3年以上前に、文字列の分割に関する3部構成のシリーズを投稿しました。
- 文字列を正しい方法で分割する-または次善の方法
- 文字列の分割:フォローアップ
- 文字列の分割:T-SQLが少なくなりました
それから1月に、私はもう少し手の込んだ問題に取り組みました:
- 文字列の分割/連結方法の比較
全体を通して、私の結論は次のとおりです。T-SQLでこれを行うのをやめる 。 CLRを使用するか、DataTablesなどの構造化パラメーターをアプリケーションからプロシージャ内のテーブル値パラメーター(TVP)に渡して、すべての文字列の構築と分解を完全に回避します。これは、パフォーマンスの問題を引き起こすソリューションの一部です。
そしてSQLServer2016が登場しました…
RC0がリリースされたとき、多くのファンファーレなしで新しい関数が文書化されました:STRING_SPLIT 。簡単な例:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/ 主な機能について書いたDaveBallantyneを含む数人の同僚の目に留まりましたが、パフォーマンスの比較を拒否する最初の権利を私に提供してくれました。
これは主に学術的な演習です。これは、機能の最初の反復で大量の制限が設定されているため、多数のユースケースでは実行できない可能性があるためです。デイブと私が行った観察のリストは次のとおりです。そのうちのいくつかは、特定のシナリオでは取引を破る可能性があります。
- この関数では、データベースが互換性レベル130である必要があります;
- 1文字の区切り文字のみを受け入れます;
- 出力列(文字列内の序数位置を示す列など)を追加する方法はありません。
- 関連して、並べ替えを制御する方法はありません。オプションは任意でアルファベット順の
ORDER BY valueのみです。;
- 関連して、並べ替えを制御する方法はありません。オプションは任意でアルファベット順の
- これまでのところ、常に50の出力行を推定しています。
- DMLに使用する場合、多くの場合、テーブルスプールを取得します(Hallowe'en保護用)。
-
NULL入力すると空の結果になります; - 区切り文字が連続しているために重複や空の文字列を削除するなど、述語をプッシュダウンする方法はありません。
- 事後まで出力値に対して操作を実行する方法はありません(たとえば、多くの分割関数は
LTRIM/RTRIMを実行します または明示的な変換–STRING_SPLIT先頭のスペースなど、醜いものをすべて吐き出します。
したがって、これらの制限を公開して、パフォーマンステストに進むことができます。裏でCLRを活用する組み込み関数を備えたMicrosoftの実績を考えると( cough FORMAT() 咳 )、私はこの新しい関数がこれまでにテストした最速の方法に近づくことができるかどうかについて懐疑的でした。
