数週間前、SQLskillsチームはパフォーマンスチューニングイマージョンイベント(IE2)のためにタンパにいて、ベースラインをカバーしていました。ベースラインは、多くの理由で非常に価値があるため、私の心に近い、大切なトピックです。これらの理由のうちの2つは、クライアントに教えるか作業するかにかかわらず、常にベースラインを使用してパフォーマンスのトラブルシューティングを行い、次に使用量の傾向を示し、容量計画の見積もりを提供することです。ただし、既存のパフォーマンスメトリックをベースラインと見なすかどうかに関係なく、パフォーマンスの調整やテストを行う場合にも不可欠です。
モジュール中に、パフォーマンスモニター、DMV、トレースまたはXEデータなどのデータのさまざまなソースを確認しましたが、データの読み込みに関連する質問がありました。具体的には、データのロード中にインデックスを配置するよりも、インデックスのないテーブルにデータをロードし、終了時に作成する方がよいかどうかが問題でした。私の回答は「通常、はい」でした。私の個人的な経験では、これは常に当てはまりますが、パフォーマンスの変化が予期されたものではない場合に、誰かがどのような警告や1回限りのシナリオに遭遇する可能性があるかはわかりません。すべてのパフォーマンスに関する質問は、テストするまで確実にはわかりません。一方のメソッドのベースラインを確立し、もう一方のメソッドがそのベースラインを改善するかどうかを確認するまでは、推測するだけです。テストするのは楽しいと思いました。このシナリオは、私が真実であると期待することを証明するだけでなく、調査するメトリック、その理由、およびそれらをキャプチャする方法を示すためのものです。以前にパフォーマンステストを行ったことがある場合、これはおそらく古い帽子です。練習に慣れていない方のために、私が従うプロセスを順を追って説明します。「どちらの方法が優れているか」に対する答えを導き出す方法はたくさんあることを理解してください。このプロセスを実行し、微調整して、時間をかけて自分のものにすることを期待しています。
何を証明しようとしていますか?
最初のステップは、何をテストするかを正確に決定することです。私たちの場合、それは簡単です。空のテーブルにデータをロードしてからインデックスを追加する方が速いのでしょうか、それともデータのロード中にテーブルにインデックスを設定する方が速いのでしょうか。ただし、必要に応じて、ここにバリエーションを追加できます。データをヒープにロードしてからクラスター化インデックスと非クラスター化インデックスを作成するのにかかる時間と、データをクラスター化インデックスにロードしてから非クラスター化インデックスを作成するのにかかる時間を考慮してください。パフォーマンスに違いはありますか?クラスタリングキーが要因になりますか?データの読み込みによって既存の非クラスター化インデックスが断片化することが予想されるため、読み込み後にインデックスを再構築すると、合計期間にどのような影響があるかを確認したいと思います。このステップの範囲を可能な限り限定し、何を測定するかについて非常に具体的にすることが重要です。これにより、キャプチャするデータが決まります。この例では、4つのテストは次のようになります。
テスト1: データをヒープにロードし、クラスター化インデックスを作成し、非クラスター化インデックスを作成します
テスト2: クラスター化インデックスにデータをロードし、非クラスター化インデックスを作成します
テスト3: クラスター化インデックスと非クラスター化インデックスを作成し、データを読み込みます
テスト4: クラスター化インデックスと非クラスター化インデックスを作成し、データをロードし、非クラスター化インデックスを再構築します
何を知っておく必要がありますか?
私たちのシナリオでは、私たちの主な質問は「どの方法が最も速いか」です。したがって、期間を測定する必要があります。そのためには、開始時刻と終了時刻を取得する必要があります。そのままにしておくこともできますが、各メソッドのリソース使用率がどのように見えるかを理解したい場合や、最大待機時間、トランザクション数、デッドロック数を知りたい場合があります。最も興味深く関連性のあるデータは、比較しているプロセスによって異なります。トランザクション数を取得することは、データのロードにとってそれほど興味深いことではありません。しかし、コード変更の場合はそうかもしれません。インデックスを作成して再構築しているので、各メソッドが生成するIOの量に関心があります。全体的な期間が最終的に決定的な要因になる可能性がありますが、IOを調べることは、どのオプションが最も多くのIOを生成するかだけでなく、データベースストレージが期待どおりに実行されているかどうかを理解するのに役立つ場合があります。
必要なデータはどこにありますか?
