はじめに
- データベースオブジェクトを作成する際に従う必要のある特定のルールがいくつかあります。データベースのパフォーマンスを向上させるには、主キー、クラスター化インデックスと非クラスター化インデックス、および制約をテーブルに割り当てる必要があります。これらすべてのルールに従いますが、テーブル内で重複する行が発生する可能性があります。
- データベースキーを利用することは常に良い習慣です。データベースキーを使用すると、テーブル内のレコードが重複する可能性が低くなります。ただし、重複するレコードがすでにテーブルに存在する場合、これらの重複するレコードを削除するために使用される特定の方法があります。
重複する行を削除する方法
- DELETEJOINの使用 重複する行を削除するステートメント
DELETE JOINステートメントはMySQLで提供されており、テーブルから重複する行を削除するのに役立ちます。
「studentdb」という名前のデータベースについて考えてみます。そのデータベースにテーブルstudentを作成します。
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
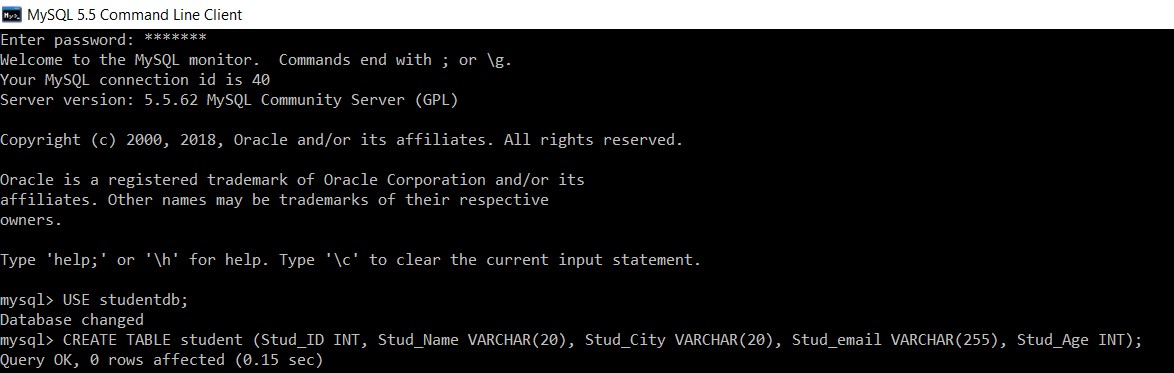
'studentdb'データベースに'student'テーブルが正常に作成されました。
次に、studentテーブルにデータを挿入するための次のクエリを記述します。
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
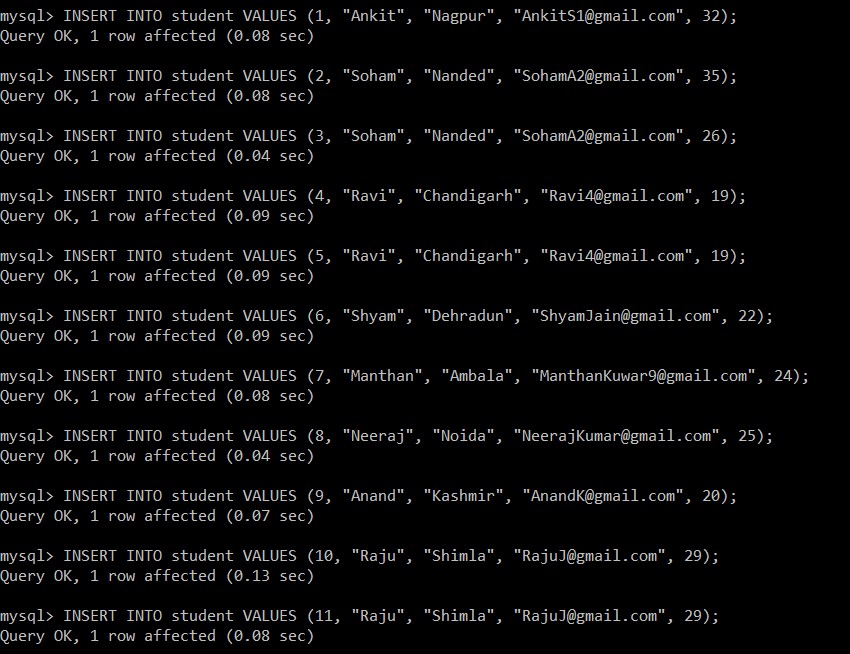
次に、studentテーブルからすべてのレコードを取得します。以下のすべての例について、このテーブルとデータベースを検討します。
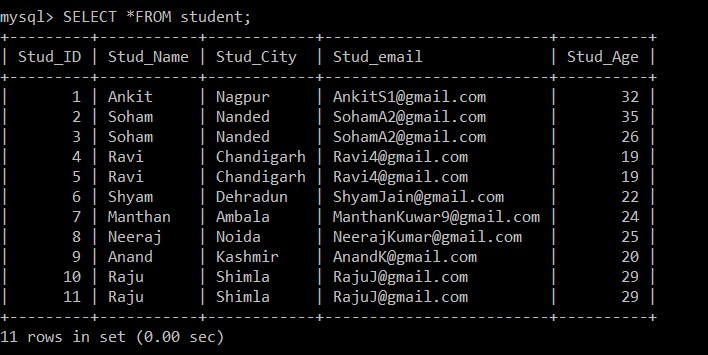
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
例1:
DELETE JOIN を使用して、生徒のテーブルから重複する行を削除するクエリを記述します ステートメント。
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;INNERJOINでDELETEクエリを使用しました。単一のテーブルにINNERJOINを実装するために、2つのインスタンスs1とs2を作成しました。次に、WHERE句を使用して、2つの条件をチェックし、studentテーブルの重複行を見つけました。 2つの異なるレコードの電子メールIDが同じで、学生IDが異なる場合、WHERE句の条件に従って重複レコードとして扱われます。
出力:
