このSQLの記事では、GROUPBY句とSQLでの使用方法について学習します。また、WHERE句でGROUPBY句を使用する方法についても説明します。
GROUP BY句とは何ですか?
GROUP BY句は、SQL関数を使用してグループ内の列の同じレコードを管理するためにSELECTステートメントで使用されるSQL句です。
GROUP BY句の構文:
SELECT columnname1, columnname2, columnname3 FROM tablename GROUP BY columnname;GROUPBY句のテーブルから複数の列を使用できます。
いくつかの手順があります。SQLクエリでGROUPBY句を使用する方法を学ぶ必要があります。
1。 USEキーワードに続けてデータベース名を使用してデータベースを選択することにより、新しいデータベースを作成するか、既存のデータベースを使用します。
2。 選択したデータベース内に新しいテーブルを作成するか、作成済みのテーブルを使用できます。
3。 テーブルが新しく作成された場合は、INSERTクエリを使用して新しく作成されたデータベースにレコードを挿入し、GROUPBY句を指定せずにSELECTクエリを使用して挿入されたデータを表示します。
4。 これで、SQLクエリでGROUPBY句を使用する準備が整いました。
ステップ1:新しいデータベースを作成するか、作成済みのデータベースを使用します。
私はすでにデータベースを作成しました。既存の作成済みデータベース名Companyを使用します。
USE Company;
会社はデータベース名です。
データベースを作成していない人は、以下のクエリに従ってデータベースを作成します。
CREATE DATABASE database_name;
データベースを作成したら、USEキーワードに続けてデータベース名を使用してデータベースを選択します。
ステップ2:新しいテーブルを作成するか、既存のテーブルを使用します:
すでにテーブルを作成しました。 Employeesという名前の既存のテーブルを使用します。
新しいテーブルを作成するには、以下のCREATETABLE構文に従います。
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
ステップ3:INSERTクエリを使用して新しく作成されたテーブルにレコードを挿入し、SELECTクエリを使用してレコードを表示します。
次の構文を使用して、テーブルに新しいレコードを挿入します。
INSERT INTO table_name VALUES(value1, value2, value3);
次の構文を使用して、テーブルのレコードを表示します。
SELECT * FROM table_name;
次のクエリは、従業員のレコードを表示します:
SELECT * FROM Employees;
上記のSELECTクエリの出力は次のとおりです。
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | C# | 5 |
| 1003 | NIKHIL | VANI | 50500 | ジャイプール | FMW | 2 |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | C# | 5 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 3002 | ANUJA | WANRE | 50500 | ジャイプール | FMW | 2 |
| 3003 | DEEPAM | ジャウハリ | 58500 | ムンバイ | JAVA | 3 |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 |
| 4002 | ASHWINI | バガット | 54500 | NOIDA | JAVA | 3 |
| 4003 | ルチカ | AGARWAL | 60000 | デリー | ORACLE | 1 |
| 5001 | ARCHIT | シャルマ | 55500 | デリー | テスト | 4 |
| 5002 | SANKET | チャウハン | 70000 | ハイデラバード | JAVA | 3 |
| 5003 | ROSHAN | NEHTE | 48500 | チャンディーガル | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | バンガロール | テスト | 4 |
| 6002 | ATISH | JADHAV | 60500 | バンガロール | C# | 5 |
| 6003 | ニキタ | INGALE | 65000 | ハイデラバード | ORACLE | 1 |
ステップ4:クエリでGROUPBY句を使用する準備ができました
