SQL Server 2005では、非クラスター化インデックスに非キー列を含める機能が追加されました。 SQL Server 2000以前では、非クラスター化インデックスの場合、インデックスに定義されたすべての列はキー列でした。つまり、ルートからリーフレベルまで、インデックスのすべてのレベルの一部でした。列が包含列として定義されている場合、それはリーフレベルの一部のみです。 Books Onlineは、含まれている列の次の利点に注目しています。
- インデックスキー列として許可されていないデータ型にすることができます。
- これらは、インデックスキー列の数またはインデックスキーサイズを計算するときにデータベースエンジンによって考慮されません。
たとえば、varchar(max)列をインデックスキーの一部にすることはできませんが、インクルード列にすることはできます。さらに、そのvarchar(max)列は、インデックスキーに課せられた900バイト(または16列)の制限にはカウントされません。
ドキュメントには、次のパフォーマンス上の利点も記載されています。
非キー列を持つインデックスは、クエリ内のすべての列がキー列または非キー列としてインデックスに含まれている場合、クエリのパフォーマンスを大幅に向上させることができます。クエリオプティマイザがインデックス内のすべての列値を見つけることができるため、パフォーマンスが向上します。テーブルまたはクラスター化されたインデックスデータにアクセスしないため、ディスクI/O操作が少なくなります。インデックス列がキー列であるか非キー列であるかにかかわらず、すべての列がインデックスの一部ではない場合と比較して、パフォーマンスが向上すると推測できます。しかし、2つのバリエーションの間にパフォーマンスの違いはありますか?
セットアップ
AdventuresWork2012データベースのコピーをインストールし、Kimberly Trippのバージョンのsp_helpindexを使用してSales.SalesOrderHeaderテーブルのインデックスを確認しました:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Sales.SalesOrderHeaderのデフォルトインデックス
まず、複数の列からデータを取得するテスト用の簡単なクエリから始めます。
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
SQL Sentry Plan Explorerを使用してAdventureWorks2012データベースに対してこれを実行し、プランとテーブルI / O出力を確認すると、689個の論理読み取りを含むクラスター化インデックススキャンが得られることがわかります。
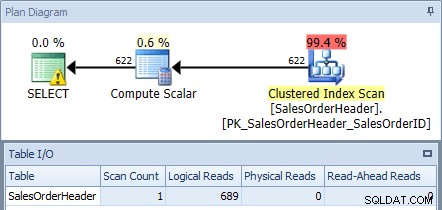
(Management Studioでは、SET STATISTICS IO ON;を使用してI/Oメトリックを確認できます。 。)
オプティマイザがこのクエリのインデックスを推奨するため、SELECTには警告アイコンがあります:
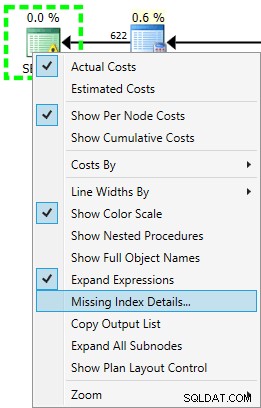
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
テスト1
最初に、オプティマイザーが推奨するインデックス(NCI1_includedという名前)と、すべての列をキー列として持つバリエーション(NCI1という名前)を作成します。
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
元のクエリを再実行し、一度NCI1でヒントを与え、一度NCI1_includedでヒントを与えると、元のクエリと同様のプランが表示されますが、今回は、クラスター化されていない各インデックスのインデックスシークがあり、表I/と同等の値があります。 O、および同様のコスト(両方とも約0.006):
