IRIは現在、無料のデータベースとフラットファイルプロファイリングツールの両方で、データ品質、セキュリティ、MDM機能を強化するために、IRI CoSort、FieldShield、Voracityで利用可能なフィールド関数ライブラリとしてあいまい検索機能も提供しています。これは、データ品質改善への適用をカバーするIRIあいまい検索ソリューションに関する一連の記事の最初の記事です。
はじめに
IRIらがデータおよび企業情報管理のコンテキストで話している大きな「V」ワードの1つのデータの信憑性または信頼性(量、多様性、速度、および価値とともに)。一般に、IRIは、疑わしいデータを次の1つ以上の属性を持つものとして定義します。
- 一貫性がない、不正確、または不完全であるため、品質が低い
- 曖昧(MDMと考える)、不正確(構造化されていない)、または欺瞞的(ソーシャルメディア)
- 偏った(調査の質問)、騒々しい(余分な、または汚染された)、または異常な(外れ値)
- その他の理由で無効です(データはその使用目的に対して正確で正確ですか?)
- 安全ではありません– PIIまたはシークレットが含まれていますか?また、適切にマスクされているか、リバーシブルであるかなどですか?
この記事では、最初の問題であるデータ品質に対する新しいあいまい検索ソリューションのみに焦点を当てます。このブログの他の記事では、IRIソフトウェアが他の4つの真実性の問題にどのように対処するかについて説明しています。できない場合は、それらを見つけるための助けを求めてください。
あいまい検索について
ファジー検索では、他の単語やフレーズ(値)と類似しているが、必ずしも同一であるとは限らない単語やフレーズ(値)が検索されます。このタイプの検索には、シーケンスエラー、スペルエラー、転置された文字など、後で説明するその他の検索など、多くの用途があります。
おおよその単語やフレーズをあいまい検索すると、以前に保存したデータと重複している可能性のあるデータを見つけるのに役立ちます。ただし、ユーザー入力または自動修正により、レコードが独立しているように見えるようにデータが変更された可能性があります。
この記事の残りの部分では、IRIが現在サポートしている4つのファジー検索機能、それらを使用してデータを検索し、検索値に近いレコードを返す方法について説明します。
1。レーベンシュタイン
レーベンシュタインアルゴリズムは、2つの単語またはフレーズを取得し、1つの単語またはフレーズを別の単語またはフレーズに変換するために必要な編集ステップの数をカウントすることで機能します。実行する手順が少ないほど、単語またはフレーズが一致する可能性が高くなります。レーベンシュタイン関数が実行できる手順は次のとおりです。
- 単語やフレーズへの文字の挿入
- 単語またはフレーズからの文字の削除
- 単語またはフレーズの1つの文字を別の文字に置き換える
以下は、レーベンシュタインあいまい検索機能の使用方法を示すCoSort SortCLプログラム(ジョブスクリプト)です。
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
目的の出力を生成するために使用する必要がある2つの部分があります。
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
この行は関数fs_levenshteinを呼び出し、結果をフィールドFS_RESULTに保存します。この関数は2つの入力パラメーターを取ります:
- あいまい検索を実行するフィールド(この例ではNAME)
- 入力フィールドが比較される文字列(この例では「BarneyOakley」)。
/INCLUDE WHERE FS_RESULT GT 50
この行は、FS_RESULTフィールドを比較し、それが50より大きいかどうかをチェックし、FS_RESULTが50を超えるレコードのみが出力されます。以下に、この例の出力を示します。

出力が示すように、このタイプの検索は検索に役立ちます:
- 連結された名前
- ノイズ
- スペルミス
- 転置された文字
- 文字起こしの間違い
- 入力エラー
