結果の重複を削除する必要がある場合、SQL DISTINCTは良い(または悪い)ですか?
良いと言う人もいて、重複が表示されたらDISTINCTを追加します。悪いと言う人もいて、集計関数なしでGROUPBYを使用することを提案しています。重複を削除する必要がある場合、DISTINCTとGROUPBYは同じであると言う人もいます。
この投稿では、正解を得るために詳細を詳しく説明します。したがって、最終的には、ニーズに基づいて最適なキーワードを使用します。始めましょう。
SQLSELECTDISTINCTステートメントの基本についての簡単なリマインダー
深く掘り下げる前に、SQLSELECTDISTINCTステートメントが何であるかを思い出してみましょう。データベーステーブルにはさまざまな理由で重複する値が含まれる可能性がありますが、一意の値のみを取得したい場合があります。この場合、SELECTDISTINCTが便利です。このDISTINCT句により、SELECTステートメントは一意のレコードのみをフェッチします。
ステートメントの構文は単純です:
SELECT DISTINCT column
FROM table_name
WHERE [condition];ここでは、WHERE条件はオプションです。
このステートメントは、単一の列と複数の列の両方に適用されます。複数の列に適用されるこのステートメントの構文は次のとおりです。
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;複数の列をクエリするシナリオでは、ステートメントで定義されたすべての列の値の組み合わせを使用して、一意性を判断することをお勧めします。
それでは、SELECTDISTINCTステートメントを適用する実際の使用法と落とし穴を見てみましょう。
SQLDISTINCTが重複を削除するためにどのように機能するか
答えを見つけるのはそれほど難しいことではありません。 SQL Serverは、必要な結果を得るためにクエリがどのように処理されるかを確認するための実行プランを提供してくれました。
次のセクションでは、DISTINCTを使用する場合の実行プランに焦点を当てます。 Ctrl-Mを押す必要があります 以下のクエリを実行する前に、SQL ServerManagementStudioで。または、[実際の実行プランを含める]をクリックします ツールバーから。
SQLDISTINCTのクエリプラン
2つのクエリを比較することから始めましょう。最初のクエリはDISTINCTを使用せず、2番目のクエリは使用します。
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
実行計画は次のとおりです。
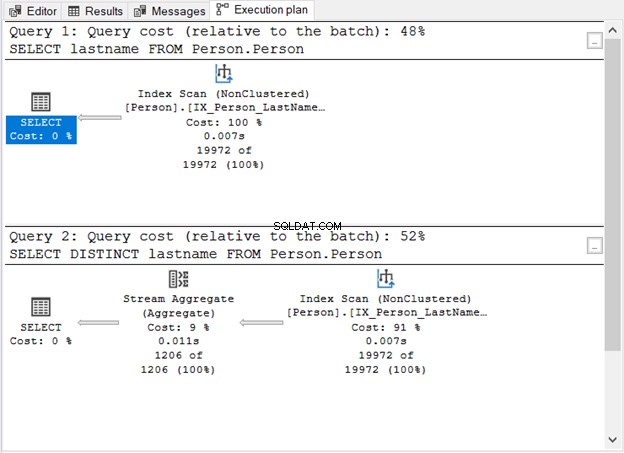
図1は私たちに何を示しましたか?
- DISTINCTキーワードがなければ、クエリは簡単です。
- DISTINCTを追加すると、追加のステップが表示されます。
- DISTINCTを使用する場合のクエリコストは、DISTINCTを使用しない場合よりも高くなります。
- どちらにもインデックススキャン演算子があります。クエリには特定のWHERE句がないため、これは理解できます。
- 余分なステップであるStreamAggregate演算子は、重複を削除するために使用されます。
STATISTICS IOをチェックすると、論理読み取りの数は同じ(107)になります。それでも、レコードの数は大きく異なります。最初のクエリで19,972行が返されます。一方、2番目のクエリでは1,206行が返されます。
したがって、いつでもDISTINCTを追加することはできません。ただし、一意の値が必要な場合、これは必要なオーバーヘッドです。
一意の値を出力するために使用される演算子があります。それらのいくつかを調べてみましょう。
STREAM AGGREGATE
これは、図1で見た演算子です。単一の入力を受け入れ、集計結果を出力します。図1では、入力はインデックススキャンオペレーターからのものです。ただし、StreamAggregateには並べ替えられた入力が必要です。
図1に示すように、 IX_Person_LastName_FirstName_MiddleNameを使用します。 、名前の一意でないインデックス。インデックスはすでにレコードを名前で並べ替えているため、StreamAggregateは入力を受け入れます。インデックスがないと、クエリオプティマイザはプランで追加のSort演算子を使用することを選択できます。そして、それはより高価になります。または、ハッシュマッチを使用できます。
HASH MATCH(AGGREGATE)
DISTINCTで使用されるもう1つの演算子は、ハッシュマッチです。この演算子は、結合と集計に使用されます。
DISTINCTを使用する場合、Hash Matchは結果を集計して、一意の値を生成します。これが1つの例です。
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
そして、これが実行計画です:
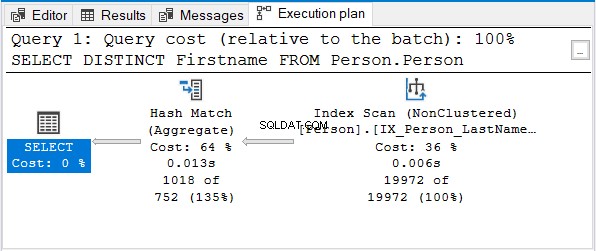
しかし、なぜStream Aggregateを使用しないのですか?