文字列スプリッターを使用して、カンマで区切られた数字の文字列を区切りましょう。こうすることで、新しい友達のJSONも一緒にプレイできます。また、リストは8,000文字を超えることはできないため、MAXはありません。 型は必須であり、それらは数値であるため、Unicodeのようなエキゾチックなものを扱う必要はありません。
まず、関数を作成しましょう。そのいくつかは、上記の最初の記事から採用したものです。競争するとは思わなかったカップルを除外しました。それらをテストするための演習として読者に任せます。
数値表
これもセットアップが必要ですが、人為的な制限があるため、かなり小さなテーブルになる可能性があります。
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number); 次に、関数:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
); JSON
ストレージエンジンチームによって最初に明らかにされたアプローチに基づいて、OPENJSONの周りに同様のラッパーを作成しました 、この場合、区切り文字はコンマである必要があることに注意してください。そうでない場合は、値をネイティブ関数に渡す前に、強力な文字列置換を行う必要があります。
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); フォーマットの問題により、CHAR(91)/ CHAR(93)はそれぞれ[と]を置き換えています。
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)); CLR
Unicode、MAXをサポートしているにもかかわらず、ほぼ7年前のAdamMachanicの信頼できる分割コードをもう一度借りました。 タイプ、および複数文字の区切り文字(実際には、関数コードをまったくいじりたくないので、入力文字列は8,000文字ではなく4,000文字に制限されます):
CREATE FUNCTION dbo.SplitStrings_CLR ( @List nvarchar(MAX), @Delimiter nvarchar(255) ) RETURNS TABLE ( value nvarchar(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
一貫性を保つために、STRING_SPLITの周りにラッパーを配置しました :
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter)); ソースデータと健全性チェック