次に、例を使用してGROUPBY句について詳しく説明します
例1: 都市ごとにグループ化された従業員レコードを表示するクエリを記述します。
SELECT * FROM EMPLOYEES GROUP BY CITY;
上記のクエリは、同じ都市の従業員が1つのグループと見なされる従業員のレコードを表示します。たとえば、テーブルに10人の従業員レコードがあり、3人がプネ市、3人がムンバイ市、2人がハイデラバードとバンガロールの場合、上記のクエリはプネ市の従業員ムンバイ市の従業員を1つのレコードとしてグループ化します。 。
上記のクエリの出力:
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID |
| 6001 | RAHUL | NIKAM | 54500 | バンガロール | テスト | 4 |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 |
| 4003 | ルチカ | AGARWAL | 60000 | デリー | ORACLE | 1 |
| 5002 | SANKET | チャウハン | 70000 | ハイデラバード | JAVA | 3 |
| 1003 | NIKHIL | VANI | 50500 | ジャイプール | FMW | 2 |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | C# | 5 |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | C# | 5 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
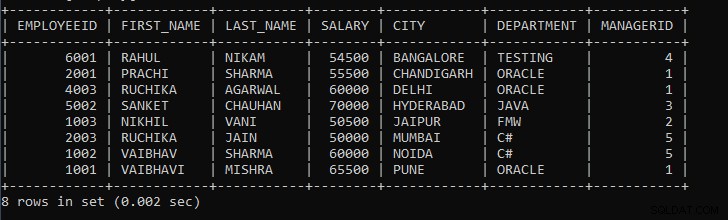
ご覧のとおり、従業員のレコードは都市ごとにグループ化されており、デフォルトではレコードは昇順で表示されます。
例2: 給与ごとに従業員のレコードグループを降順で表示するクエリを記述します。
SELECT * FROM EMPLOYEES GROUP BY SALARY DESC;
上記のクエリは、同じ給与の従業員が1つのグループと見なされる従業員のレコードを表示し、レコードは降順で表示されます。
上記のクエリの出力:
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID |
| 5002 | SANKET | チャウハン | 70000 | ハイデラバード | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 6003 | ニキタ | INGALE | 65000 | ハイデラバード | ORACLE | 1 |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | C# | 5 |
| 3003 | DEEPAM | ジャウハリ | 58500 | ムンバイ | JAVA | 3 |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 |
| 4002 | ASHWINI | バガット | 54500 | NOIDA | JAVA | 3 |
| 1003 | NIKHIL | VANI | 50500 | ジャイプール | FMW | 2 |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | C# | 5 |
| 5003 | ROSHAN | NEHTE | 48500 | チャンディーガル | C# | 5 |
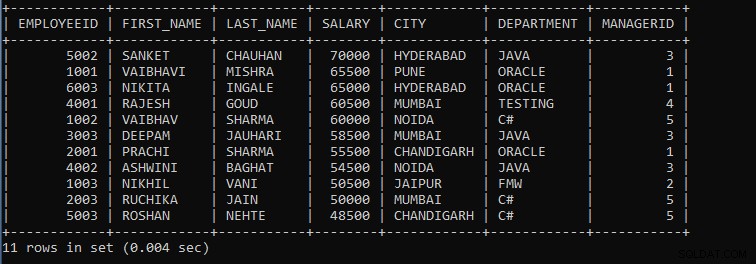
ご覧のとおり、従業員の記録は給与ごとにグループ化されており、最後に説明するように、記録は降順で表示されます。
例3: 給与と都市ごとに従業員のレコードグループを表示するクエリを作成します。
SELECT * FROM EMPLOYEES GROUP BY SALARY, CITY;
上記のクエリは、同じ給与と都市の従業員が1つのグループと見なされる従業員のレコードを表示します。
たとえば、テーブルに10人の従業員レコードがあるとします。 10人の従業員から2人の従業員の給与と都市が他の2人の従業員と一致し、残りの6人の従業員の給与と都市が一致しない場合、6人の従業員は6つの別個のグループと見なされ、他の2人の従業員と一致する2人の従業員は1つのグループと見なされます。 。つまり、8つのグループが形成されます。
上記のクエリの出力:
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID |
| 5003 | ROSHAN | NEHTE | 48500 | チャンディーガル | C# | 5 |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | C# | 5 |
| 1003 | NIKHIL | VANI | 50500 | ジャイプール | FMW | 2 |
| 6001 | RAHUL | NIKAM | 54500 | バンガロール | テスト | 4 |
| 4002 | ASHWINI | バガット | 54500 | NOIDA | JAVA | 3 |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 |
| 5001 | ARCHIT | シャルマ | 55500 | デリー | テスト | 4 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 3003 | DEEPAM | ジャウハリ | 58500 | ムンバイ | JAVA | 3 |
| 4003 | ルチカ | AGARWAL | 60000 | デリー | ORACLE | 1 |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | C# | 5 |
| 6002 | ATISH | JADHAV | 60500 | バンガロール | C# | 5 |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 |
| 6003 | ニキタ | INGALE | 65000 | ハイデラバード | ORACLE | 1 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
| 5002 | SANKET | チャウハン | 70000 | ハイデラバード | JAVA | 3 |
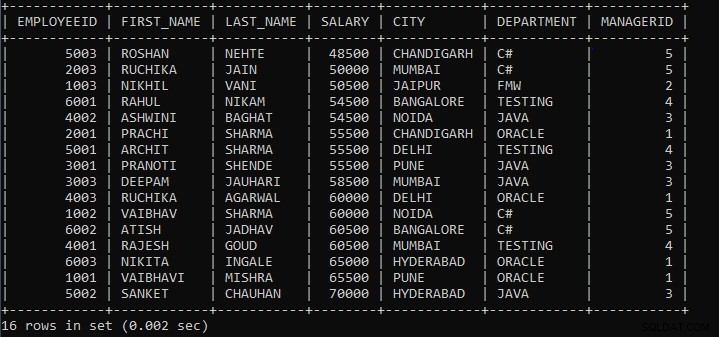
ご覧のとおり、従業員のレコードは給与と都市ごとにグループ化されており、デフォルトでは昇順で表示されます。
例4: 市や部門ごとに従業員の記録を表示するクエリを作成します。
SELECT * FROM EMPLOYEES GROUP BY CITY, DEPARTMENT;
上記のクエリは、従業員が同じ都市にいる従業員の記録を表示し、部門は1つのグループと見なされます。
上記のクエリの出力:
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID |
| 6002 | ATISH | JADHAV | 60500 | バンガロール | C# | 5 |
| 6001 | RAHUL | NIKAM | 54500 | バンガロール | テスト | 4 |
| 5003 | ROSHAN | NEHTE | 48500 | チャンディーガル | C# | 5 |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 |
| 4003 | ルチカ | AGARWAL | 60000 | デリー | ORACLE | 1 |
| 5001 | ARCHIT | シャルマ | 55500 | デリー | テスト | 4 |
| 5002 | SANKET | チャウハン | 70000 | ハイデラバード | JAVA | 3 |
| 6003 | ニキタ | INGALE | 65000 | ハイデラバード | ORACLE | 1 |
| 1003 | NIKHIL | VANI | 50500 | ジャイプール | FMW | 2 |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | C# | 5 |
| 3003 | DEEPAM | ジャウハリ | 58500 | ムンバイ | JAVA | 3 |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | C# | 5 |
| 4002 | ASHWINI | バガット | 54500 | NOIDA | JAVA | 3 |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 |
| 1001 | VAIBHAVI | MISHRA | 65500 | PUNE | ORACLE | 1 |
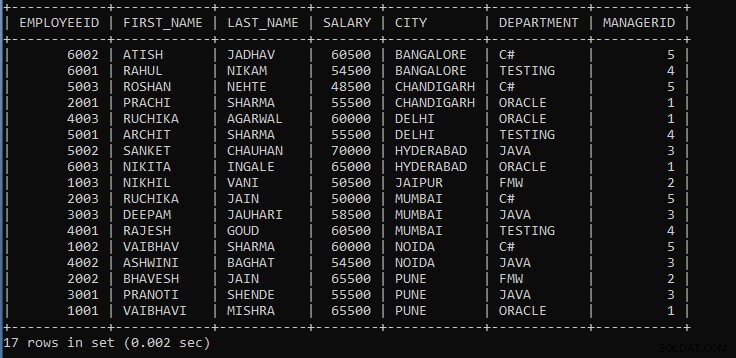
ご覧のとおり、従業員のレコードは市や部門ごとにグループ化されており、デフォルトでは昇順で表示されます。
例5: 従業員のテーブルから各部門の従業員のリストを数えるクエリを作成します。
