私たちは皆、つづりの間違い、名前のつづりの違い、または著者が単語の別のつづりを使用することを好むページで検索語が一致する可能性があるその他の状況などを「回避」する検索エンジンの能力に甘んじてきました。このような機能を独自のデータベース駆動型アプリケーションに追加すると、同様にアプリケーションを強化および強化できます。商用リレーショナルデータベース管理システム(RDBMS)製品は、この問題に対して独自に開発されたカスタマイズされたソリューションを提供しますが、これらのツールのライセンスコストは小規模な開発者や小規模なソフトウェア開発会社にリーチします。
代わりにスペルチェッカーを使用してこれを行うことができると主張することができます。ただし、スペルチェッカーは通常、名前や他の単語の正しい、しかし代替のスペルを照合する場合には役に立ちません。音によるマッチングは、この機能的なギャップを埋めます。これが、今日のプログラミングチュートリアルのトピックです。つまり、メタフォンを使用してPythonでサウンドをクエリする方法です。
Soundexとは何ですか?
Soundex 20世紀初頭に、米国国勢調査が音の響きに基づいて名前を照合する手段として開発されました。その後、さまざまな電話会社が顧客名を照合するために使用しました。アメリカ英語のスペルと発音に限定されているにもかかわらず、今日まで音声データのマッチングに使用され続けています。また、英字に限定されています。 SQL ServerやOracleなどのほとんどのRDBMSは、MySQLとそのバリアントとともに、Soundex関数を実装しており、その制限にもかかわらず、英語以外の多くの単語との照合に引き続き使用されます。
ダブルメタフォンとは何ですか?
メタフォン アルゴリズムは1990年に開発され、Soundexの制限のいくつかを克服しています。 2000年には、改良された後続のダブルメタフォン 、開発されました。 Double Metaphoneは、1つの単語を発音できる2つの方法に対応する1次値と2次値を返します。今日まで、このアルゴリズムは、より優れたオープンソースの音声アルゴリズムの1つです。 Metaphone 3は、Double Metaphoneの改良版として2009年にリリースされましたが、これは商用製品です。
残念ながら、上記の著名なRDBMSの多くは、Double Metaphoneを実装しておらず、ほとんど 著名なスクリプト言語は、サポートされているDoubleMetaphoneの実装を提供していません。ただし、PythonはDoubleMetaphoneを実装するモジュールを提供します。
