データベースの保守はあなたの仕事ではないと思うかもしれません。しかし、モデルを積極的に設計すれば、モデルを維持しなければならない人々の生活を楽にするデータベースを手に入れることができます。
優れたデータベース設計には、プロアクティブであり、あらゆる作業環境で高く評価されている品質が必要です。この用語に慣れていない場合、プロアクティブとは、問題を予測し、問題が発生したときに解決策を用意する能力です。さらに良いのは、最初から問題が発生しないように計画して行動することです。
雇用主は、従業員や請負業者の積極性がコスト削減に等しいことを理解しています。それが彼らがそれを大切にし、人々にそれを実践するように勧める理由です。
データモデラーとしてのあなたの役割において、プロアクティブを実証する最良の方法は、データベースのメンテナンスを日常的に悩ませている問題を予測して回避するモデルを設計することです。または、少なくとも、これらの問題の解決策を大幅に簡素化します。
データベースの保守を担当していない場合でも、データベースの保守を容易にするためのモデリングには多くの利点があります。たとえば、データの緊急事態を解決するためにいつでも呼び出されることを防ぎます。これにより、非常に楽しんでいる設計やモデリングのタスクに費やす可能性のある貴重な時間を奪うことができます。
IT担当者の生活を楽にする
データベースを設計するときは、DERの提供と更新スクリプトの生成を超えて考える必要があります。データベースが本番環境に移行すると、メンテナンスエンジニアはあらゆる種類の潜在的な問題に対処する必要があります。データベースモデラーとしての私たちのタスクの一部は、これらの問題が発生する可能性を最小限に抑えることです。
まず、優れたデータベース設計を作成することの意味と、そのアクティビティが通常のデータベース保守タスクにどのように関連しているかを見てみましょう。
データモデリングとは
データモデリングは、情報リポジトリの抽象的な、通常はグラフィカルな表現を作成するタスクです。データモデリングの目標は、データがリポジトリに保存されているエンティティの属性とエンティティ間の関係を公開することです。
データモデルは、ビジネス上の問題のニーズに基づいて構築されています。ルールと要件は、ビジネスエキスパートからの入力を通じて事前に定義されているため、新しいデータリポジトリの設計に組み込んだり、既存のデータリポジトリの反復に適合させたりすることができます。
理想的には、データモデルは、変化するビジネスニーズに伴って進化する生きたドキュメントです。これらは、ビジネス上の意思決定をサポートし、システムのアーキテクチャと戦略を計画する上で重要な役割を果たします。データモデルは、それらが表すデータベースと同期して、それらのデータベースのメンテナンスルーチンに役立つようにする必要があります。
一般的なデータベースメンテナンスの課題
データベースを維持するには、その長所を失わないようにするために、自動化されているかどうかにかかわらず、継続的な監視が必要です。データベースメンテナンスのベストプラクティスにより、データベースは常に次のことを維持できます。
