バキュームは、テーブルとインデックスで削除されたタプルを再利用するための最も重要な機能の1つです。バキュームがなければ、テーブルとインデックスのサイズは際限なく大きくなり続けます。このブログ投稿では、PostgreSQL13に新しく導入されたVACUUMコマンドのPARALLELオプションについて説明しています。
真空処理フェーズ
新しいオプションについて詳しく説明する前に、掃除機の仕組みの詳細を確認しましょう。
真空(FULLオプションなし)は5つのフェーズで構成されます。たとえば、2つのインデックスを持つテーブルの場合、次のように機能します。
- ヒープスキャンフェーズ
- テーブルを上からスキャンして、ガベージタプルをメモリに収集します。
- インデックス真空フェーズ
- 両方のインデックスを1つずつ掃除機で吸い取ります。
- ヒープバキュームフェーズ
- ヒープ(テーブル)を真空にします。
- インデックスのクリーンアップフェーズ
- 両方のインデックスを1つずつクリーンアップします。
- ヒープ切り捨てフェーズ
- テーブルの最後にある空のページを切り捨てます。
ヒープスキャンフェーズでは、バキュームは可視性マップを使用して、ガベージがないことがわかっているページの処理をスキップできます。一方、インデックスバキュームフェーズとインデックスクリーンアップフェーズの両方で、インデックスアクセス方法に応じて、インデックス全体のスキャンが行われます。が必要です。
たとえば、最も一般的なインデックスタイプであるbtreeインデックスでは、ガベージタプルを削除してインデックスのクリーンアップを行うために、インデックス全体のスキャンが必要です。バキュームは常に単一のプロセスによって実行されるため、インデックスは1つずつ処理されます。特に大きなテーブルでのバキュームの実行時間が長くなると、ユーザーを煩わせることがよくあります。
PARALLELオプション
この問題に対処するために、2016年にバキュームを並列化するパッチを提案しました。長いレビュープロセスと多くの改革の後、PARALLELオプションがPostgreSQL 13に導入されました。このオプションを使用すると、バキュームはインデックスバキュームフェーズとインデックスクリーンアップフェーズを実行できます。並列ワーカー。並列バキュームワーカーは、インデックスバキュームフェーズまたはインデックスクリーンアップフェーズに入る前に起動し、フェーズの終わりに終了します。個々のワーカーがインデックスに割り当てられます。自動真空では、並列真空は常に無効になっています。
整数引数オプションのないPARALLELオプションは、テーブル上のインデックスの数に基づいて並列度を自動的に計算します。
VACUUM (PARALLEL) tbl;
リーダープロセスは常に1つのインデックスを処理するため、並列ワーカーの最大数は(テーブル内のインデックスの数– 1)になり、さらにmax_parallel_maintenance_workersに制限されます。ターゲットインデックスは、min_parallel_index_scan_size以上である必要があります。
PARALLELオプションを使用すると、ゼロ以外の整数値を渡すことで並列度を指定できます。次の例では、3つのワーカーを使用し、合計4つのプロセスを並行して使用しています。
VACUUM (PARALLEL 3) tbl;
PARALLELオプションはデフォルトで有効になっています;並列バキュームを無効にするには、max_parallel_maintenance_workersを0に設定するか、PARALLEL 0を指定します 。
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
VACUUM VERBOSEの出力を見ると、ワーカーがインデックスを処理していることがわかります。
「並列ワーカーによる」として印刷された情報は、ワーカーによって報告されます。
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
インデックスアクセス方法と並列処理の程度
バキュームは、必ずしもインデックスバキュームフェーズとインデックスクリーンアップフェーズを並行して実行するとは限りません。インデックスサイズが小さい場合、またはプロセスを迅速に完了できることがわかっている場合は、並列化のために並列ワーカーを起動および管理するコストにより、代わりにオーバーヘッドが発生します。インデックスアクセス方法とそのサイズによっては、これらのフェーズを並列バキュームワーカープロセスで実行しない方がよいでしょう。
たとえば、十分な大きさのbtreeインデックスをバキュームする場合、インデックスのインデックスバキュームフェーズは常にインデックス全体のスキャンを必要とするため、並列バキュームワーカーによって実行できますが、インデックスのクリーンアップフェーズは、インデックスの場合は並列バキュームワーカーによって実行されます。掃除機は実行されません(たとえば、テーブルにゴミがありません)。これは、インデックスのクリーンアップフェーズでbtreeインデックスに必要なのは、インデックスのバキュームフェーズでも収集されるインデックス統計を収集することであるためです。一方、ハッシュインデックスでは、インデックスのクリーンアップフェーズでインデックスをスキャンする必要はありません。
さまざまなタイプのインデックスバキューム戦略をサポートするために、インデックスアクセスメソッドの開発者は、フラグをamparallelvacuumoptionsに設定することにより、これらの動作を指定できます。 IndexAmRoutineのフィールド 構造。使用可能なフラグは次のとおりです。
- VACUUM_OPTION_NO_PARALLEL(デフォルト)
- 並列バキュームは両方のフェーズで無効になっています。
- VACUUM_OPTION_PARALLEL_BULKDEL
- インデックスバキュームフェーズは並行して実行できます。
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- インデックスバキュームフェーズがまだ実行されていない場合は、インデックスクリーンアップフェーズを並行して実行できます。
- VACUUM_OPTION_PARALLEL_CLEANUP
- インデックスバキュームフェーズですでにインデックスが処理されている場合でも、インデックスクリーンアップフェーズを並行して実行できます。
次の表は、PostgreSQLに組み込まれているインデックスAMが並列バキュームをサポートする方法を示しています。
| nbtree | ハッシュ | gin | 要点 | spgist | brin | ブルーム | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
詳細については、「src / include / command/vacuum.h」を参照してください。
パフォーマンス検証
ノートパソコン(Core i7 2.6GHz、16GB RAM、512GB SSD)での並列掃除機のパフォーマンスを評価しました。テーブルサイズは6GBで、8つの3GBインデックスがあります。合計の関係は30GBであり、マシンのRAMに適合しません。評価ごとに、掃除機をかけた後、テーブルの数パーセントを均一に汚し、次に平行度を変えながら掃除機をかけました。下のグラフは、真空の実行時間を示しています。
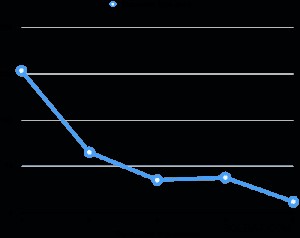
すべての評価において、インデックスバキュームの実行時間は合計実行時間の95%以上を占めました。したがって、インデックス真空フェーズの並列化は、真空実行時間を大幅に短縮するのに役立ちました。
ありがとう
熱心なレビュー、アドバイスの提供、およびPostgreSQL 13へのこの機能のコミットについて、AmitKapilaに特に感謝します。レビュー、テスト、およびディスカッションのためにこの機能に関与したすべての開発者に感謝します。