今日の世界では、データは指数関数的に生成されているため、アナリストは2025年までにグローバルデータの作成が10倍になると予測しています。企業は現在、自社に影響を与えるすべての内部システムと外部ソースにわたってデータを収集しています。また、データを分析して、ビジネス上の意思決定を改善および強化するためにデータをどのように使用できるかについての洞察を得る必要性がますます高まっています。オープンソースのデータ分析および視覚化プラットフォームであるApacheZeppelinは、その目標を達成するために長い道のりを歩むことができます。
この記事では、MongoDBとMySQLのカスタムインタープリターを追加する方法と、それを使用してコレクションデータをクエリおよび視覚化する方法を学習します。まず、ApacheZeppelinとその機能セットの概要から始めましょう。
Apache Zeppelinとは何ですか?

Apache Zeppelinは、インタラクティブなデータ分析と共同ドキュメントを可能にするオープンソースのWebベースの「ノートブック」です。ノートブックは、Apache Spark(大規模データ処理)、Apache Flink(ストリーム処理フレームワーク)などの分散型の汎用データ処理システムと統合されています。 Apache Zeppelinを使用すると、SQL、Scala、R、またはPythonを使用して、ブラウザで美しいデータ駆動型のインタラクティブなドキュメントを作成できます。
ApacheZeppelinの機能
インタラクティブインターフェイスApache Zeppelinには、分析の結果を即座に確認し、作成したものとすぐに接続できるインタラクティブなインターフェイスがあります: |  |
|---|---|
ブラウザノートブックブラウザ(マシンとリモートの両方)で実行するノートブックを作成し、データセットを探索するためにさまざまな種類のグラフを試してみてください。 |  |
統合ApacheプロジェクトのSpark、Flink、Hive、Ignite、Lens、Tajoなどのさまざまなオープンソースのビッグデータツールと統合します。 |  |
動的フォーム
ノートブックで入力フォームを動的に作成します。

コラボレーションと共有
多様で活気のある開発者コミュニティにより、オープンソースのApache2.0ライセンスを通じて絶えず追加および配布されている新しいデータソースにアクセスできます。

通訳Apache Zeppelinインタープリターの概念により、任意の言語/データ処理バックエンドをZeppelinにプラグインできます。現在、Apache Zeppelinは、Apache Spark、Python、JDBC、Markdown、Shellなどの多くのインタープリターをサポートしています。 |  |
|---|
それでは、MongoDBとMySQL用のカスタムインタープリターの作成を始めましょう。
MySQLインタープリターを追加するApache Zeppelinプラットフォームで、右上のドロップダウンメニューに移動し、[インタープリター]をクリックします: |  |
|---|
ここに、すべての通訳者のリストがあります。 MySQL用に新しいものを作成する必要があるため、右上隅にある[作成]ボタンをクリックします。

| 認識可能な名前を入力してくださいインタプリタ(例:mysql)の場合、JDBCとしてグループを選択します: すべてのデフォルトオプションを保持しますが、必要な詳細を入力し、MySQLサーバーへの接続が確立されていることを確認します: |  |
|---|

また、カスタムアーティファクトをMySQLコネクタJARに追加して、Zeppelinがどこから実行するかを認識できるようにする必要があります。ここからコネクタをダウンロードし、interpreter / jdbcフォルダに配置して、アーティファクトへの正確なパスを指定します。

以上です!インタープリターをテストするには、新しいメモを作成する必要があります。ただし、最初に、MongoDBインタープリターもセットアップしましょう。
MongoDBインタープリターを追加する
通訳ページに戻り、「作成」ボタンをクリックします。このオープンソースのMongoDBインタープリターを使用するので、次に.zipファイルをダウンロードして.jarに名前を変更する必要があります。
その後、interpreters /に移動し、mongodb /フォルダーを作成して、.jarをフォルダーに貼り付けます。

| これでmongodbと呼ばれる新しいインタプリタグループ。インタープリターページに移動し、mongodbのようなわかりやすい名前を入力してから、[インタープリター]グループのドロップダウンでmongodbを選択します。 次に、新しく作成したScaleGridMongoDBクラスターの詳細を[概要/マシン]セクションの[クラスターの詳細]ページにある[プロパティ]に入力します。 |  |
|---|

