この記事では、HAVING句の概念とSQLでの使用方法について学習します。
HAVING句とは何ですか?
構造化照会言語では、GROUP BY句とともに使用されるHAVING句は、出力に表示される結果をフィルタリングする条件を指定します。条件を満たすグループからのデータのみを返します。
HAVING句を使用すると、クエリでもWHERE句を使用できます。両方の句を一緒に使用する場合、WHERE句が最初に実行され、個々の行がフィルタリングされ、次に行がグループ化され、最後にHAVING句がグループをフィルタリングします。
HAVING句の条件は、GROUPBY句の後に配置されます。 HAVING句は、構造化照会言語のWHERE句と同じように動作し、GROUPBY句を使用しません。 MIN、MAX、SUM、AVG、COUNTなどの集計関数を使用できます。この関数は、SELECT句とHAVING句でのみ使用されます。
HAVING句の構文:
SELECT COLUMNS, AGGREGATE FUNCTION, FROM TABLENAME WHERE CONDITION GROUP BY COLUMN HAVING CONDITIONS; SQLクエリでHAVING句を使用する方法については、いくつかの手順を学ぶ必要があります。
1。 USEキーワードに続けてデータベース名を使用してデータベースを選択することにより、新しいデータベースを作成するか、既存のデータベースを使用します。
2。 選択したデータベース内に新しいテーブルを作成するか、作成済みのテーブルを使用できます。
3。 テーブルが新しく作成された場合は、INSERTクエリを使用して新しく作成されたデータベースにレコードを挿入し、HAVING句を指定せずにSELECTクエリを使用して挿入されたデータを表示します。
4。 これで、SQLクエリでHAVING句を使用する準備が整いました。
ステップ1:新しいデータベースを作成するか、作成済みのデータベースを使用します。
私はすでにデータベースを作成しました。既存の作成したデータベース名を使用します。
USE SCHOOL;
学校はデータベース名です。
データベースを作成していない場合は、次のクエリに従ってデータベースを作成してください。
CREATE DATABASE database_name;
データベースを作成したら、USEキーワードに続けてデータベース名を使用してデータベースを選択します。
ステップ2:新しいテーブルを作成するか、既存のテーブルを使用します:
すでにテーブルを作成しました。 Studentという名前の既存のテーブルを使用します。
新しいテーブルを作成するには、以下のCREATETABLE構文に従います。
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
ステップ3:INSERTクエリを使用して新しく作成されたテーブルにレコードを挿入し、SELECTクエリを使用してレコードを表示します。
以下の構文を使用して、テーブルに新しいレコードを挿入します。
INSERT INTO table_name VALUES(value1, value2, value3);以下の構文を使用してテーブルからレコードを表示するには:
SELECT * FROM table_name;
次のクエリは、従業員のレコードを表示します
SELECT * FROM Student;
上記のSELECTクエリの出力は次のとおりです。
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | CHEMISTRY_MARKS | MATHS_MARKS | TOTAL_MARKS |
| 1 | NEHA | 85 | 88 | 100 | 273 |
| 2 | VISHAL | 70 | 90 | 82 | 242 |
| 3 | SAMKEET | 75 | 88 | 96 | 259 |
| 4 | NIKHIL | 60 | 75 | 80 | 215 |
| 5 | YOGESH | 56 | 65 | 78 | 199 |
| 6 | アンキタ | 95 | 85 | 96 | 276 |
| 7 | ソナム | 98 | 89 | 100 | 287 |
| 8 | VINEET | 85 | 90 | 100 | 275 |
| 9 | SANKET | 86 | 78 | 65 | 229 |
| 10 | PRACHI | 90 | 80 | 75 | 245 |
ステップ4:構造化照会言語でHAVING句を使用する準備ができました。
次に、例を使用してHAVING句について詳しく説明します。
次のレコードを含むStudentという名前のテーブルがあります。
