX用に選択したプランとはまったく異なります。 クエリ。これは、3つの順序付けられたインデックススキャン、連結モードで実行される2つのマージ結合、および1つのトップ演算子を備えています。この新しいクエリプランには、少し詳しく調べる価値のある興味深い機能がいくつかあります。
計画分析
最初の行(インデックスの降順)は、各テーブルの非クラスター化インデックスから読み取られ、連結モードで動作するマージ結合が使用されます。マージ結合演算子は通常の意味で結合を実行していませんが、この演算子の処理アルゴリズムは、結合基準を適用する代わりに、入力を連結するように簡単に適合させることができます。
新しいプランでこの演算子を使用する利点は、MergeConcatenationが入力全体で並べ替え順序を保持することです。対照的に、通常の連結演算子は、入力から順番に読み取ります。次の図は違いを示しています(クリックして展開):
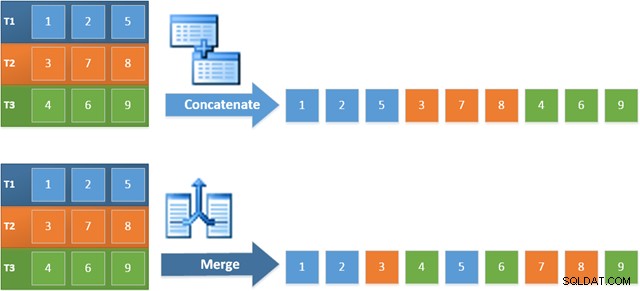
マージ連結の順序を保持する動作は、新しいプランの左端のマージ演算子によって生成された最初の行が、3つのテーブルすべての列c1で最も高い値を持つ行であることが保証されることを意味します。具体的には、計画は次のように機能します。
- 1行 各テーブルから(インデックスの降順で)読み取られます。および
- 各マージは1つのテストを実行します どの入力行の値が高いかを確認する
これは非常に効率的な戦略のように思われるため、オプティマイザーのMAXが奇妙に思えるかもしれません。 計画の推定コストは、新しい計画の半分未満です。その理由の大部分は、順序を保持するマージ連結は、単純な連結よりもコストがかかると想定されているためです。オプティマイザーは、各マージが最大1行しか認識できないことを認識しておらず、結果としてそのコストを過大評価しています。
その他のコストの問題
厳密に言えば、ここではリンゴとリンゴを比較していません。これは、2つの計画が異なるクエリ用であるためです。 SSMSは、さまざまなステートメントのコストパーセンテージをバッチで表示することで正確にそれを行いますが、そのようなコストを比較することは一般的に有効なことではありません。しかし、私は逸脱します。
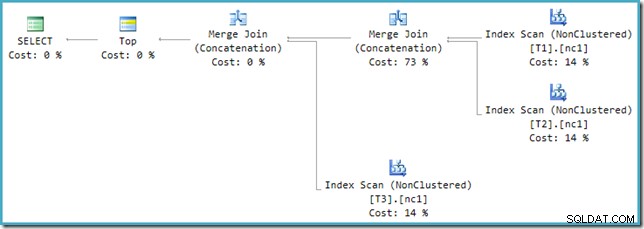
SQL Sentry Plan ExplorerではなくSSMSで新しいプランを見ると、次のように表示されます。
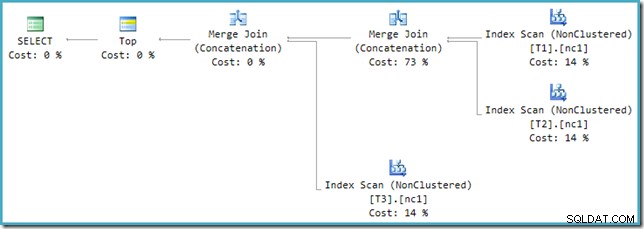
マージ結合連結演算子の1つは73%の推定コストがあり、2番目の演算子(まったく同じ数の行で動作)はまったくコストがかからないことが示されています。ここで何か問題があることを示すもう1つの兆候は、このプランのオペレーターのコストの割合が合計で100%にならないことです。
オプティマイザーと実行エンジン
問題は、オプティマイザーと実行エンジンの間の非互換性にあります。オプティマイザでは、UnionとUnionAllに2つ以上の入力を含めることができます。実行エンジンでは、連結演算子のみが2以上を受け入れることができます。 入力;マージ結合には正確に必要です 結合ではなく連結を実行するように構成されている場合でも、2つの入力。
この非互換性を解決するために、最適化後の書き換えが適用され、オプティマイザーの出力ツリーが実行エンジンが処理できる形式に変換されます。 3つ以上の入力を持つUnionまたはUnionAllがMergeを使用して実装される場合、演算子のチェーンが必要です。この場合、ユニオンオールへの3つの入力では、2つのマージユニオンが必要です。
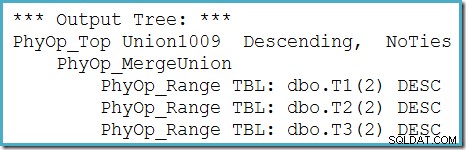
トレースフラグ8607を使用して、オプティマイザの出力ツリー(物理マージユニオンへの3つの入力を含む)を確認できます。