これで完了です。次に、新しく作成したインタープリターをテストします。
ツェッペリンノートを作成する
| クエリを実行するにはデータの視覚化に役立ちます。メモを作成する必要があります。 Zeppelinヘッダーペインで、[ノートブック]、[新しいノートの作成]の順にクリックします。 |  |
|---|---|
| ノートブックヘッダーに接続ステータスが次のように表示されていることを確認します右上隅にある緑色の点で示されます: |  |
メモを作成すると、詳細情報を入力するためのダイアログが表示されます。新しく作成したmysqlとしてデフォルトのインタープリターを選択し、「メモの作成」をクリックします。

メモでクエリを実行
| 実行する前にクエリがある場合は、メモに使用するインタプリタのタイプについても言及する必要があります。これを行うには、メモを「%mysql」で開始します。これにより、ZeppelinはそのメモでMySQLクエリを期待するようになります。 |  |
|---|
これで、データベースにクエリを実行する準備が整いました。この例では、一般的なwp_optionsテーブルを含むWordPressインストールを使用して、データのクエリと視覚化を行います。

できます!さまざまなグラフをクリックして、さまざまなグラフ形式でデータを視覚化できるようになりました。

同様に、MongoDBの場合は、MongoDBクラスターにデータがあることを確認してください。 [管理]タブに移動してMongoクエリを実行することで、いくつかを追加できます。
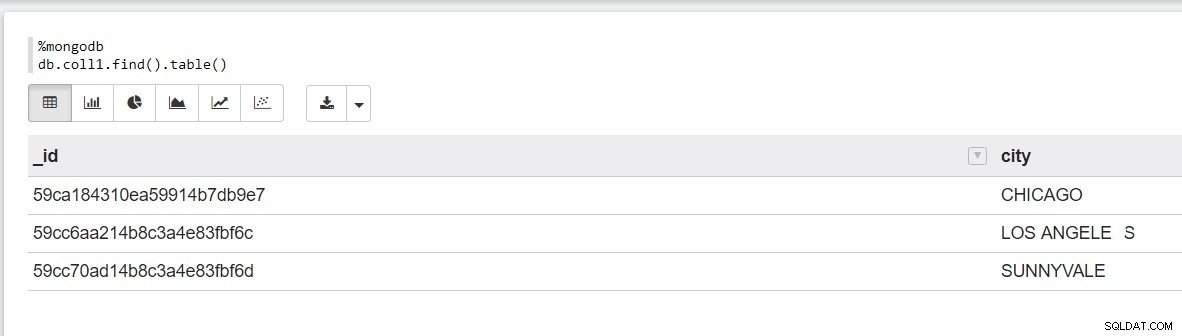
注にあるMongoDBデータの例を次に示します。
メモへのリンクを共有するこれでデータの視覚化とクエリの準備ができたので、チームに見せたいと思うかもしれません。メモへの共有可能なリンクを作成することで、これを非常に簡単に行うことができます: この共有可能なリンクは誰でも表示できます。また、特定のグラフへのリンクのみを共有することもできます: |  |
|---|

ApacheZeppelinの結論
Apache Zeppelinは非常に便利なツールであり、チームはさまざまな視覚化オプション、テーブル、コラボレーション用の共有可能なリンクを使用してデータを管理および分析できます。始めるのに役立つリンクは次のとおりです。
ApacheZeppelinをダウンロード
MongoDBインタープリター
MySQLコネクタ
また、上位4つ(MongoDB Compass、Robomongo、Studio 3T、MongoBooster)など、MongoDBGUIを使用してデータを視覚化する他の方法を検討することもできます。
いつものように、何か素晴らしいものを作ったら、それについてツイートしてください@scalegridio
Redis™*のホスティングと管理についてサポートが必要な場合は、support@scalegrid.ioまでお問い合わせください。