SELECT DEPARTMENT, COUNT(DEPARTMENT) FROM EMPLOYEES GROUP BY DEPARTMENT;上記のクエリは、部門ごとの各部門グループの従業員数を表示します。 6人の従業員が人事部門で働いているように、5人は別の部門で働いています。
上記のクエリの出力:
| DEPARTMENT | COUNT(DEPARTMENT) |
| C# | 4 |
| FMW | 3 |
| JAVA | 4 |
| ORACLE | 4 |
| テスト | 3 |
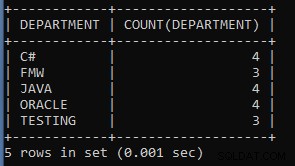
ご覧のとおり、4人の従業員がC#部門で、3人がFMW部門で働いています。
例6: 従業員のテーブルから各都市の従業員のリストを数えるクエリを作成します。
SELECT CITY, COUNT(CITY) FROM EMPLOYEES GROUP BY CITY;
上記のクエリは、都市ごとの各都市グループの従業員数を表示します。 3人の従業員がプネ市で働いているように、4人が別の都市で働いているように。
上記のクエリの出力:
| CITY | COUNT(CITY) |
| バンガロール | 2 |
| チャンディーガル | 2 |
| デリー | 2 |
| ハイデラバード | 2 |
| ジャイプール | 2 |
| ムンバイ | 3 |
| NOIDA | 2 |
| PUNE | 3 |
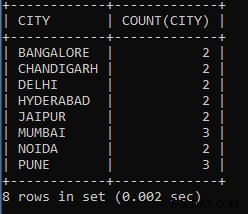
ご覧のとおり、バンガロール市で2人、ムンバイ市で3人の従業員が働いています。
例7: 市ごとに従業員の給与グループを合計するクエリを作成します。
SELECT CITY, SUM(SALARY) AS SALARY FROM EMPLOYEES GROUP BY CITY;上記は、都市名でグループ化された従業員の給与を合計するために使用されます。たとえば、同じ都市の従業員の場合、給与は合計になり、1つのグループと見なされます。給与を追加するために、集計合計関数とそれに続く給与列を使用しました。
上記のクエリの出力:
| CITY | 給与 |
| バンガロール | 115000 |
| チャンディーガル | 104000 |
| デリー | 115500 |
| ハイデラバード | 135000 |
| ジャイプール | 101000 |
| ムンバイ | 169000 |
| NOIDA | 114500 |
| PUNE | 186500 |
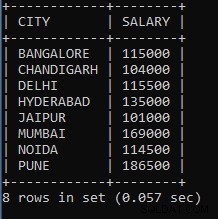
ご覧のとおり、バンガロール市の給与は115000、チャンディーガル市の給与は104000で、従業員の給与が異なりますが、市からは各市で同じアプローチが使用されています。
例8: 各部門からの最低賃金を見つけるためのクエリを作成します。
SELECT DEPARTMENT, MIN(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT;上記のクエリは、各部門からの従業員の最低賃金を見つけるために使用されます。 Java部門の給与の従業員の1人は54500人で、これはJava部門全体の中で最低です。同じ48500は、C#部門の従業員に支払われる最低給与です。
上記のクエリの出力:
| DEPARTMENT | MIN(SALARY) |
| C# | 48500 |
| FMW | 50500 |
| JAVA | 54500 |
| ORACLE | 55500 |
| テスト | 54500 |
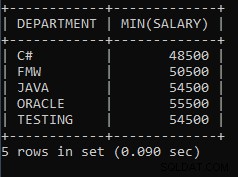
ご覧のとおり、50500はFMW部門の従業員の1人に支払われる最低給与であり、55500はORACLE部門の従業員の1人に支払われる最低給与です。
例9: 各都市の最低賃金を見つけるためのクエリを作成します。
SELECT CITY, MAX(SALARY) FROM EMPLOYEES GROUP BY CITY;上記のクエリは、各都市からの最高給与を見つけるために使用されます。プネ市の給与の従業員の1人は65500で、これはプネ市全体で最も高く、同じ60500がムンバイ市の従業員に支払われる最高の給与です。
上記のクエリの出力:
| CITY | MAX(SALARY) |
| バンガロール | 60500 |
| チャンディーガル | 55500 |
| デリー | 60000 |
| ハイデラバード | 70000 |
| ジャイプール | 50500 |
| ムンバイ | 60500 |
| NOIDA | 60000 |
| PUNE | 65500 |
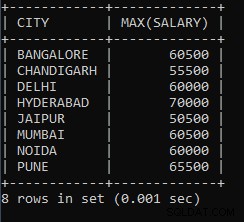
ご覧のとおり、50500はジャイプール市の従業員の1人に支払われる最高の給与であり、55500はチャンディーガル市の従業員の1人に支払われる最高の給与です。