このPythonプログラミングチュートリアルで紹介する例では、MariaDBバージョン10.5.12とPython 3.9.2を使用しており、どちらもKali /DebianLinuxで実行されています。
Pythonにダブルメタフォンを追加する方法
他のPythonモジュールと同様に、pipツールを使用してDoubleMetaphoneをインストールできます。構文はPythonのインストールによって異なります。一般的なDoubleMetaphoneのインストールは、次の例のようになります。
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
追加の大文字化は意図的なものであることに注意してください。次のコードは、PythonでDoubleMetaphoneを使用する方法の例です。
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
上記のPythonスクリプトは、統合開発環境(IDE)またはコードエディターで実行すると、次の出力を提供します。
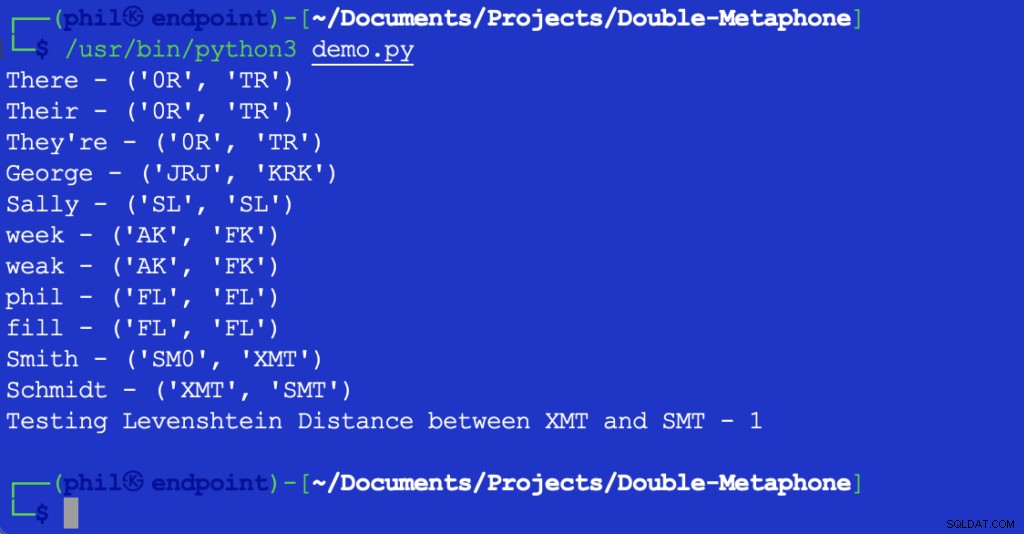
図1-デモスクリプトの出力
ここでわかるように、各単語には一次音声値と二次音声値の両方があります。一次値または二次値の両方で一致する単語は、音声一致と呼ばれます。少なくとも1つの音声値を共有する単語、または任意の音声値の最初の2文字を共有する単語は、音声的に互いに近いと言われます。
ほとんど 表示される文字は英語の発音に対応しています。 X KSに対応できます 、 SH 、または C 。 0 番目に対応 の音 またはあり 。母音は単語の先頭でのみ一致します。地域のアクセントには数え切れないほどの違いがあるため、同じ音声値であっても、単語が客観的に完全に一致する可能性があるとは言えません。
音声値とPythonの比較
DoubleMetaphoneアルゴリズムの完全な動作を説明できるオンラインリソースは多数あります。ただし、比較に関心があるため、これを使用するためにこれは必要ありません。 計算された値は、値の計算に関心がある以上のものです。前述のように、2つの単語に共通する値が少なくとも1つある場合、これらの値は音声一致であると言えます。 、および類似である音声値 音声的に近い 。
絶対値の比較は簡単ですが、文字列が類似しているとどのように判断できますか?複数の単語の文字列を比較することを妨げる技術的な制限はありませんが、これらの比較は通常信頼できません。単一の単語の比較に固執します。