不完全な修正
残念ながら、最適化後の書き換えは完全には実装されていません。それは原価計算の数を少し混乱させます。四捨五入の問題は別として、計画コストは合計で114%になり、追加の14%は、書き換えによって生成された追加のマージ結合連結への入力から発生します。
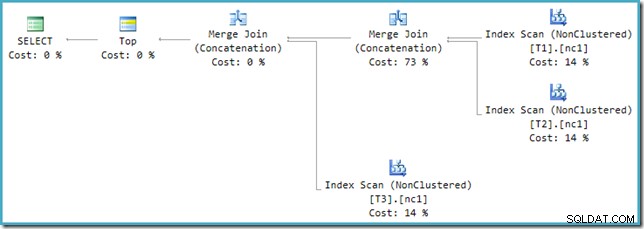
このプランの右端のマージは、オプティマイザの出力ツリーの元の演算子です。ユニオンオールオペレーションの全費用が割り当てられます。もう1つのマージは書き換えによって追加され、コストはゼロになります。
どちらの方法で見ても(通常の連結に影響するさまざまな問題があります)、数値は奇妙に見えます。 Plan Explorerは、少なくとも数値の合計が100%になるようにすることで、XMLプランの壊れた情報を回避するために最善を尽くします。
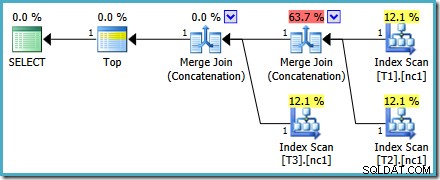
この特定のコストの問題は、SQL Server 2014CTP1で修正されています。
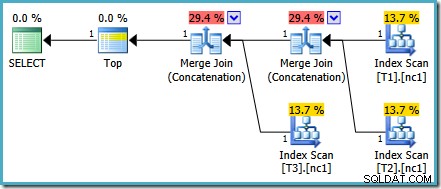
マージ連結のコストは2つのオペレーター間で均等に分割され、パーセンテージの合計は100%になります。基になるXMLが修正されたため、SSMSも同じ番号を表示できます。
どちらの計画が優れていますか?
MAXを使用してクエリを作成する場合 、効率的な計画を見つけるために必要な追加の作業を実行することを選択するオプティマイザーに依存する必要があります。オプティマイザが早い段階で明らかに十分な計画を見つけた場合、各ベーステーブルからすべての行を読み取る比較的非効率的な計画を作成できます。
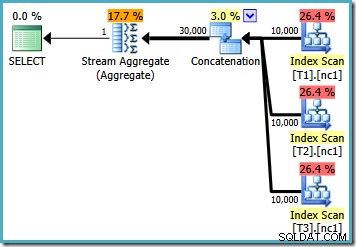
SQLServer2008またはSQLServer2008 R2を実行している場合でも、オプティマイザーは、ベーステーブルの行数に関係なく、非効率的なプランを選択します。次の計画は、50,000行のSQL Server2008R2で作成されました。
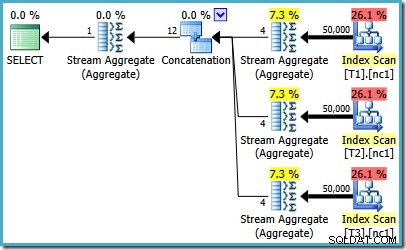
各テーブルに5,000万行ある場合でも、2008および2008 R2オプティマイザーは並列処理を追加するだけで、上位演算子は導入されません。
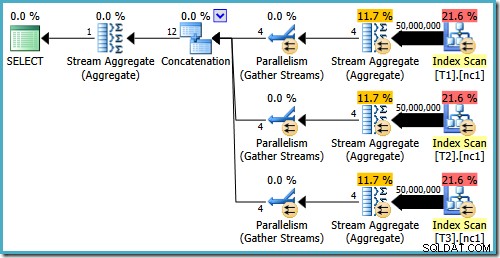
以前の投稿で述べたように、SQL Server2008および2008R2でトップオペレーターを使用してプランを作成するには、トレースフラグ4199が必要です。 SQL Server 2005および2012以降では、トレースフラグは必要ありません:
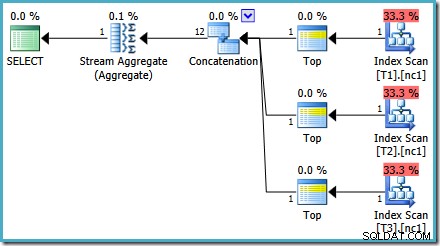
ORDERBYのあるTOP
以前の実行計画で何が起こっているかを理解したら、明示的なTOPとORDER BYを使用してクエリを書き直すという意識的な(そして情報に基づいた)選択を行うことができます:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
結果の実行プランには、SQL Serverの一部のバージョンでは奇妙に見えるコストの割合が含まれる場合がありますが、基本的なプランは適切です。クエリの最適化が完了した後、数値が奇数に見えるようにする最適化後の書き換えが適用されるため、オプティマイザーのプランの選択がこの問題の影響を受けていないことを確認できます。
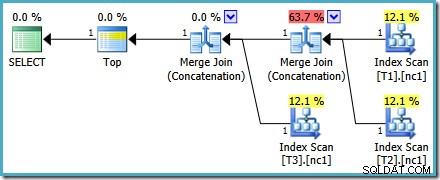