- 情報の完全性と品質
- パフォーマンス
- 可用性
- スケーラビリティ
- 変更への適応性
- トレーサビリティ
- セキュリティ
毎回優れたデータベース設計を作成するのに役立つ多くのデータモデリングのヒントを利用できます。以下で説明するものは、特に上記のデータベース品質の維持を保証または促進することを目的としています。
完全性と情報の質
データベース保守のベストプラクティスの基本的な目標は、データベース内の情報がその整合性を維持することを保証することです。これは、ユーザーが情報を信頼し続けるために重要です。
整合性には2つのタイプがあります:物理的整合性 および論理的完全性 。
身体的完全性
データベースの物理的な整合性を維持するには、ハードウェアや電源の障害などの外部要因から情報を保護します。最も一般的で広く受け入れられているアプローチは、災害によってデータベースが破壊された場合に、妥当な時間内にデータベースを回復できる適切なバックアップ戦略によるものです。
データベースストレージを管理するDBAおよびサーバー管理者にとって、データベースを更新頻度の異なるセクションに分割できるかどうかを知っておくと便利です。これにより、ストレージの使用状況とバックアップ計画を最適化できます。
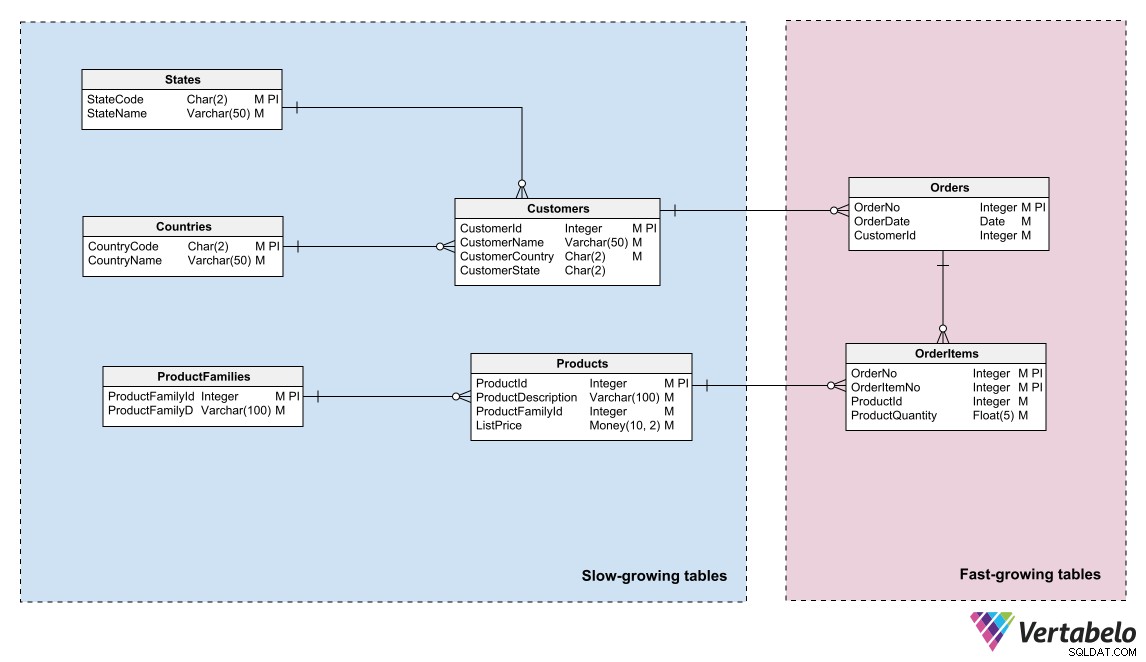
データモデルは、さまざまなデータの「温度」の領域を識別し、エンティティをそれらの領域にグループ化することによって、その分割を反映できます。 「温度」とは、テーブルが新しい情報を受け取る頻度を指します。非常に頻繁に更新されるテーブルは「最もホット」です。更新されない、またはほとんど更新されないものが「最も寒い」です。

ホットデータ、ウォームデータ、コールドデータを区別するeコマースシステムのデータモデル。
DBAまたはシステム管理者は、この論理グループを使用してデータベースファイルをパーティション化し、パーティションごとに異なるバックアッププランを作成できます。
論理的整合性
データベースの論理的整合性を維持することは、データベースが提供する情報の信頼性と有用性にとって不可欠です。データベースに論理的な整合性がない場合、データベースを使用するアプリケーションは遅かれ早かれデータの不整合を明らかにします。これらの不整合に直面すると、ユーザーは情報を信用せず、より信頼性の高いデータソースを探すだけです。
データベース保守タスクの中で、情報の論理的整合性を維持することは、データベースモデリングタスクの拡張であり、データベースが本番環境に移行した後に開始され、その存続期間を通じて継続されます。このメンテナンス領域の最も重要な部分は、変更への適応です。
変更管理
ビジネスルールまたは要件の変更は、データベースの論理的な整合性に対する絶え間ない脅威です。構築したデータモデルは、ビジネスに完全に適合しており、クエリに対して適切な情報で応答し、挿入、更新、または削除の異常がないことを知っているので、満足できるかもしれません。短命なので、この満足の瞬間をお楽しみください!