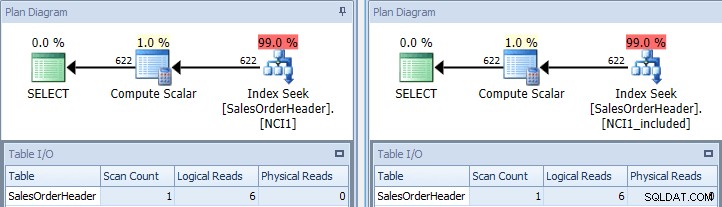
インデックスシークを使用した元のクエリ–左側にキー、オンに含める右
(インデックスシークは実際には変装した範囲スキャンであるため、スキャンカウントは1のままです。)
現在、AdventureWorks2012データベースは、サイズの点で本番データベースを代表していません。各インデックスのページ数を見ると、まったく同じであることがわかります。
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
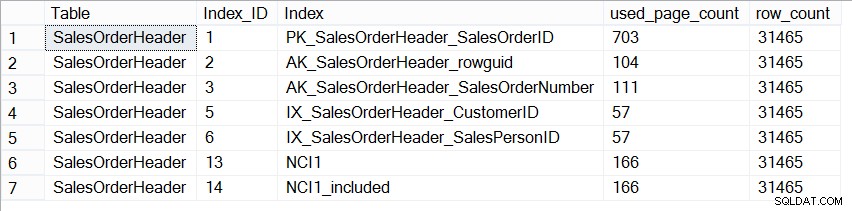
Sales.SalesOrderHeaderのインデックスのサイズ
パフォーマンスを検討している場合は、より大きなデータセットでテストするのが理想的です(そしてもっと楽しくなります)。
テスト2
2億行を超えるSalesOrderHeaderテーブル(ここにスクリプト)があるAdventureWorks2012データベースのコピーがあるので、そのデータベースに同じ非クラスター化インデックスを作成して、クエリを再実行しましょう。
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
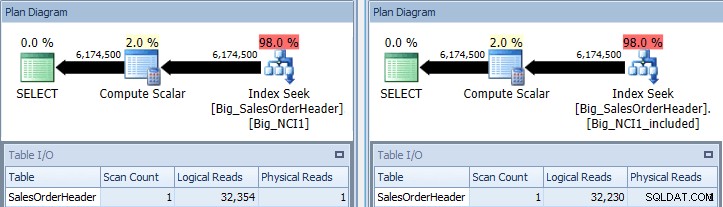
インデックスを使用した元のクエリは、Big_NCI1(l)およびBig_NCI1_Included( r)
ここで、いくつかのデータを取得します。クエリは600万行を超え、各インデックスを検索するには32,000を超える読み取りが必要であり、推定コストは両方のクエリで同じです(31.233)。パフォーマンスの違いはまだありません。インデックスのサイズを確認すると、列が含まれているインデックスのページ数が5,578少ないことがわかります。
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Sales.Big_SalesOrderHeaderのインデックスのサイズ
これをさらに深く掘り下げてdm_dm_index_physical_statsを確認すると、インデックスの中間レベルに違いがあることがわかります。
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
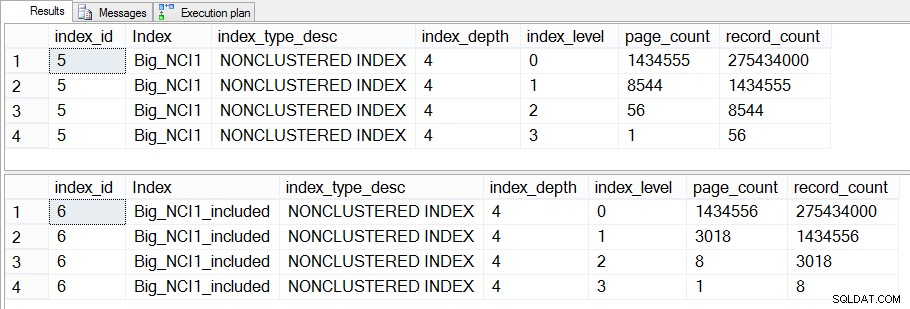
Sales.Big_SalesOrderHeaderのインデックスのサイズ(レベル固有)
2つのインデックスの中間レベルの違いは43MBであり、これは重要ではないかもしれませんが、ディスクとメモリの両方でスペースを節約するために、列を含めてインデックスを作成する傾向があります。クエリの観点からは、キーにすべての列があるインデックスと、含まれている列があるインデックスの間で、パフォーマンスに大きな変化は見られません。
テスト3
このテストでは、クエリを変更して、[SubTotal] >= 100のフィルターを追加しましょう。 WHERE句へ:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
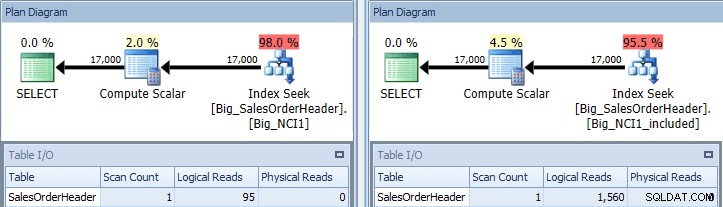
これで、I / O(95回の読み取りと1,560)、コスト(0.848と1.55)の違い、およびクエリプランの微妙ではあるが注目に値する違いがわかります。キー内のすべての列でインデックスを使用する場合、シーク述語はCustomerIDとSubTotalです:
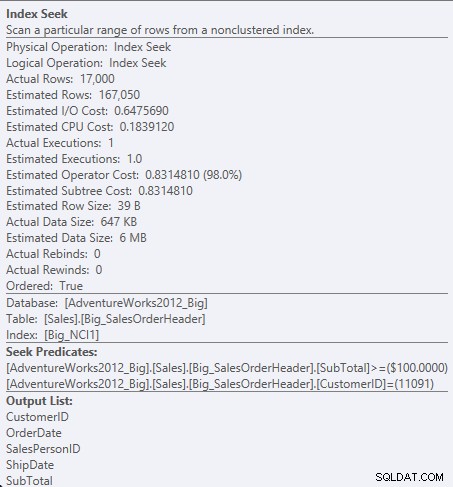
NCI1に対する述語を探す
SubTotalはインデックスキーの2番目の列であるため、データは順序付けられ、SubTotalはインデックスの中間レベルに存在します。エンジンは、CustomerIDが11091でSubTotalが100以上の最初のレコードを直接シークし、CustomerID11091のレコードがなくなるまでインデックスを読み取ることができます。
