データモデルに多言語サポートを実装するために、車輪の再発明を行う必要はありません。この記事では、それを行うためのさまざまな方法を紹介し、自分に最適な方法を選択するのに役立ちます。
ローカリゼーションの概念は、特にそのアプリケーションのスコープがグローバルである場合、ソフトウェアアプリケーションの開発に不可欠です。複数の言語のサポートは、考慮すべき主な側面です。多言語アプリケーションをサポートするデータベース設計により、ターゲット市場を多様化して、より多くの顧客にリーチすることができます。さらに、このようなデータベース設計は、ローカリゼーション対応システムを設計するための長期戦略の一部になる可能性があります。
多言語サポートをアプリケーションに組み込むための鍵は、開発または保守のコストを大幅に増加させない方法でそれを行うことです。データベースモデリングはソフトウェア開発プロセスの不可分の一部であるため、アプリケーションに多言語サポートを提供するための最良のデータモデル設計戦略を考える必要があります。
適切なデータモデルにより、余分な労力やコストを追加することなく、多言語サポートを維持しながら、アプリケーションを変更したり、新しい機能を追加したりできるはずです。また、アプリケーションに触れることなく新しい言語を組み込むことができるはずです。対応する翻訳データをデータベースに追加するだけです。
シンプルな実装と柔軟性および機能性
多言語アプリケーション用のデータベース設計を作成するには、さまざまなアプローチがあります。それぞれに長所と短所があります。実装が簡単なものは、柔軟性と機能性が低くなります。より柔軟性と機能性を提供するものは、より複雑な実装を持っています。
ここでの私のアドバイスは、常により多くの機能と柔軟性を提供するものを選ぶことです。 、実装するのに費用がかかる場合でも。アプリケーションが小さすぎる、多言語サポートなどを解決するために複雑なスキーマを実装する価値がない、と誤解することがあります。しかし、最終的には、そのアプリケーションは成長し、よりシンプルで安価に思えた「迅速で汚い」アプローチを選択したことを後悔します。
多言語サポート、変更ログ、ユーザー認証など、アプリケーションにアクセサリ機能を実装するための理想は、その機能が独自のサブスキーマとそのロジックを再利用可能なコンポーネントにカプセル化することです。このようにして、アクセサリ機能とそのサブスキーマの両方を最小限の労力で新しいアプリケーションに組み込むことができます。
Vertabeloのようなインテリジェントなデータベース設計およびデータモデリングツールは、スキーマとサブスキーマの効率的な管理に非常に役立ちます。また、データベース設計を改善するためにこれらのヒントを確認し、それらすべてに従うようにしてください。 ERダイアグラムの描画を開始する前に、この重要な一連のデータベースモデリングのヒントを検討することをお勧めします。
魅力的な(しかしお勧めできない)多言語データベース設計ソリューション
最も簡単–ただし推奨されない
多言語アプリケーションデータベースを実装するための、最も推奨されていないが最も簡単な方法から始めましょう。多言語アプリケーションをサポートする必要性をすばやく解決できますが、アプリケーションの機能や地理的範囲が大きくなると問題が発生します。
この単純な戦略は、翻訳が必要なテキストの各列と、テキストを翻訳する必要のある言語ごとに1つの列を追加することで構成されます。
たとえば、Movies 以下の表には、OriginalTitleがあります。 分野。翻訳する言語ごとにタイトル列が追加されます:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | ダイハード | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | バックトゥザフューチャー | Volver al futuro | Ritorno al futuro | バック・トゥ・ザ・フューチャー |
| 3 | ジュラシックパーク | ジュラシックパーク | ジュラシコパルコ | ジュラシックパーク |