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | CHEMISTRY_MARKS | MATHS_MARKS | TOTAL_MARKS |
| 1 | NEHA | 85 | 88 | 100 | 273 |
| 2 | VISHAL | 70 | 90 | 82 | 242 |
| 3 | SAMKEET | 75 | 88 | 96 | 259 |
| 4 | NIKHIL | 60 | 75 | 80 | 215 |
| 5 | YOGESH | 56 | 65 | 78 | 199 |
| 6 | アンキタ | 95 | 85 | 96 | 276 |
| 7 | ソナム | 98 | 89 | 100 | 287 |
| 8 | VINEET | 85 | 90 | 100 | 275 |
| 9 | SANKET | 86 | 78 | 65 | 229 |
| 10 | PRACHI | 90 | 80 | 75 | 245 |
例1: 物理マークの合計が学生IDで60グループを超える場合に、物理マークの合計を表示するクエリを記述します。
SELECT STUDENT_ID, STUDENT_NAME, SUM(PHYSICS_MARKS) AS PHYSICS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING SUM(PHYSICS_MARKS) > 60;上記のクエリでは、SUM()という名前の集計関数に続いて、列名physics_marksを取得しました。これにより、列が合計されます。最初にSum(physics_marks)が実行され、最後にHAVING句の条件が実行され、最終結果が表示されます。 GROUP BY句の後に列名Student_Idを使用して、同じ値をグループ化し、それらを1つのグループと見なしました。値が同じでない場合、値のグループは形成されません。最後に、HAVING句を使用して、物理マークの合計が60より大きい学生の詳細のみを表示するのに役立つ条件を設定しました。学生の物理マークが60未満の場合、記録。
上記のクエリの出力は次のとおりです。
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS |
| 1 | NEHA | 85 |
| 2 | VISHAL | 70 |
| 3 | SAMKEET | 75 |
| 6 | アンキタ | 95 |
| 7 | ソナム | 98 |
| 8 | VINEET | 85 |
| 9 | SANKET | 86 |
| 10 | PRACHI | 90 |
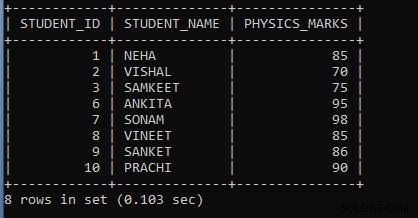
出力からわかるように、物理マークの合計が60を超える場合は、学生ID、名前、および物理マークのみが表示されます。GROUPBY句を使用し、類似する値がないため、これらは単一のグループとしてカウントされます。 。
例2: 化学マークの最大マークが学生IDで90グループ未満である場合に、化学マークの最大マークを表示するクエリを記述します。
SELECT STUDENT_ID, STUDENT_NAME, MAX(CHEMISTRY_MARKS) AS CHEMISTRY_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MAX(CHEMISTRY_MARKS) < 90; 上記のクエリでは、MAX()という名前の集計関数に続いて、列名chemistry_marksを取得しました。これにより、列の最大マークが検出されます。 GROUP BY句の後に列名Student_Idを使用して、同じ値をグループ化し、それらを1つのグループと見なしました。値が同じでない場合は、値に対して別のグループが形成されます。そして最後に、HAVING句を使用して、化学マークの最大マークが90未満の学生の詳細のみを表示するのに役立つ条件を設定しました。学生の化学マークが90を超える場合は、表示されません。レコードを表示します。最初にMAX(chemistry_marks)が実行され、最後にHAVING句の条件が実行され、最終結果が表示されます。上記のクエリの出力は次のとおりです。
| STUDENT_ID | STUDENT_NAME | CHEMISTRY_MARKS |
| 1 | NEHA | 88 |
| 3 | SAMKEET | 88 |
| 4 | NIKHIL | 75 |
| 5 | YOGESH | 65 |
| 6 | アンキタ | 85 |
| 7 | ソナム | 89 |
| 9 | SANKET | 78 |
| 10 | PRACHI | 80 |
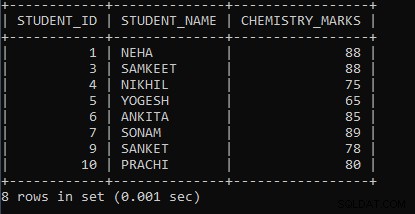