レーベンシュタイン距離とは何ですか?
レーベンシュタイン距離 2つの文字列の間は、2番目の文字列と一致させるために1つの文字列で変更する必要がある単一の文字の数です。レーベンシュタイン距離が短い弦のペアは、レーベンシュタイン距離が長い弦のペアよりも互いに類似しています。レーベンシュタイン距離はハミング距離に似ています 、ただし後者は同じ長さの文字列に制限されます。DoubleMetaphoneの音声値は長さが異なる可能性があるため、レーベンシュタイン距離を使用してこれらを比較する方が理にかなっています。
Pythonレーベンシュタイン距離ライブラリ
Pythonを拡張して、Pythonモジュールを介したレーベンシュタイン距離の計算をサポートできます。
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
DoubleMetaphone のインストールと同様に、注意してください 上記のpipの呼び出しの構文 異なる場合があります。 python-Levenshteinモジュールは、レーベンシュタイン距離の計算よりもはるかに多くの機能を提供します。
以下のコードは、Pythonでのレーベンシュタイン距離計算のテストを示しています。
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
このスクリプトを実行すると、次の出力が得られます。
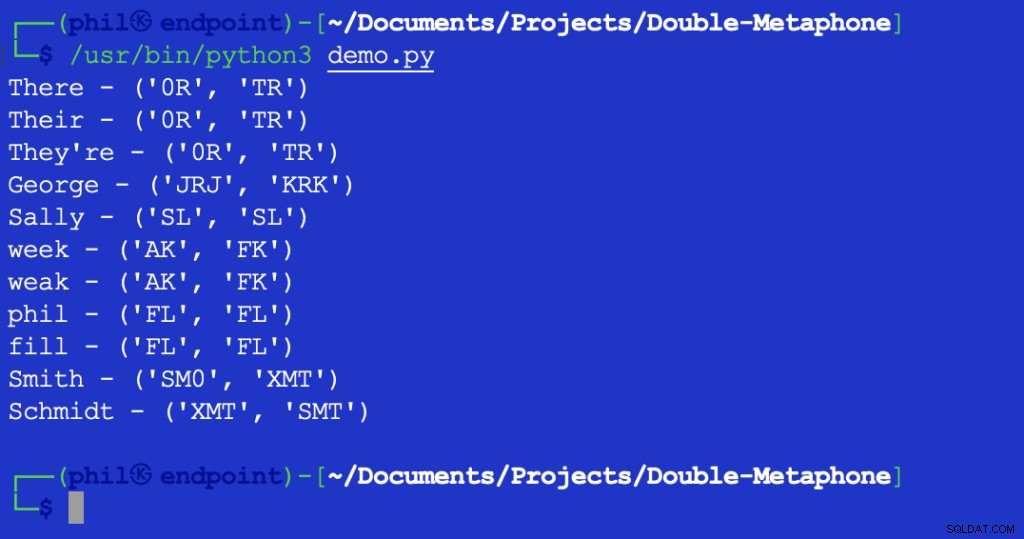
図2–レーベンシュタイン距離テストの出力
1の戻り値 XMTの間に1文字あることを示します およびSMT それは違います。この場合、それは両方の文字列の最初の文字です。
Pythonでのダブルメタフォンの比較
以下は、音声比較のすべてではありません。これは、このような比較を実行するための多くの方法の1つにすぎません。任意の2つの文字列の音声の近さを効果的に比較するには、ある文字列の各Double Metaphoneの音声値を、別の文字列の対応するDoubleMetaphoneの音声値と比較する必要があります。特定の文字列の両方の音声値に等しい重みが与えられるため、これらの比較値の平均により、音声の近さをかなり適切に近似できます。
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
場所:
- DM1(1) :文字列1の最初のダブルメタフォン値
- DM1(2) :文字列1の2番目のダブルメタフォン値
- DM2(1) :文字列2の最初のダブルメタフォン値
- DM2(2) :文字列2の2番目のダブルメタフォン値
- PN :音声的近さ。低い値は高い値よりも近くなります。ゼロ値は、音声の類似性を示します。これの最大値は、最短の文字列の文字数です。
この式は、 Schmidt(XMT、SMT)のような場合に分類されます。 およびSmith(SM0、XMT) ここで、最初の文字列の最初の音声値は、2番目の文字列の2番目の音声値と一致します。このような状況では、両方のシュミット およびスミス 共有価値のため、音声的に類似していると見なすことができます。近さ関数のコードは、4つの音声値がすべて異なる場合にのみ上記の式を適用する必要があります。異なる長さの文字列を比較する場合にも、数式には弱点があります。
2つの弦の間のレーベンシュタイン距離を計算すると弦の長さの違いが考慮されますが、長さが異なる弦を比較するための非常に効果的な方法はないことに注意してください。考えられる回避策は、両方の文字列を2つの文字列のうち短い方の長さまで比較することです。
以下は、上記のコードを実装するサンプルコードスニペットといくつかのテストサンプルです。
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
サンプルのPythonコードは、次の出力を提供します。
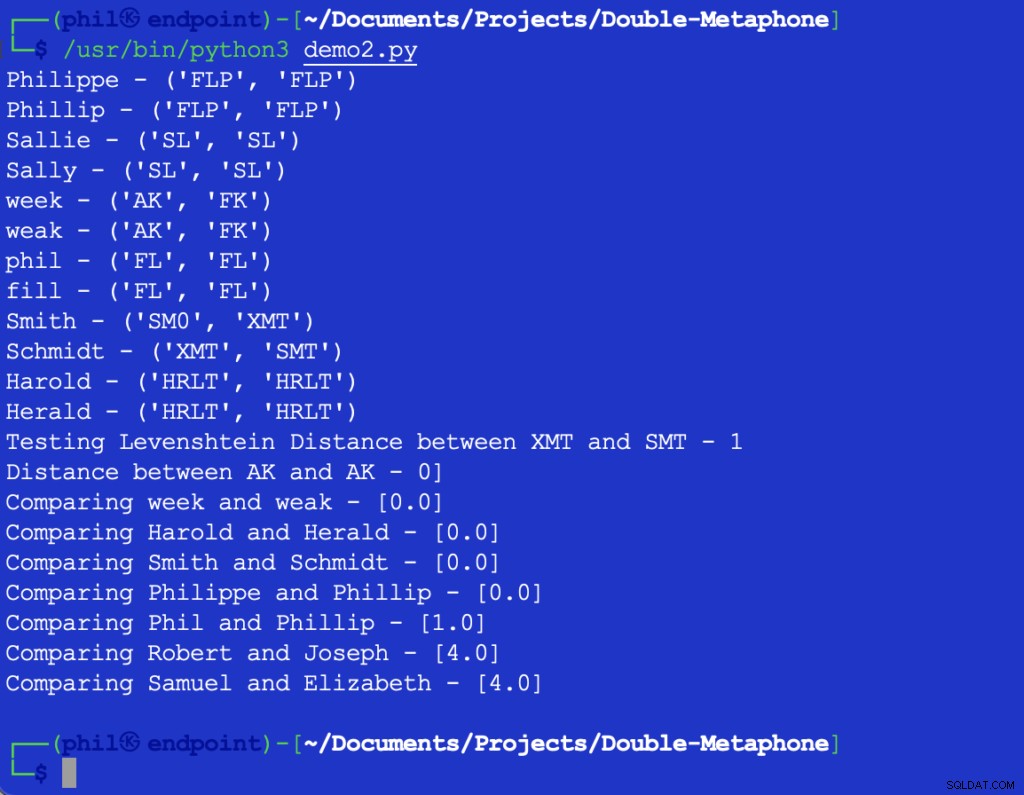
図3–近さアルゴリズムの出力
サンプルセットは、単語の違いが大きいほど、近さの出力が高くなるという一般的な傾向を確認しています。 機能。
Pythonでのデータベース統合
上記のコードは、特定のRDBMSとDoubleMetaphoneの実装との間の機能的なギャップを破っています。さらに、近さを実装することで Pythonで機能するため、別の比較アルゴリズムが必要な場合は簡単に置き換えることができます。
次のMySQL/MariaDBテーブルについて考えてみます。
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
ほとんどのデータベース駆動型アプリケーションでは、ミドルウェアはデータの挿入を含むデータを管理するためのSQLステートメントを作成します。次のコードは、このテーブルにいくつかのサンプル名を挿入しますが、実際には、そのようなデータを収集するWebまたはデスクトップアプリケーションからのコードは同じことを行うことができます。