Query OK, 3 rows affected (0.20 sec)上記のクエリの結果は、studentテーブルに3つの重複レコードが存在することを示しています。

SELECTクエリを使用して、削除された重複レコードを検索します。
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
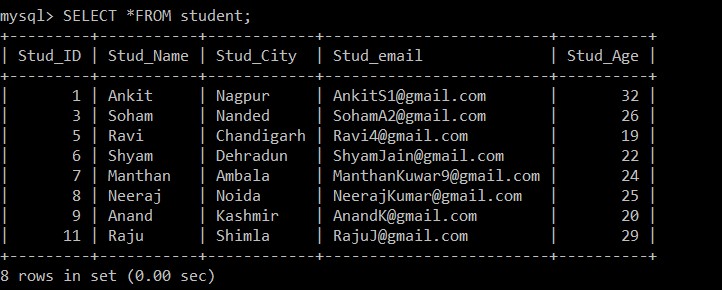
現在選択されているテーブルから3つの重複レコードが削除されるため、studentテーブルに存在するレコードは8つだけになります。次の条件によると:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;2つのレコードの電子メールIDが同じである場合、学生ID間でより小さい記号が使用されるため、従業員IDが大きいレコードのみが保持され、2つのレコード間で他の重複レコードが削除されます。
例2:
より少ない従業員IDで重複レコードを保持し、他のレコードを削除しながら、deletejoinステートメントを使用して学生テーブルから重複行を削除するクエリを記述します。
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;INNERJOINでDELETEクエリを使用しました。単一のテーブルにINNERJOINを実装するために、2つのインスタンスs1とs2を作成しました。次に、WHERE句を使用して、2つの条件をチェックし、studentテーブルの重複行を見つけました。 2つの異なるレコードに存在する電子メールIDが同じで、学生IDが異なる場合、WHERE句の条件に従って重複レコードとして扱われます。
出力:
Query OK, 3 rows affected (0.09 sec)上記のクエリの結果は、studentテーブルに3つの重複レコードが存在することを示しています。

SELECTクエリを使用して、削除された重複レコードを検索します。
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
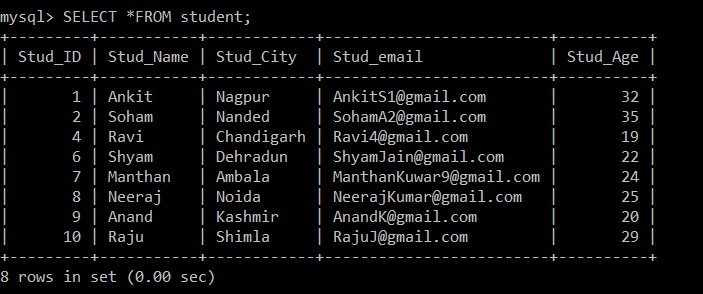
現在選択されているテーブルから3つの重複レコードが削除されるため、studentテーブルに存在するレコードは8つだけになります。次の条件によると:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;学生ID間で大なり記号が使用されているため、2つのレコードの電子メールIDが同じである場合、従業員IDが小さいレコードのみが保持され、2つのレコードのうち他の重複レコードは削除されます。
- 中間テーブルを使用して重複する行を削除する
中間テーブルを使用して重複行を削除するときは、次の手順に従う必要があります。