列が含まれているインデックスの場合、SubTotalはインデックスのリーフレベルにのみ存在するため、CustomerIDはシーク述語であり、SubTotalは残りの述語です(スクリーンショットでは述語としてリストされています):
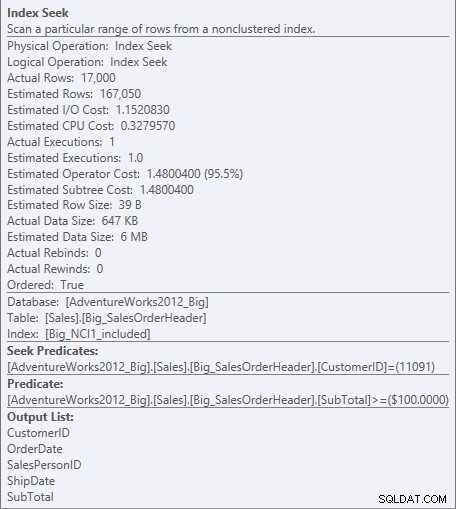
NCI1_includedに対する述語と残余述語を探す
エンジンは、CustomerIDが11091である最初のレコードを直接シークできますが、すべてを確認する必要があります。 CustomerID 11091のレコードを作成して、データがCustomerIDとSalesOrderID(クラスタリングキー)で並べ替えられているため、SubTotalが100以上かどうかを確認します。
テスト4
クエリのバリエーションをもう1つ試して、今回はORDER BYを追加します:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
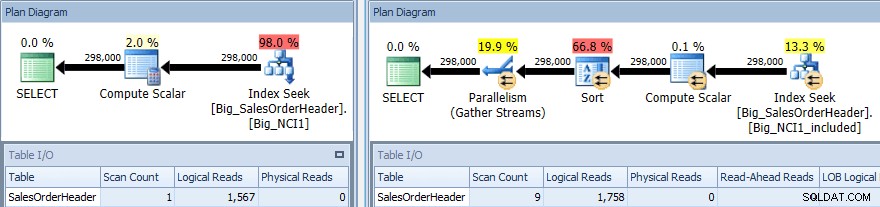
両方のインデックスに対するSORTを使用したクエリの実行プラン
ここでも、I / Oの変更(ごくわずかですが)、コストの変更(1.5対9.3)、および計画の形状の大幅な変更があります。また、スキャンの数も多くなっています(1対9)。クエリでは、データをSubTotalで並べ替える必要があります。 SubTotalがインデックスキーの一部である場合は並べ替えられるため、CustomerID 11091のレコードが取得されると、それらはすでに要求された順序になっています。
SubTotalが含まれる列として存在する場合、CustomerID 11091のレコードは、ユーザーに返す前に並べ替える必要があるため、オプティマイザーはクエリに並べ替え演算子を挿入します。その結果、インデックスBig_NCI1_includedを使用するクエリは、29,312 KBのメモリ許可も要求します(そして与えられます)。これは注目に値します(そしてプランのプロパティにあります)。
概要
私たちが答えたかった最初の質問は、クエリがキーにすべての列を持つインデックスを使用した場合と、リーフレベルに含まれるほとんどの列を持つインデックスを使用した場合にパフォーマンスの違いが見られるかどうかでした。最初の一連のテストでは違いはありませんでしたが、3番目と4番目のテストでは違いがありました。最終的にはクエリに依存します。 2つのバリエーションのみを調べました。1つには追加の述語があり、もう1つにはORDER BYがあり、さらに多くのバリエーションが存在します。
開発者とDBAが理解する必要があるのは、インデックスに列を含めることにはいくつかの大きな利点があるということですが、キーにすべての列があるインデックスと常に同じように機能するとは限りません。述語と結合の一部ではない列をキーから移動し、それらを含めるだけで、インデックスの全体的なサイズを縮小したくなる場合があります。ただし、場合によっては、クエリの実行により多くのリソースが必要になり、パフォーマンスが低下する可能性があります。劣化は重要ではない可能性があります。そうではないかもしれません…あなたがテストするまであなたは知りません。したがって、インデックスを設計するときは、先頭の列の後の列について考え、それらがキーの一部である必要があるかどうか(たとえば、データを順序付けておくとメリットが得られるため)、または含まれている目的を果たすことができるかどうかを理解することが重要です。列。
SQL Serverのインデックス作成で一般的であるように、最適な戦略を決定するには、インデックスを使用してクエリをテストする必要があります。それは芸術であり科学であり続けます–できるだけ多くのクエリを満たすためにインデックスの最小数を見つけようとします。