データベースの保守には、モデルを毎日変更する必要性に直面することが含まれます。これにより、新しいオブジェクトを追加したり、既存のオブジェクトを変更したり、関係のカーディナリティを変更したり、主キーを再定義したり、データ型を変更したり、モデラーを震えさせるその他のことを行う必要があります。
変化は常に起こります。いくつかの要件が最初から間違って説明されていた、新しい要件が表面化した、またはモデルに意図せずに何らかの欠陥が導入された可能性があります(結局のところ、データモデラーは人間だけです)。
変更が必要になったときに、モデルを簡単に変更できる必要があります。モデルをバージョン管理し、データベースをあるバージョンから別のバージョンに移行するためのスクリプトを生成し、すべての設計上の決定を適切に文書化できるモデリング用のデータベース設計ツールを使用することが重要です。
これらのツールがないと、設計に加えるすべての変更により、最も不適切な時期に明らかになる整合性のリスクが生じます。 Vertabeloは、このすべての機能を提供し、モデルのバージョン履歴を、モデルについて考えることなく維持します。
Vertabeloに組み込まれている自動バージョン管理は、データモデルへの変更を維持する上で非常に役立ちます。
変更管理とバージョン管理も、データモデリングアクティビティをソフトウェア開発ライフサイクルに組み込む上で重要な要素です。
リファクタリング
使用中のデータベースに変更を適用するときは、情報が失われないこと、および変更の結果としてその整合性が影響を受けないことを100%確認する必要があります。これを行うには、リファクタリング手法を使用できます。これらは通常、セマンティクスに影響を与えずに設計を改善したい場合に適用されますが、設計エラーを修正したり、モデルを新しい要件に適合させたりするためにも使用できます。
リファクタリングの手法は多数あります。それらは通常、レガシーデータベースに新しい命を吹き込むために使用され、変更が既存の情報に害を及ぼさないことを保証する教科書の手順があります。本全体がそれについて書かれています。読むことをお勧めします。
要約すると、リファクタリング手法を次のカテゴリにグループ化できます。
- データ品質: データの一貫性と一貫性を確保するための変更を行います。例としては、ルックアップテーブルの追加、別のテーブルで繰り返されるデータの移行、列への制約の追加などがあります。
- 構造: モデルのセマンティクスを変更しないテーブル構造に変更を加える。例としては、2つの列を1つに結合する、代替キーを追加する、列を2つに分割するなどがあります。
- 参照整合性: 変更を適用して、参照されている行が関連するテーブル内に存在すること、または参照されていない行を削除できることを確認します。たとえば、列に外部キー制約を追加したり、テーブルにnull以外の値の制約を追加したりします。
- アーキテクチャ: アプリケーションとデータベースの相互作用を改善することを目的とした変更を行います。例としては、インデックスの作成、テーブルの読み取り専用の作成、ビュー内の1つ以上のテーブルのカプセル化などがあります。
モデルのセマンティクスを変更する手法、およびデータモデルを変更しない手法は、リファクタリング手法とは見なされません。これには、テーブルへの行の挿入、新しい列の追加、新しいテーブルまたはビューの作成、およびテーブル内のデータの更新が含まれます。
情報品質の維持
データベースの情報品質は、データが正確性、有効性、完全性、および一貫性に対する組織の期待をどの程度満たしているかを示します。データベースのライフサイクル全体を通じてデータ品質を維持することは、データベース内のデータを使用して正確で情報に基づいた意思決定を行うために、ユーザーにとって不可欠です。
データモデラーとしてのあなたの責任は、モデルが情報品質を可能な限り最高レベルに保つことを保証することです。これを行うには:
- 挿入、更新、または削除の異常が発生しないように、設計は少なくとも3番目の正規形に従う必要があります。この考慮事項は、主に、データが定期的に追加、更新、および削除されるトランザクション用のデータベースに適用されます。データの更新と削除が行われることはめったにないため、分析用のデータベース(データウェアハウスなど)には厳密には適用されません。