アプリケーションは、ユーザーが選択した言語に対応する列から説明データを取得する必要があります。新しい言語を追加する必要がある場合は、新しい言語に翻訳されたテキストを含めるために、テーブルに列を追加する必要があります。また、追加された言語と列を確認するようにアプリケーションを調整する必要があります。
このソリューションでは、翻訳されたテキストを取得するために複雑なJOINは必要ありません。また、複製されたレコードも必要ありません。テキストコンテンツ列の複製のみが必要です。ただし、その適用範囲は、少数のテーブルのみを変換する必要がある状況に限定されます。
たとえば、Productsがあるとします。 テーブルとProcesses テーブル。それぞれに、翻訳が必要な説明フィールドがあります。簡単そうですね。ただし、アプリケーション全体(すべてのメニューオプション、エラーメッセージなどを含む)を多言語にする必要がある場合、このソリューションは適用できません。
より用途が広いが、お勧めできません
同じテーブル内に翻訳を保持するという考えを継続して、前のオプションの代わりに、テキストフィールドを拡大することもできます。これにより、すべての翻訳を同じフィールドに保存し、データ構造(XMLドキュメントやJSONオブジェクトなど)に整理することができます。以下に例を示します:
| MovieId | OriginalTitle | 翻訳 |
| 1 | ダイハード | [ {"言語": "sp"、 "タイトル": "Duro de matar"}、 {"言語": "it"、 "タイトル": "Trappola di cristallo"}、 {"言語": "fr"、 "タイトル":"Piègedecristal"} ] |
| 2 | バック・トゥ・ザ・フューチャー | [ {"言語": "sp"、 "タイトル": "Volver al futuro"}、 {"language": "it"、 "title": "Ritorno al futuro"}、 {"language": "fr"、 "title": "Retour vers le futur"} ] |
| 3 | ジュラシックパーク | [ {"言語": "sp"、 "タイトル": "ジュラシックパーク"}、 {"言語": "それ"、 "タイトル": "ジュラ紀パルコ"}、 {"言語": "fr"、 "タイトル":"ジュラシックパーク"} ] |
このオプションは追加の列を必要としませんが、複雑さを追加します。データクエリは、多言語サポートに使用されるデータ構造を正しく処理および解釈できる必要があります。たとえば、JSONまたはXMLを使用して翻訳を保存する場合、SQLクエリは選択したデータ型をサポートするSQLバージョンを使用する必要があります。
次のSQLコマンドは、MS SQLServerのOPENJSON()を使用します Translationsのコンテンツを使用する関数 従属テーブルとしてのフィールド:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
標準SQLにはJSONまたはXML形式のデータを操作する関数や演算子がないため、この手法を使用して翻訳されたテキストを保存する場合は、特定のRDBMSのクエリを作成する必要があります。たとえば、前のクエリはMySQLではサポートされていません。 Movies MySQLを使用したテーブルの場合、次のクエリを記述します:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
翻訳されたテキストをさまざまなレコードに保存する
言語ごとに異なるレコードを使用することもできます。ただし、正規化を失うことを辞任する必要があります。同じデータが複数のレコードで繰り返され、翻訳のみが異なります。
| MovieId | LanguageId | タイトル |
|---|---|---|
| 1 | en | ダイハード |
| 1 | sp | Duro de matar |
| 1 | それ | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | en | バックトゥザフューチャー |
| 2 | sp | Volver al futuro |
| 2 | それ | Ritorno al futuro |
このオプションを使用すると、特定の言語の行のみを返す各テーブルのビューを作成できます。