同じ名前のインデックスが使用されていることに注意してください。そのインデックスは姓でソートされます 最初。つまり、名 クエリのみが並べ替えられなくなります。
ハッシュマッチ(集計)は、重複を削除するための次の論理的な選択肢です。
HASH MATCH(FLOW DISTINCT)
Hash Match(Aggregate)はブロッキング演算子です。したがって、入力ストリーム全体を処理した出力は生成されません。行数を制限すると(DISTINCTでTOPを使用する場合など)、それらの行が使用可能になるとすぐに一意の出力が生成されます。それがハッシュマッチ(フローディスティンクト)のすべてです。
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
クエリはDISTINCTとともにTOP100を使用します。実行計画は次のとおりです。
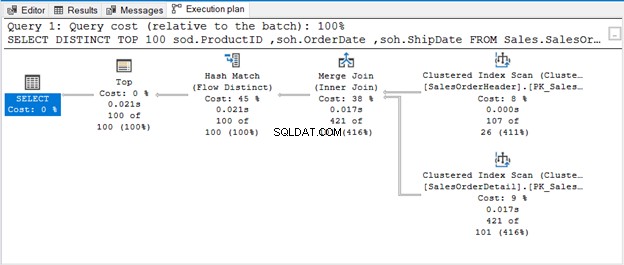
うん。これが発生する可能性があります。以下の例を検討してください。
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
次に、実行計画を確認します。
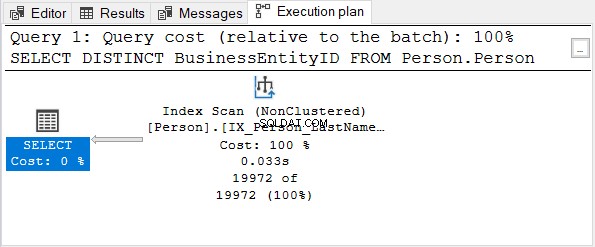
BusinessEntityID 列は主キーです。その列はすでに一意であるため、DISTINCTを適用しても意味がありません。 SELECTステートメントからDISTINCTを削除してみてください–実行プランは図4と同じです。
一意のインデックスを持つ列でDISTINCTを使用する場合も同様です。
SQLDISTINCTはSELECTリストのすべての列で機能します
これまでのところ、例では1つの列のみを使用しています。ただし、DISTINCTは、SELECTリストで指定したすべての列で機能します。
これが例です。このクエリにより、3つの列すべての値が一意になることが確認されます。
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
図5の結果セットの最初の数行に注目してください。
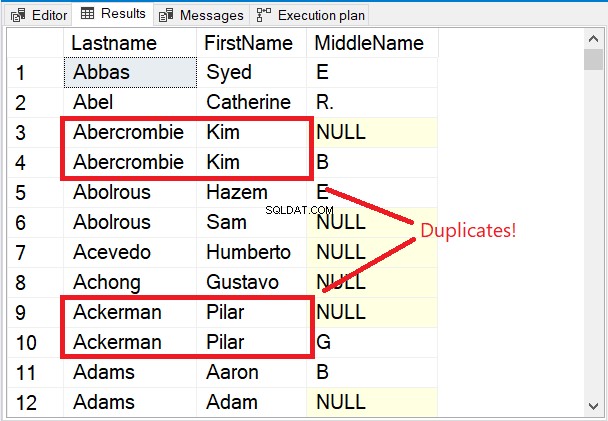
最初の数行はすべて一意です。 DISTINCTキーワードは、ミドルネームが 列も考慮されます。赤で囲まれた2つの名前に注目してください。 姓を検討する および名 それらを複製するだけです。ただし、ミドルネームを追加する ミックスにすべてを変えました。
一意の姓名を取得したいが、結果にミドルネームを含めたい場合はどうなりますか?
2つのオプションがあります:
- WHERE句を追加して、NULLのミドルネームを削除します。これにより、ミドルネームがNULLのすべての名前が削除されます。
- または、姓にGROUPBY句を追加します および名 列。次に、ミドルネームでMIN集計関数を使用します 桁。これにより、姓と名が同じミドルネームが1つ取得されます。
SQLDISTINCTとGROUPBYの比較
集計関数なしでGROUPBYを使用すると、DISTINCTのように機能します。どうやって知るの?調べる方法の1つは、例を使用することです。
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
それらを実行し、実行計画を確認します。下のスクリーンショットのようですか?