- 各テーブルの各フィールドのデータ型は、論理モデルで表す属性に適している必要があります。これは、フィールドが数値、日付、または英数字のデータ型であるかどうかを適切に定義するだけではありません。各フィールドでサポートされる値の範囲と精度を正しく定義することも重要です。例:データベースに日付/時刻フィールドとして実装されたDate型の属性は、ゼロ以外の時間部分で格納された値が日付範囲を使用するクエリの範囲外になる可能性があるため、クエリで問題を引き起こす可能性があります。
- データウェアハウスの構造を定義する次元と事実は、ビジネスのニーズと一致している必要があります。データウェアハウスを設計するときは、モデルのディメンションとファクトを最初から正しく定義する必要があります。データベースが運用可能になったら変更を加えると、非常に高いメンテナンスコストがかかります。
成長の管理
データベースを維持する上でのもう1つの大きな課題は、データベースの拡張が予期せずストレージ容量の制限に達するのを防ぐことです。ストレージスペースの管理を支援するために、バックアップ手順で使用されるのと同じ原則を適用できます。つまり、モデル内のテーブルを、それらが成長する速度に従ってグループ化します。
通常、2つの領域に分割するだけで十分です。行が頻繁に追加されるテーブルを1つの領域に配置します。この領域には、行が別の領域に挿入されることはめったにありません。モデルをこのようにセクター化すると、ストレージ管理者は各領域の成長率に応じてデータベースファイルを分割できます。容量や成長の可能性が異なるさまざまなストレージメディアにパーティションを分散できます。
テーブルを成長率でグループ化すると、ストレージ要件を決定し、その成長を管理するのに役立ちます。
ロギング
クエリ時の情報をそのまま提供することを期待してデータモデルを作成します。ただし、ユーザーが特に必要としない限り、データベースが過去に発生したすべてのことを記憶する必要性を見落としがちです。
データベースを維持することの一部は、特定のデータがどのように、いつ、なぜ、誰によって変更されたかを知ることです。これは、製品の価格がいつ変更されたかを調べたり、病院の患者の医療記録の変更を確認したりするためのものである可能性があります。ロギングは、複雑なバックアップ復元手順に頼る必要なしに、情報の状態を過去のある時点にロールバックできるため、ユーザーまたはアプリケーションのエラーを修正するためにも使用できます。
繰り返しになりますが、ユーザーが明示的にそれを必要としない場合でも、プロアクティブなロギングの必要性を考慮することは、データベースの保守を容易にし、問題を予測する能力を実証するための非常に価値のある手段です。ログデータがあると、誰かが履歴情報を確認する必要があるときに即座に対応できます。
ロギングをサポートするデータベースモデルにはさまざまな戦略があり、そのすべてがモデルを複雑にします。 1つのアプローチはインプレースロギングと呼ばれ、バージョン情報を記録するために各テーブルに列を追加します。これは、個別のスキーマやロギング固有のテーブルの作成を伴わない単純なオプションです。ただし、テーブルの元の主キーは主キーとして有効ではなくなるため、モデルの設計に影響を与えます。それらの値は、同じデータの異なるバージョンを表す行で繰り返されます。
ログ情報を保持する別のオプションは、シャドウテーブルを使用することです。シャドウテーブルは、ログトレイルデータを記録するための列が追加されたモデルテーブルのレプリカです。この戦略では、元のモデルのテーブルを変更する必要はありませんが、データモデルを変更するときは、対応するシャドウテーブルを更新することを忘れないでください。
さらに別の戦略は、他のテーブルへのすべての挿入、削除、または変更を記録する汎用テーブルのサブスキーマを採用することです。
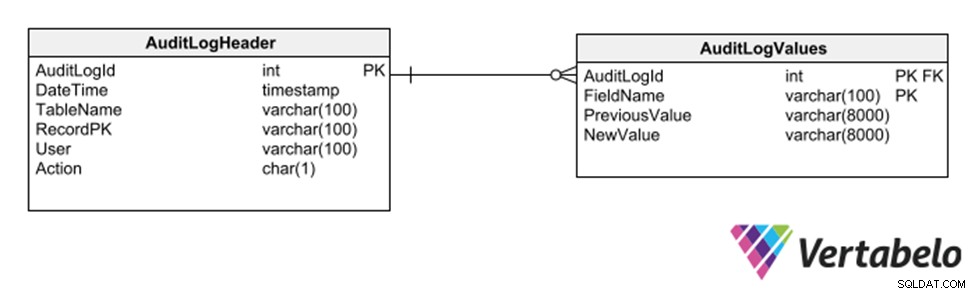
データベースの監査証跡を保持するための汎用テーブル。
この戦略には、監査証跡を記録するためにモデルを変更する必要がないという利点があります。ただし、varcharタイプの汎用列を使用するため、ログトレイルに記録できるデータのタイプが制限されます。