関数への入力文字列のソースとして機能するように、このテーブルを作成しました:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID(); 参考までに、50,000行がテーブルに入ったことを検証し、文字列の平均の長さと文字列あたりの要素の平均数を確認しましょう。
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
そして最後に、各関数が任意のRowNumに対して正しいデータを返すことを確認しましょう。 、したがって、ランダムに1つを選択し、各メソッドで取得した値を比較します。もちろん、結果は異なります。
SELECT f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f WHERE s.RowNum = 37219 ORDER BY f.value;
案の定、すべての関数は期待どおりに機能します(並べ替えは数値ではありません。関数は文字列を出力することを忘れないでください):
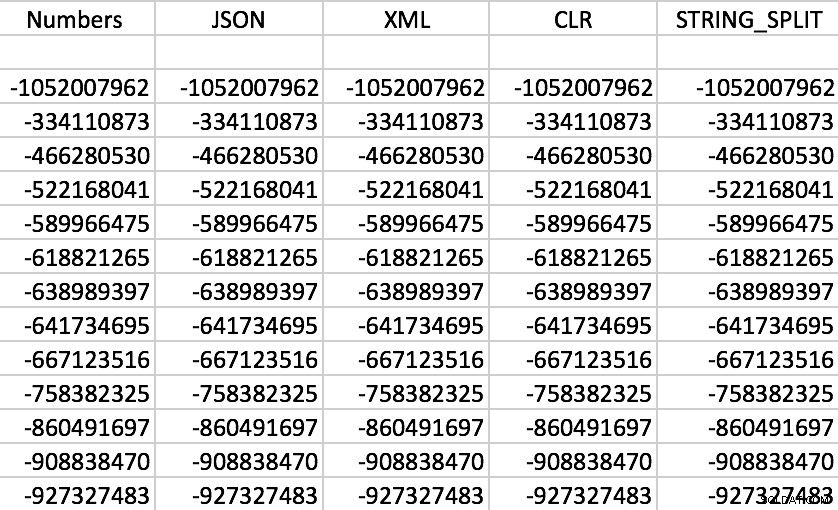 各関数からの出力のサンプルセット
各関数からの出力のサンプルセット
パフォーマンステスト
SELECT SYSDATETIME(); GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f; GO 100 SELECT SYSDATETIME();
上記のコードをメソッドごとに10回実行し、それぞれのタイミングを平均しました。そして、これは私にとって驚きが訪れた場所です。ネイティブのSTRING_SPLITの制限を考えると 機能、私の仮定は、それがすぐに一緒に投げられた、そしてそのパフォーマンスがそれに信憑性を与えるだろうということでした。少年は私が期待したものとは異なる結果でした:
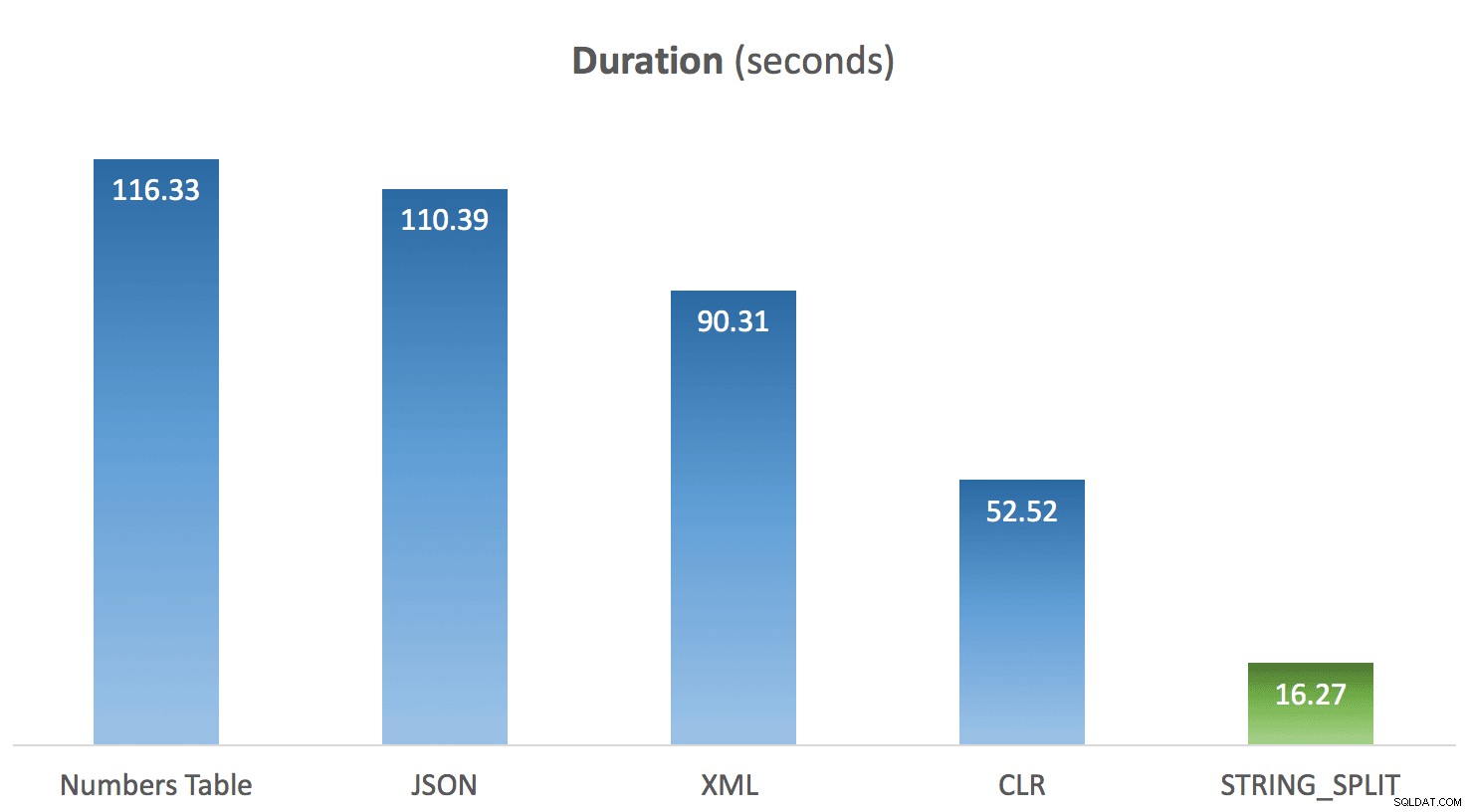 他のメソッドと比較したSTRING_SPLITの平均期間
他のメソッドと比較したSTRING_SPLITの平均期間
更新2016-03-20
Larsからの以下の質問に基づいて、いくつかの変更を加えてテストを再実行しました。
- テスト中にCPUプロファイルをキャプチャするために、SQL SentryPerformanceAdvisorを使用してインスタンスを監視しました。
- 各バッチ間のセッションレベルの待機統計をキャプチャしました。
- パフォーマンスアドバイザダッシュボードでアクティビティが視覚的に区別できるように、バッチ間に遅延を挿入しました。
待機統計情報を取得するための新しいテーブルを作成しました:
CREATE TABLE dbo.Timings ( dt datetime, test varchar(64), point varchar(64), session_id smallint, wait_type nvarchar(60), wait_time_ms bigint, );