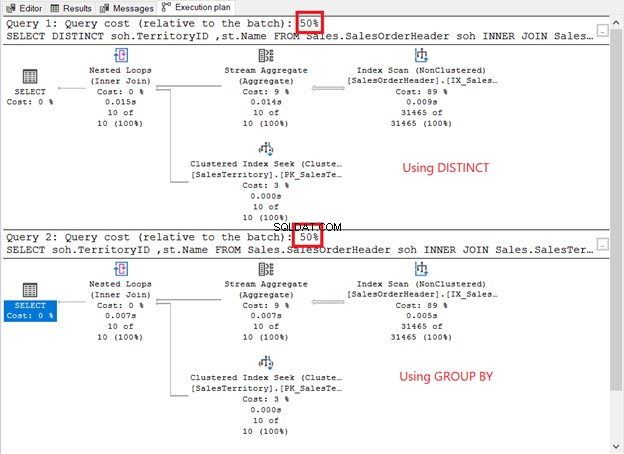
それらはどのように比較されますか?
- 同じプラン演算子とシーケンスがあります。
- それぞれのオペレーターコストとクエリコストは同じです。
QueryPlanHashを確認した場合 2つのSELECT演算子のプロパティは、同じです。したがって、クエリオプティマイザは同じプロセスを使用して同じ結果を返しました。
結局、一意の値を返す点でGROUPBYを使用する方がDISTINCTよりも優れているとは言えません。上記の例を使用してDISTINCTをGROUPBYに置き換えることで、これを証明できます。
どちらを使用するかは、好みの問題になります。私はDISTINCTが好きです。クエリの意図を明示的に伝え、一意の結果を生成します。そして私にとって、GROUP BYは、集計関数を使用して結果をグループ化するためのものです。その意図も明確で、キーワード自体と一致しています。他の誰かが私のクエリをいつか維持するかどうかはわかりません。したがって、コードは明確である必要があります。
しかし、それで話は終わりではありません。
SQLDISTINCTがGROUPBYと同じでない場合
私は自分の意見を表明しましたが、それからこれですか?
それは本当です。それらは常に同じではありません。この例を考えてみましょう。
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
結果セットはソートされていませんが、行は前の例と同じです。唯一の違いは、サブクエリの使用です:
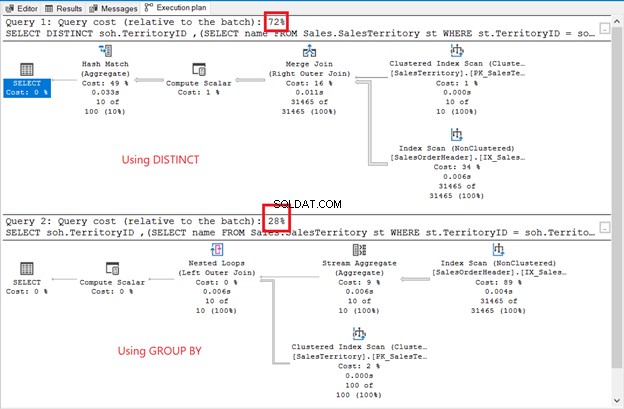
違いは明らかです:オペレーター、クエリコスト、全体的な計画。今回は、GROUP BYがわずか28%のクエリコストで勝ちます。しかし、これが問題です。
目的は、それらが異なる可能性があることを示すことです。それで全部です。これは決して推奨事項ではありません。結合を使用すると、実行プランが向上します(図6を再度参照してください)。
これまでに学んだことは次のとおりです。
- DISTINCTは、重複を削除するためのプラン演算子を追加します。
- 集計関数のないDISTINCTとGROUPBYは、同じプランになります。つまり、ほとんどの場合同じです。
- サブクエリがSELECTリストに含まれている場合、DISTINCTとGROUPBYのプランが異なる場合があります。
では、SQL DISTINCTは、結果の重複を削除するのに良いのか悪いのか?
結果はそれが良いことを示しています。計画は同じであるため、GROUPBYより良くも悪くもありません。ただし、実行計画を確認するのは良い習慣です。最初から最適化を考えてください。そうすれば、DISTINCTとGROUP BYの違いに遭遇した場合、それらを見つけることができます。
さらに、最新のツールを使用すると、このタスクがはるかに簡単になります。たとえば、Devartの人気のある製品dbForge SQL Completeには、SSMS結果グリッドの準備完了結果セットの集計関数の値を計算する特定の機能があります。 DISTINCT値もそこにあります。
投稿が好きですか?次に、お気に入りのソーシャルメディアプラットフォームで共有して、その言葉を広めてください。
- SQL GROUP BY:プロのように結果をグループ化するための3つの簡単なヒント
- SQL INSERT INTO SELECT:重複を処理する5つの簡単な方法
- SQL集計関数とは何ですか? (初心者向けの簡単なヒント)
- SQLクエリの最適化:クエリを強化するための5つのコアファクト