パフォーマンスの維持とインデックスの作成
実際には、データベースが使用され始めたばかりで、そのテーブルに含まれる行が数行しかない場合、どのデータベースでも優れたパフォーマンスが得られます。ただし、アプリケーションがデータの入力を開始するとすぐに、モデルの設計に注意を払わないと、パフォーマンスが急速に低下する可能性があります。これが発生すると、DBAとシステム管理者は、パフォーマンスの問題を解決するためにあなたを支援するように求めます。
本番データベースでのインデックスの自動作成/提案は、「瞬間的な」パフォーマンスの問題を解決するための便利なツールです。データベースエンジンは、データベースアクティビティを分析して、最も時間がかかる操作と、インデックスを作成することで高速化する機会がある場所を確認できます。
ただし、データモデルの一部としてインデックスを定義することにより、積極的に状況を予測する方がはるかに優れています。これにより、データベースのパフォーマンスを向上させるためのメンテナンス作業が大幅に削減されます。データベースインデックスの利点に精通していない場合は、非常に基本的なものから始めて、インデックスについてすべて読むことをお勧めします。
効率的なクエリのための最も重要なインデックスを作成するための十分なガイダンスを提供する実用的なルールがあります。 1つは、各テーブルの主キーのインデックスを生成することです。実際には、すべてのRDBMSが各主キーのインデックスを自動的に生成するため、このルールを忘れることができます。
もう1つのルールは、特に代理キーが作成されるテーブルで、テーブルの代替キーのインデックスを生成することです。テーブルに主キーとして使用されていない自然キーがある場合、そのテーブルを他のテーブルと結合するクエリは、サロゲートではなく自然キーを使用して結合する可能性が非常に高くなります。自然キーにインデックスを作成しない限り、これらのクエリはうまく機能しません。
インデックスの次の経験則は、外部キーであるすべてのフィールドに対してインデックスを生成することです。これらのフィールドは、他のテーブルとの結合を確立するための優れた候補です。それらがインデックスに含まれている場合、実行を高速化し、データベースのパフォーマンスを向上させるためにクエリパーサーによって使用されます。
最後に、パフォーマンステスト中にステージングまたはQAデータベースでプロファイリングツールを使用して、明らかでないインデックス作成の機会を検出することをお勧めします。プロファイリングツールによって提案されたインデックスをデータモデルに組み込むことは、データベースが本番環境に移行した後のパフォーマンスを達成および維持するのに非常に役立ちます。
セキュリティ
データモデラーとしてのあなたの役割では、ユーザー認証用のデータを保存するための強固で安全な基盤を提供することにより、データベースのセキュリティを維持するのに役立ちます。この情報は非常に機密性が高く、サイバー攻撃にさらされてはならないことに注意してください。
データベースセキュリティの保守を簡素化する設計では、認証データを保存するためのベストプラクティスに従います。その主な方法は、暗号化された形式でもパスワードをデータベースに保存しないことです。各ユーザーのパスワードではなくハッシュのみを保存することで、アプリケーションはパスワードにさらされるリスクを冒すことなく、ユーザーのログインを認証できます。
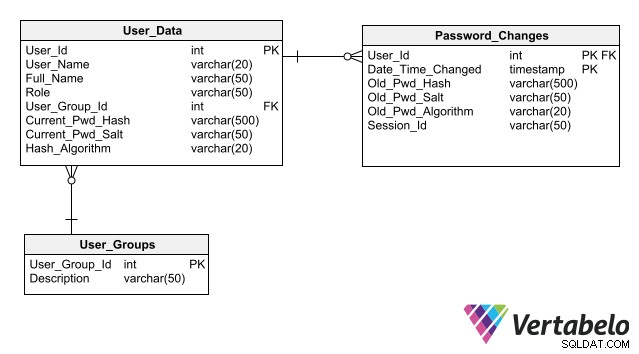
パスワードハッシュを格納するための列を含む、ユーザー認証の完全なスキーマ。
未来へのビジョン
したがって、上記のヒントを考慮して、優れたデータベース設計でデータベースの保守を容易にするモデルを作成してください。より保守しやすいデータモデルを使用すると、作業の見栄えが良くなり、DBA、保守エンジニア、およびシステム管理者の評価を得ることができます。
あなたも安心に投資します。保守が容易なデータベースを作成するということは、正しい情報を時間どおりに提供できないデータベースにパッチを適用するのではなく、新しいデータモデルの設計に作業時間を費やすことができることを意味します。