したがって、レーベンシュタイン関数は、一般的なデータ入力エラーを特定するのにも役立ちます。ただし、1つの文字列のすべての文字を他の文字列のすべての文字と比較するため、4つのアルゴリズムのうち実行に最も時間がかかります。
2。ダイス係数
サイコロ係数、またはサイコロアルゴリズムは、単語またはフレーズを文字のペアに分割し、それらのペアを比較して、一致をカウントします。単語の一致が多いほど、単語自体が一致する可能性が高くなります。
次のSortCLスクリプトは、ダイス係数のあいまい検索機能を示しています。
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
目的の出力を得るには、2つの部分を使用する必要があります。
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
この行は関数fs_diceを呼び出し、結果をフィールドFS_RESULTに保存します。この関数は2つの入力パラメーターを取ります:
- あいまい検索を実行するフィールド(この例ではNAME)。
- 入力フィールドが比較される文字列(この例では「RobertThomasSmith」)。
/INCLUDE WHERE FS_RESULT GT 50
この行は、FS_RESULTフィールドを比較し、それが50より大きいかどうかをチェックし、FS_RESULTが50を超えるレコードのみが出力されます。以下に、この例の出力を示します。
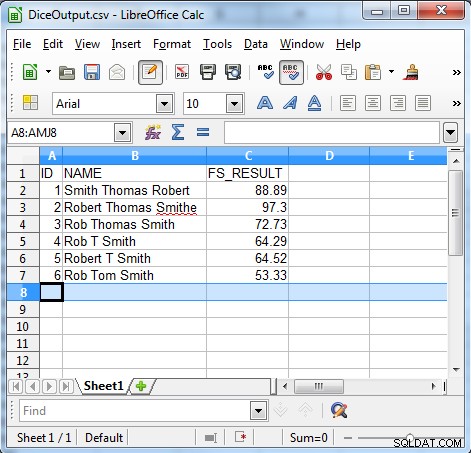
出力が示すように、ダイス係数アルゴリズムは、次のような一貫性のないデータを見つけるのに役立ちます。
- シーケンスエラー
- 非自発的な修正
- ニックネーム
- イニシャルとニックネーム
- 予測できないイニシャルの使用
- ローカリゼーション
サイコロのアルゴリズムはレーベンシュタインよりも高速ですが、タイプミスなどの単純なエラーが多い場合は精度が低下する可能性があります。
3。 Metaphoneと4.Soundex
MetaphoneとSoundexのアルゴリズムは、音声に基づいて単語やフレーズを比較します。 Soundexは単語やフレーズを読み、個々の文字を調べることでこれを行いますが、Metaphoneは個々の文字と文字グループの両方を調べます。次に、両方が単語の綴りと発音に基づいてコードを与えます。
次のSortCLスクリプトは、SoundexおよびMetasphoneの検索機能を示しています。
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
いずれの場合も、目的の出力を得るには3つの部分を使用する必要があります。
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
この行は関数を呼び出し、結果をフィールドRESULTに格納します。関数は両方とも2つの入力パラメータを取ります:
- あいまい検索を実行するフィールド(この例ではNAME)
- 入力フィールドが比較されるxtring(この例では「John」)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
この行は、SE_RESULTフィールドとMP_RESULTフィールドを比較し、どちらかが0より大きい場合に行をチェックして返します。
Soundexは、一致する場合は100を返し、一致しない場合は0を返します。 Metaphoneの結果はより具体的で、強い一致の場合は100、通常の一致の場合は66、マイナーな一致の場合は33を返します。
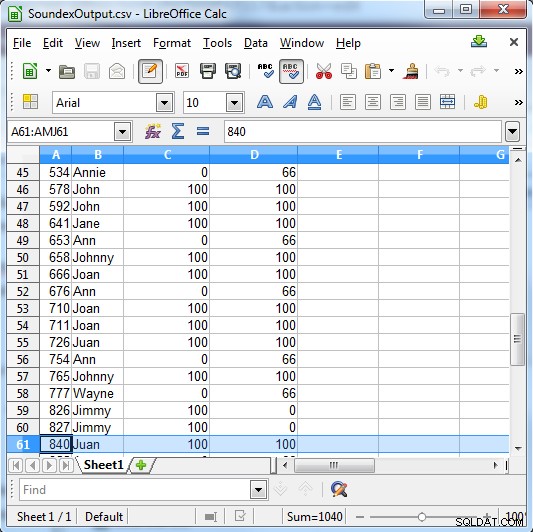
列C Soundexの結果を示しています。 C olumn D メタフォンの結果を表示します
出力が示すように、このタイプの検索は検索に役立ちます:
- ふりがな
以下のこの記事に関するフィードバックを送信してください。これらの機能の使用に興味がある場合は、IRIの担当者にお問い合わせください。 IRI Workbenchのデータ統合(品質)ウィザードでのこれらのアルゴリズムの使用に関する次の記事を参照してください。