必要なデータを決定したら、それをどこからキャプチャするかを決定します。期間に関心があるため、各データ負荷テストの開始時刻と終了時刻を記録します。 IOにも関心があり、このデータを複数の場所から取得できます。パフォーマンスモニターカウンターとsys.dm_io_virtual_file_statsDMVが思い浮かびます。
このデータを手動で取得できることを理解してください。テストを実行する前に、sys.dm_io_virtual_file_statsに対して選択し、現在の値をファイルに保存できます。時間を記録してから、テストを開始できます。終了したら、時間をもう一度記録し、sys.dm_io_virtual_file_statsに再度クエリを実行し、値間の差を計算してIOを測定します。
この方法論には多くの欠陥があります。つまり、エラーの余地がかなり残っているということです。開始時刻をメモするのを忘れた場合、または開始する前にファイル統計をキャプチャするのを忘れた場合はどうなりますか?はるかに優れた解決策は、スクリプトの実行だけでなく、データのキャプチャも自動化することです。たとえば、テスト情報(テストの内容、テストの開始時刻、および完了時刻の説明)を保持するテーブルを作成できます。同じテーブルにファイル統計を含めることができます。他のメトリックを収集している場合は、それらをテーブルに追加できます。または、キャプチャするデータセットごとに個別のテーブルを作成する方が簡単な場合もあります。たとえば、ファイル統計データを別のテーブルに保存する場合、テストを適切なファイル統計データと照合できるように、各テストに一意のIDを指定する必要があります。ファイル統計をキャプチャするときは、開始前と開始後にデータベースの値をキャプチャして、差を計算する必要があります。次に、その情報を一意のテストIDとともに独自のテーブルに保存できます。
サンプル演習
このテストでは、Sales.Big_SalesOrderHeaderという名前のSales.SalesOrderHeaderテーブルの空のコピーを作成し、パーティショニングポストで使用したスクリプトのバリエーションを使用して、約25,000行のバッチでデータをテーブルにロードしました。ここからデータロードのスクリプトをダウンロードできます。バリエーションごとに4回実行し、挿入された行の総数も変更しました。最初のテストセットでは2,000万行を挿入し、2番目のセットでは6,000万行を挿入しました。期間データは驚くべきことではありません:
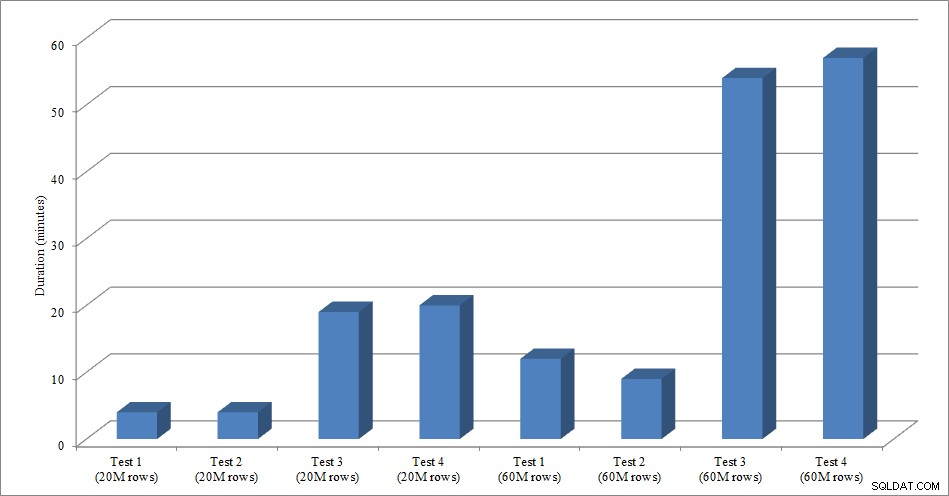
非クラスター化インデックスを使用せずにデータをロードする方が、非クラスター化インデックスを既に配置した状態でデータをロードするよりもはるかに高速です。私が興味深いと思ったのは、2,000万行のロードの場合、合計期間はテスト1とテスト2の間でほぼ同じでしたが、テスト2は6,000万行をロードしたときの方が速かったことです。テストでは、クラスタリングキーはSalesOrderIDでした。これは、IDであるため、昇順であるため、負荷に適したクラスタリングキーです。代わりにGUIDであるクラスタリングキーがある場合、ランダムな挿入とページ分割(テストできる別のバリエーション)のために、読み込み時間が長くなる可能性があります。
IOデータは期間データの傾向を模倣していますか?はい、インデックスがすでに配置されているかどうかにかかわらず、違いはさらに誇張されています:
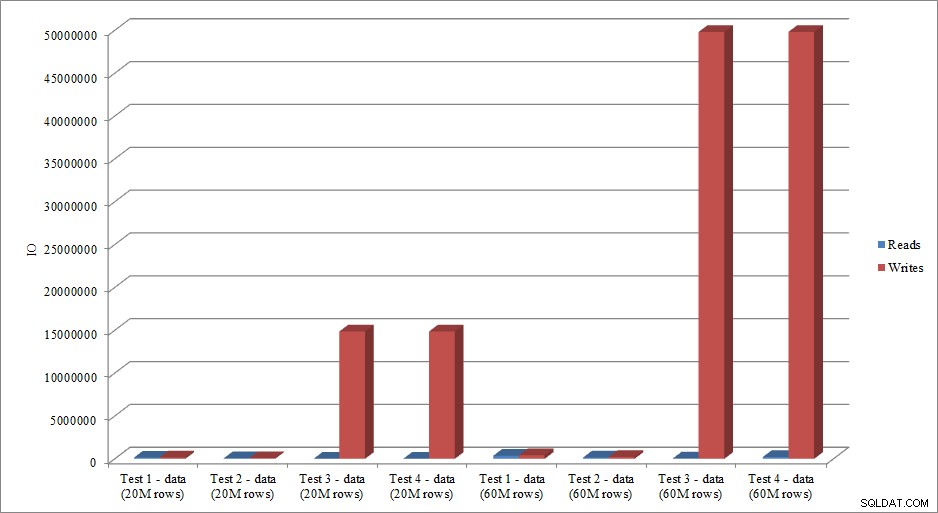
パフォーマンステスト、またはコードや設計などの変更に基づくパフォーマンスの変化の測定のためにここで紹介した方法は、ベースライン情報を取得するための1つのオプションにすぎません。シナリオによっては、これはやり過ぎかもしれません。調整しようとしているクエリが1つある場合、データをキャプチャするようにこのプロセスを設定すると、クエリを微調整するよりも時間がかかる場合があります。クエリの調整をある程度行った場合は、おそらく、クエリプランとともにSTATISTICSIOおよびSTATISTICSTIMEデータをキャプチャし、変更を加えながら出力を比較する習慣があります。私はこれを何年も行ってきましたが、最近、より良い方法を発見しました…SQL SentryPlanExplorerPRO。実際、上記のすべての負荷テストを完了した後、PEを介してテストを実行し直したところ、データ収集テーブルを設定しなくても、必要な情報を取得できることがわかりました。