- 実際のテーブルと同じ新しいテーブルを作成する必要があります。
- 実際のテーブルから新しく作成されたテーブルに個別の行を追加します。
- 実際のテーブルを削除し、新しいテーブルの名前を実際のテーブルと同じ名前に変更します。
例:
中間テーブルを使用して、学生テーブルから重複レコードを削除するクエリを記述します。
ステップ1:
まず、employeeテーブルと同じ中間テーブルを作成します。
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

ここで、「employee」は元のテーブルであり、「temp_student」は中間テーブルです。
ステップ2:
ここで、studentテーブルから一意のレコードのみをフェッチし、フェッチしたすべてのレコードをtemp_studentテーブルに挿入します。
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

ここでは、studentテーブルの個別のレコードをtemp_studentに挿入する前に、重複するすべてのレコードがStud_emailによってフィルタリングされます。次に、一意の電子メールIDを持つレコードのみがtemp_studentに挿入されます。
ステップ3:
次に、studentテーブルを削除し、テーブルtemp_studentの名前をstudentテーブルに変更します。
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
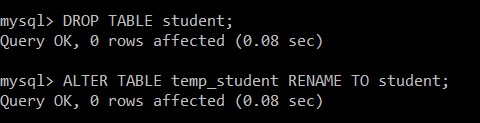
学生テーブルは正常に削除され、temp_studentは一意のレコードのみを含む学生テーブルに名前が変更されます。
次に、studentテーブルに一意のレコードのみが含まれていることを確認する必要があります。これを確認するために、SELECTクエリを使用してstudentテーブルに含まれるデータを確認しました。
mysql> SELECT *FROM student;出力:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
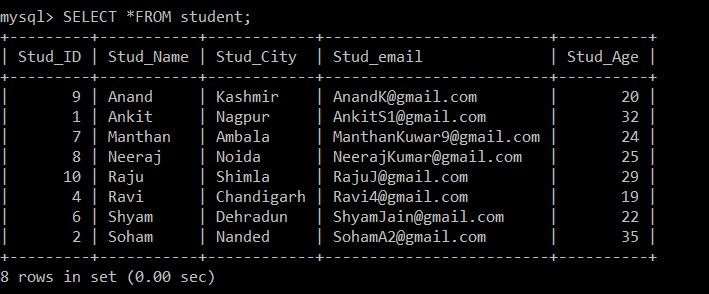
現在選択されているテーブルから3つの重複レコードが削除されるため、studentテーブルに存在するレコードは8つだけになります。手順2では、元のテーブルから個別のレコードをフェッチして中間テーブルに挿入するときに、Stud_emailでGROUP BY句が使用されたため、すべてのレコードが学生の電子メールIDに基づいて挿入されました。ここでは、デフォルトで重複レコードの中に従業員IDが低いレコードのみが保持され、もう1つは削除されます。