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
このコードを実行しても何も出力されませんが、次に使用するリストのためにデータベースのテストテーブルにデータが入力されます。 MySQLクライアントでテーブルを直接クエリすると、上記のコードが機能したことを確認できます。
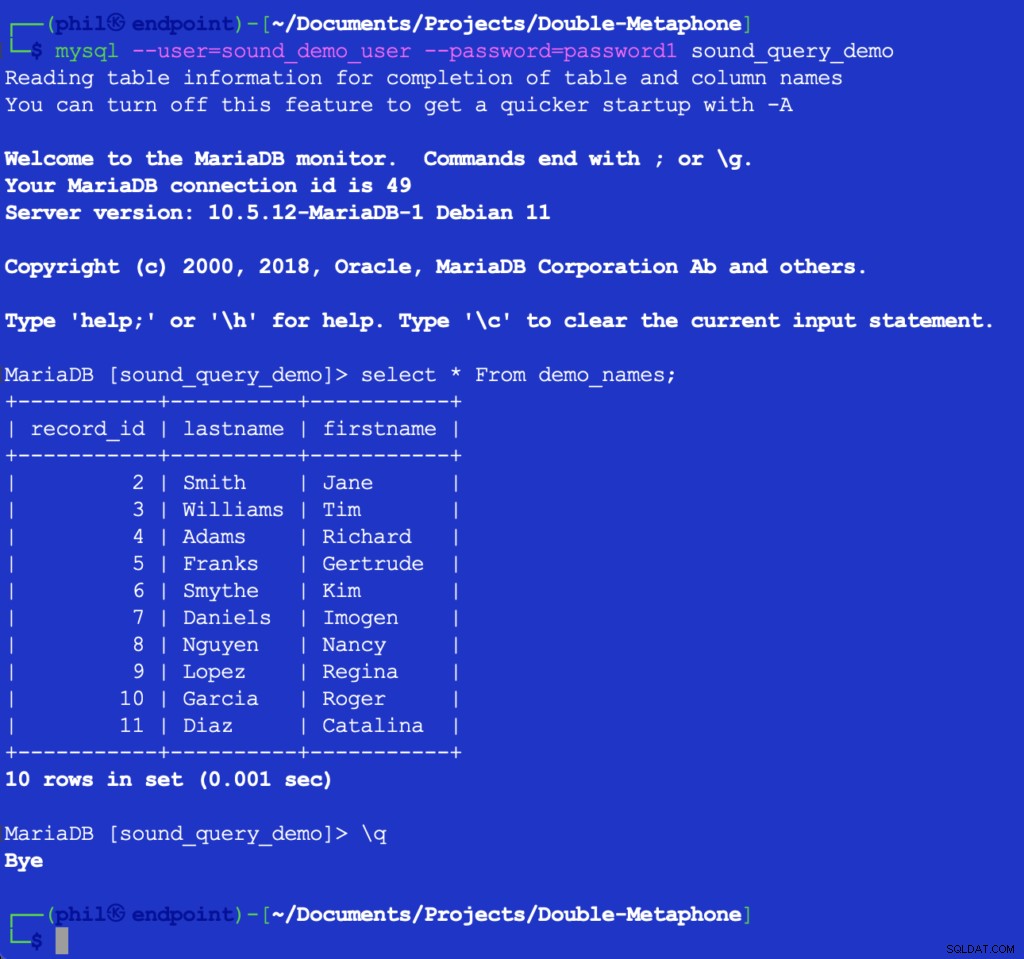
図4-挿入されたテーブルデータ
以下のコードは、いくつかの比較データを上記のテーブルデータにフィードし、それに対して近接比較を実行します。
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
このコードを実行すると、以下の出力が得られます:
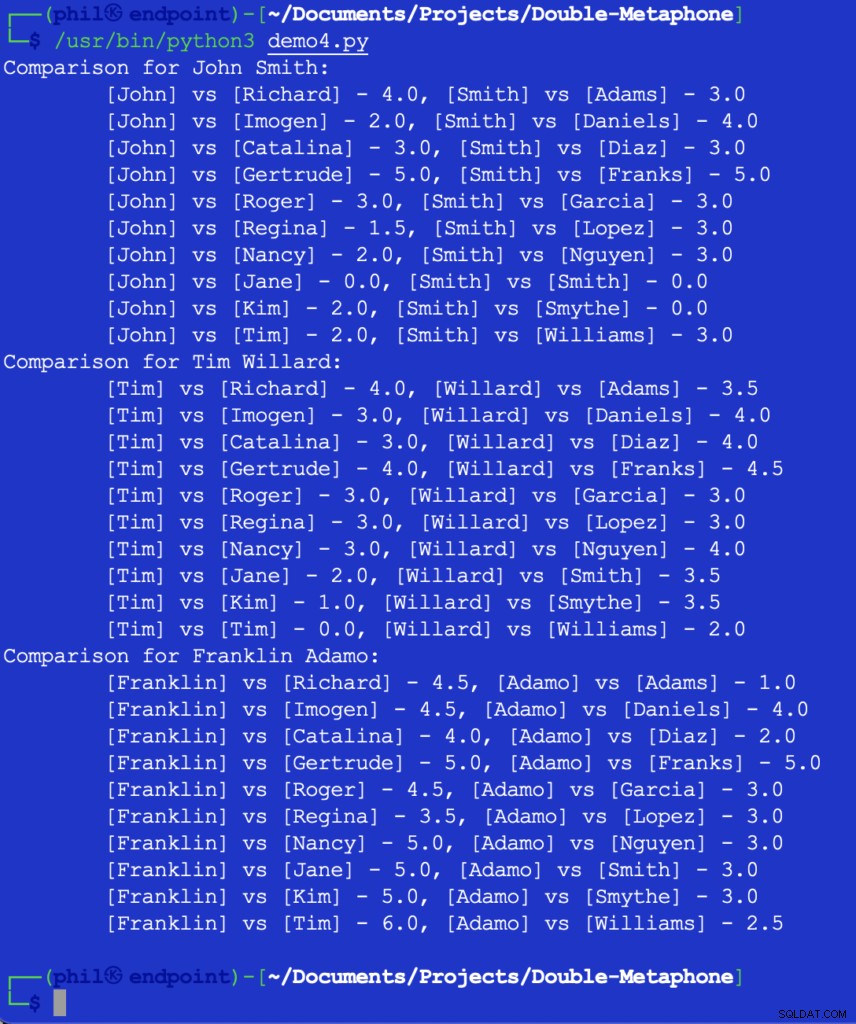
図5–近さの比較の結果
この時点で、有用な比較を構成するもののしきい値を決定するのは開発者の責任です。上記の数字のいくつかは予想外または意外に思われるかもしれませんが、コードへの1つの可能な追加は IFである可能性があります 2より大きい比較値を除外するステートメント 。
ふりがな自体はデータベースに保存されないことに注意してください。これは、Pythonコードの一部として計算され、プログラムの終了時に破棄されるため、実際にはどこにも保存する必要がないためです。ただし、開発者は、これらをデータベースに保存してから比較を実装することに価値を見いだす可能性があります。データベース内のストアドプロシージャの機能。ただし、これの1つの大きな欠点は、コードの移植性が失われることです。
Pythonを使用したサウンドによるデータのクエリに関する最終的な考え
音でデータを比較することは、画像分析でデータを比較することのような「愛」や注意を引くようには見えませんが、アプリケーションが複数の言語の単語の複数の類似した音のバリエーションを処理する必要がある場合、それは非常に便利です。道具。このタイプの分析の有用な機能の1つは、開発者がこれらのツールを使用するために言語学または音声学の専門家である必要がないことです。開発者は、そのようなデータを比較する方法を定義する際にも大きな柔軟性を持っています。比較は、アプリケーションまたはビジネスロジックのニーズに基づいて調整できます。
うまくいけば、この研究分野は研究分野でより注目を集め、今後はより有能で堅牢な分析ツールが登場するでしょう。