出力からわかるように、化学マークの最大マークが90未満の場合、それらの学生ID、名前、および化学マークのみが表示されます。GROUPBY句を使用し、類似する値がないため、これらは単一としてカウントされます。グループ。
例3: 数学のマークの最小マークが学生IDで70グループを超える場合に、数学のマークを表示するクエリを記述します。
SELECT STUDENT_ID, STUDENT_NAME, MIN(MATHS_MARKS) AS MATHS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MIN(MATHS_MARKS) >70;上記のクエリでは、MIN()という名前の集計関数に続いて、列名maths_marksを使用しました。これにより、列の最小マークが検出されます。 GROUP BY句の後に列名Student_Idを使用して、同じ値をグループ化し、それらを1つのグループと見なしました。値が同じでない場合は、値に対して別のグループが形成されます。そして最後に、HAVING句を使用して、数学のマークの最小マークが70より大きい生徒の詳細のみを表示するのに役立つ条件を設定しました。生徒の数学のマークが70未満の場合、表示されません。レコードを表示します。最初にMIN(maths_marks)が実行され、最後にHAVING句の条件が実行され、最終結果が表示されます。
上記のクエリの出力は次のとおりです:
| STUDENT_ID | STUDENT_NAME | MATHS_MARKS |
| 1 | NEHA | 100 |
| 2 | VISHAL | 82 |
| 3 | SAMKEET | 96 |
| 4 | NIKHIL | 80 |
| 5 | YOGESH | 78 |
| 6 | アンキタ | 96 |
| 7 | ソナム | 100 |
| 8 | VINEET | 100 |
| 10 | PRACHI | 75 |
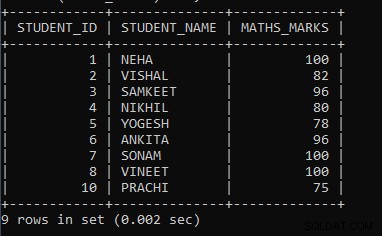
出力からわかるように、数学マークの最小マークが70より大きい場合、それらの学生ID、名前、および数学マークのみが表示されます。GROUPBY句を使用し、類似する値がないため、これらは単一としてカウントされます。グループ。
例4: 最小の物理学の点数が56を超え、最大の数学の点数が98未満である場合に、生徒の詳細を表示するクエリを作成します。
SELECT STUDENT_ID, STUDENT_NAME, MIN(PHYSICS_MARKS) AS PHYSICS_MARKS , MAX(MATHS_MARKS) AS MATHS_MARKS FROM STUDENT GROUP BY STUDENT_ID HAVING MIN(PHYSICS_MARKS) >58 AND MAX(MATHS_MARKS)<98;上記のクエリでは、単一のクエリmin()とmax()で二重集計関数を使用しました。 Min()は物理学の最小マークを見つけるために使用され、Max()は最大数学マークを見つけるために使用されます。まず、クエリは、学生のテーブルから物理学と数学のmin()とmax()のマークを見つけます。 GROUP BY句を使用したため、類似した値が1つのグループとしてマップされ、それ以外の場合、値は分離されます。表に類似する値がないため、すべての値が分離されています。値は1つのグループとしてマップされません。次に、HAVING句を使用しました。これは、グループにマップされたHAVING句のみのWHERE句の違いとして機能します。まず、条件はMIN(PHYSICS_MARKS)> 58です。類似する値がないため、各値は最小値と見なされ、条件と比較して、MAX(MATHS_MARKS)に対して同じアプローチが使用されます。クエリでAND演算子を使用したため、これらの条件は両方の条件を満たす。それらの生徒の記録のみが最終出力に表示されます。
上記のクエリの出力は次のとおりです。
| STUDENT_ID | STUDENT_NAME | PHYSICS_MARKS | MATHS_MARKS |
| 2 | VISHAL | 70 | 82 |
| 3 | SAMKEET | 75 | 96 |
| 4 | NIKHIL | 60 | 80 |
| 6 | アンキタ | 95 | 96 |
| 9 | SANKET | 86 | 65 |
| 10 | PRACHI | 90 | 75 |
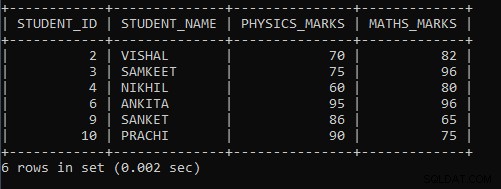
出力からわかるように、物理値の最小マークが56より大きく、最大数学マークが98未満の学生レコードのみが表示されます。
上記の例では、AND演算子の代わりにOR演算子を使用すると、10個のレコードすべてが表示されます。これは、OR演算子が、1つの条件が失敗し、他の条件が真である場合、テーブルレコードが条件を満たすと言うためです。