Plan Explorer PROには、実際のプランを取得するオプションがあります。PEは、選択したインスタンスとデータベースに対してクエリを実行し、プランを返します。これにより、PEが提供する他のすべての優れたデータ(時間統計、読み取りと書き込み、テーブルごとのIO)と、待機統計を取得できます。これは素晴らしいメリットです。この例を使用して、最初のテスト(ヒープの作成、データのロード、クラスター化インデックスと非クラスター化インデックスの追加)から開始し、[実際の計画を取得]オプションを実行しました。それが完了したら、スクリプトテスト2を変更し、[実際の計画を取得]オプションを再度実行しました。 3回目と4回目のテストでこれを繰り返しましたが、終了すると次のようになりました。
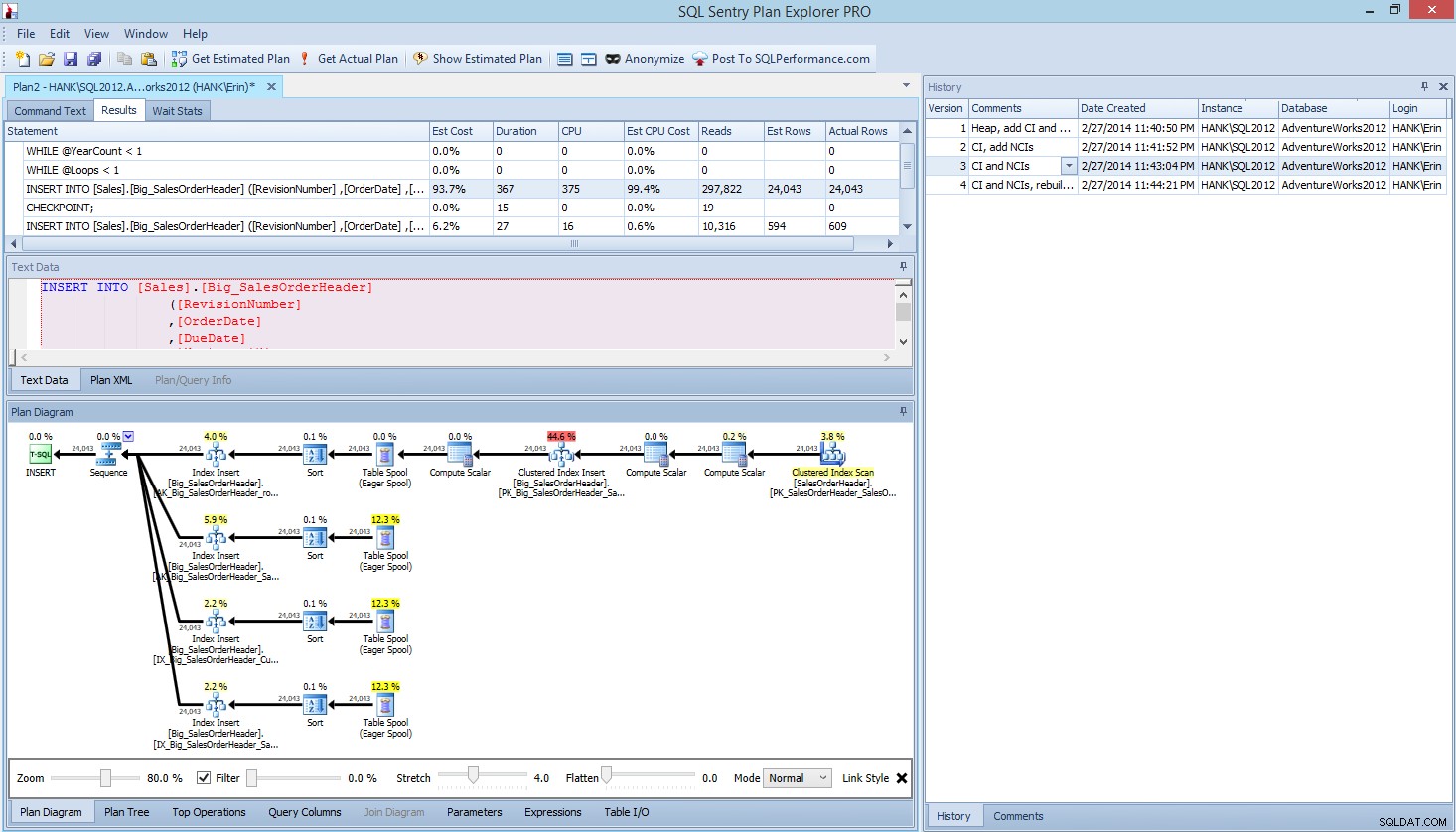
4つのテストを実行した後のPlanExplorerPROビュー>
右側の履歴ペインに注目してください。コードを変更して実際の計画を再取得するたびに、新しい情報セットが保存されました。このデータを.pesessionファイルとして保存して、チームの他のメンバーと共有したり、後で戻ってさまざまなテストをスクロールしたり、必要に応じてバッチ内のさまざまなステートメントにドリルダウンしたりして、次のようなさまざまな指標を確認することができます。期間、CPU、およびIOとして。上のスクリーンショットでは、テスト3のINSERTを強調表示しており、クエリプランには4つの非クラスター化インデックスすべての更新が示されています。
概要
SQL Serverの非常に多くのタスクと同様に、パフォーマンステストを実行しているとき、またはチューニングを実行しているときに、データをキャプチャして確認する方法はたくさんあります。実際に変更を加え、影響を理解してから次のタスクに進むための時間が長くなるため、手作業を少なくするほどよいでしょう。スクリプトをカスタマイズしてデータをキャプチャする場合でも、サードパーティのユーティリティにデータをキャプチャさせる場合でも、概説した手順は引き続き有効です。
- 改善したいものを定義する
- テストの範囲
- 改善を測定するために使用できるデータを決定する
- データの取得方法を決定する
- テストとキャプチャのために、可能な限り自動化された方法を設定します
- 必要に応じてテスト、評価、繰り返し
ハッピーテスト!