このプランは、ベーステーブルの行数に応じて変更されることはなく、トレースフラグを生成する必要もありません。小さな追加の利点は、この計画がコストベースの最適化の最初のフェーズ(検索0)中にオプティマイザーによって検出されることです:
MAXのオプティマイザーによって選択された最適なプラン クエリでは、コストベースの最適化の2つの段階を実行する必要がありました(検索0および 検索1)。
TOPの間にはわずかな意味上の違いがあります クエリと元のMAX 私が言及すべきフォーム。どのテーブルにも行が含まれていない場合、元のクエリは単一のNULLを生成します 結果。交換用のTOP (1) 同じ状況では、クエリはまったく出力を生成しません。この違いは、実際のクエリでは重要ではないことがよくありますが、注意する必要があります。 TOPの動作を複製できます MAXを使用する SQL Server 2008以降では、空のセットGROUP BYを追加します。 :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
この変更は、MAXに対して生成された実行プランには影響しません。 エンドユーザーに見える方法でクエリを実行します。
MAXとマージ連結
TOP (1)でのMergeJoinConcatenationの成功を考えると 実行プランでは、元のMAXに対して同じ最適なプランを生成できるかどうか疑問に思うのは自然なことです。 UNION ALLに対して、オプティマイザーが通常の連結ではなくマージ連結を使用するように強制するかどうかを照会します。 操作。
この目的のためのクエリヒントがあります– MERGE UNION –しかし残念ながら、SQLServer2012以降でのみ正しく機能します。以前のバージョンでは、UNION ヒントはUNIONにのみ影響します UNION ALLではなくクエリ 。 SQL Server 2012以降では、これを試すことができます:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
マージ連結を特徴とするプランで報われます。残念ながら、それは私たちが望んでいたかもしれないすべてではありません:
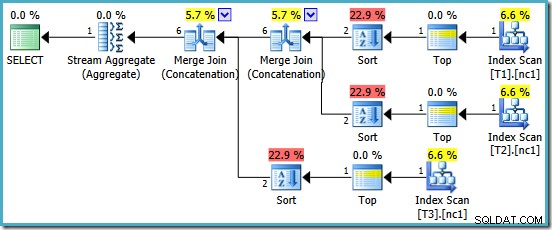
この計画で興味深い演算子は種類です。 1行の入力カーディナリティ推定と、出力の4行の推定に注目してください。原因は今ではおなじみのはずです。これは、前に説明したのと同じ部分的な集約カーディナリティ推定エラーです。
ソートの存在は、部分的な集計に関するもう1つの問題を明らかにします。それらは、誤ったカーディナリティ推定を生成するだけでなく、ソートを不要にするインデックスの順序を保持できません(マージ連結にはソートされた入力が必要です)。部分集約はスカラーMAXです 集計、1行を生成することが保証されているため、順序付けの問題はとにかく議論の余地があります(1行を並べ替える方法は1つしかありません!)
これは残念なことです。なぜなら、ソートがなければ、これはまともな実行計画になるからです。部分的な集計が適切に実装されている場合、およびMAX GROUP BY ()で記述 節では、オプティマイザーが3つのTopと最終的なStream Aggregateを単一の最終的なTop演算子に置き換えて、明示的なTOP (1)とまったく同じ計画を与えることができることを期待することもできます。 クエリ。オプティマイザーには現在その変換が含まれていません。また、将来的に含める価値のあるものにするのに十分な頻度でオプティマイザーが役立つとは思いません。
最後の言葉
TOPを使用する MINよりも常に好ましいとは限りません またはMAX 。場合によっては、最適性の低い計画が作成されます。この投稿のポイントは、オプティマイザーによって適用される変換を理解することで、役立つことが判明する可能性のある元のクエリを書き直す方法を提案できることです。