次に、各テストのコードが次のように変更されました:
WAITFOR DELAY '00:00:30'; DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f GO 100 DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
テストを実行してから、次のクエリを実行しました:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC; 最初のクエリから、タイミングは以前のテストと一貫性がありました(もう一度グラフを作成しましたが、新しいことは何もわかりません)。
2番目のクエリから、Performance Advisorダッシュボードでこの範囲を強調表示することができ、そこから各バッチを簡単に識別できました。
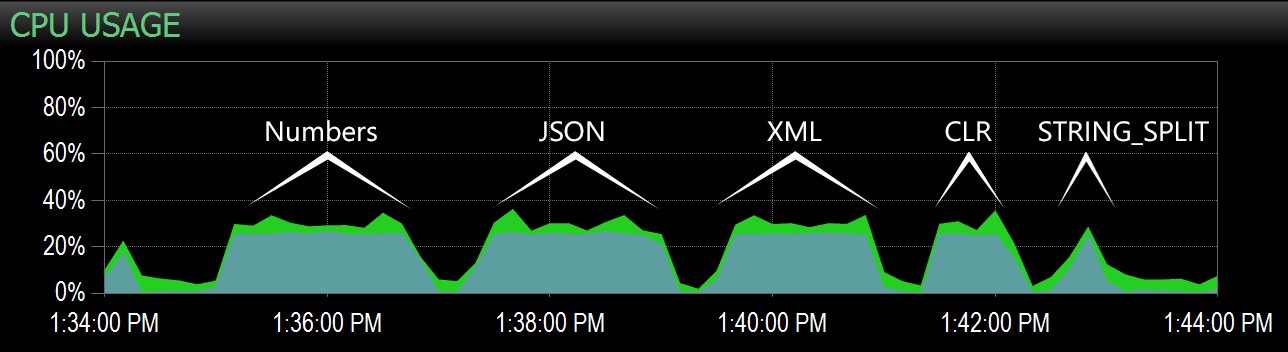 PerformanceAdvisorダッシュボードのCPUチャートにキャプチャされたバッチ
PerformanceAdvisorダッシュボードのCPUチャートにキャプチャされたバッチ
明らかに、STRING_SPLITを*除く*すべてのメソッド テスト期間中、シングルコアをペグしました(これはクアッドコアマシンであり、CPUは着実に25%でした)。ラースはそのSTRING_SPLITの下でほのめかしていた可能性があります CPUを叩くという犠牲を払ってより高速ですが、そうではないようです。
最後に、3番目のクエリから、各バッチの後に発生する次の待機統計を確認できました。
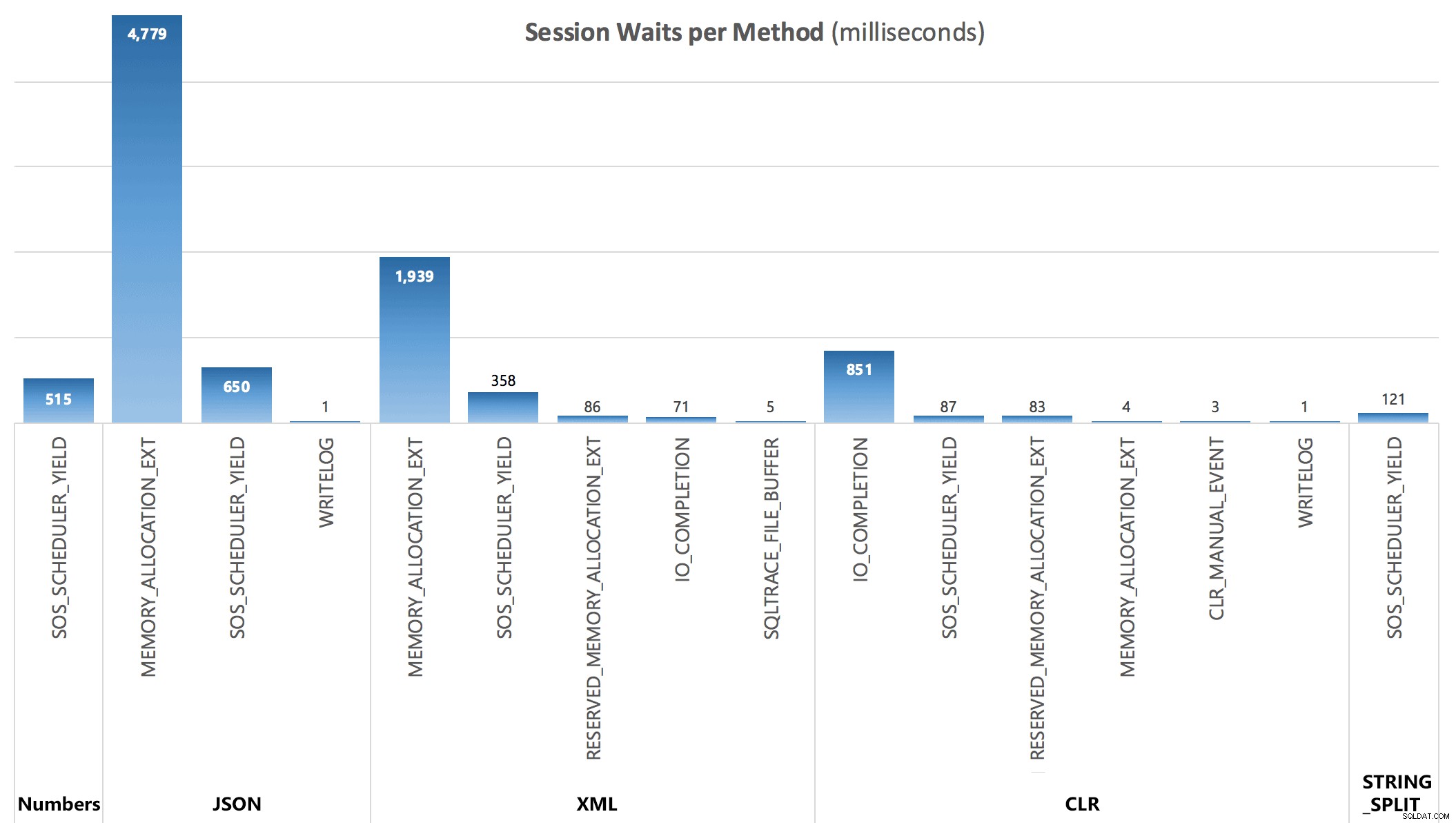 セッションごとの待機(ミリ秒単位)
セッションごとの待機(ミリ秒単位)
DMVによってキャプチャされた待機は、クエリの期間を完全には説明しませんが、追加の場所を示すのに役立ちます。 待機が発生します。
結論
カスタムCLRは、従来のT-SQLアプローチに比べて大きな利点を示していますが、この機能にJSONを使用することは、目新しいものにすぎないようです。STRING_SPLIT 明らかに勝者でした–1マイル。したがって、文字列を分割する必要があり、そのすべての制限に対処できる場合、これは私が予想していたよりもはるかに実行可能なオプションのように見えます。将来のビルドでは、各要素の順序位置を示す出力列、重複した空の文字列を除外する機能、複数文字の区切り文字などの追加機能が表示されることを願っています。
以下の2つのフォローアップ投稿で複数のコメントに対処します:
- SQL Server 2016のSTRING_SPLIT():フォローアップ#1
- SQL Server 2016のSTRING_SPLIT():フォローアップ#2