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
次に、テーブルをクエリするために、ターゲットの翻訳言語に応じて異なるビューを使用できます。ただし、モデルの正規化は失われ、テーブルのメンテナンスは不必要に複雑になります。
翻訳されたテキストを別々のテーブルに保存する
リレーショナルモデルを壊さずに翻訳されたテキストを保存する1つの方法は、翻訳されるテキストを含む各テーブルの詳細テーブルを用意することです。翻訳を含む従属テーブルには、マザーテーブルと同じキーフィールドに加えて、翻訳言語を示すフィールドが必要です。
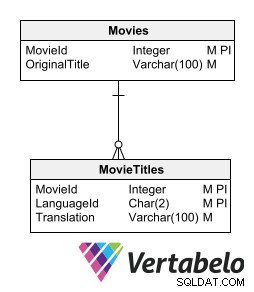
翻訳を含む従属テーブルには、マザーテーブルと同じキーフィールドに加えて、翻訳言語を示すフィールドが必要です。
このオプションを使用すると、テーブル構造を変更せずに新しい言語を組み込むことができます。冗長な情報を生成したり、モデルの正規化を破ったりする必要はありません。
このオプションの欠点は、翻訳が必要なテキストデータを格納するテーブルごとに従属テーブルを作成する必要があることです。ただし、関連するテーブルに翻訳を保存するというアイデアは、多言語データベースを設計するための最も推奨される方法に近づきます。
ユニバーサルソリューション:翻訳サブスキーマ
アプリケーションとそのデータベースが真に多言語であるためには、特定のテーブルのテキストデータだけでなく、すべてのテキストにサポートされている各言語の翻訳が必要です。これは、ユーザーの目に届く可能性のあるテキストコンテンツを含むすべてのデータが保存される翻訳サブスキーマで実現されます。
さまざまな言語での使用を目的としたWebアプリケーションでは、翻訳サブスキーマが必要であり、オプションではありません。それ以外の場合は、アプリケーションの適切なメンテナンスを不可能にする複雑さにつながります。
翻訳を別のスキーマに保持するための鍵は、エンティティの説明、エラーメッセージ、メニューオプションなど、翻訳が必要なすべてのテキストを含むインデックス付きカタログを維持することです。このサブスキーマ以外のテーブルには、ユーザーの目に届くテキストは保存されないという考え方です。
翻訳カタログを整理する1つの方法は、次の3つのテーブルを使用することです。
- 言語のマスターテーブル。
- 元の言語のテキストの表。
- 翻訳されたテキストの表。
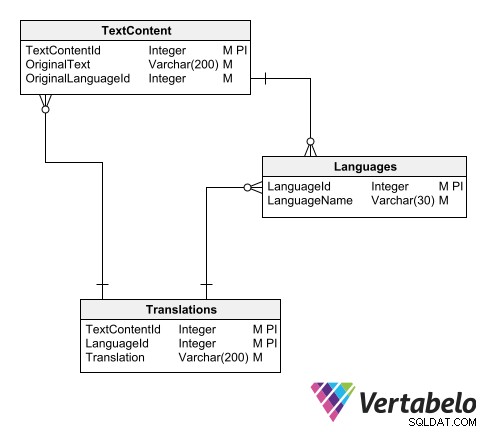
ユニバーサル翻訳カタログのスキーム。
言語のマスターテーブルに、データモデルでサポートされている各言語のレコードを挿入するだけです。それぞれにIDコードと名前があります:
| LanguageId | LanguageName |
|---|---|
| en | 英語 |
| sp | スペイン語 |
| それ | イタリア語 |
| fr | フランス語 |
テキストテーブルには、翻訳が必要なすべてのテキストが記録されます。各レコードには、任意のID、元のテキスト、および元の言語のIDがあります。
TextContent 表、元のテキスト、元の言語のIDは厳密には必要ありません。しかし、それらは翻訳を必要としないクエリを単純化します。たとえば、統計分析または管理制御クエリ(通常は元の言語を理解しているユーザーのみが利用可能)を実行する場合、デフォルトの(翻訳されていない)テキストを使用してクエリを簡略化できます。
元のテキストは、翻訳されたテキストの表に記入する必要がある人にも役立ちます。翻訳データの入力は、元のテキストと利用可能なすべての言語の翻訳を表示するミニアプリケーションを使用して行うことができます。翻訳APIを使用した自動プロセスを通じて、翻訳サブスキーマの情報を生成することもできます。
メインスキーマとのリンク
アプリケーションのメインスキーマでは、翻訳が必要なテキスト値を持つ列は、翻訳されたテキストのテーブルを指すIDに置き換えられます。
メインスキーマは、翻訳が必要なテキストを含むテーブルを介して翻訳スキーマにリンクされています。
冗長な情報が生成される場合でも、翻訳が不要なクエリを容易にするために、一部のメインスキーマテーブルに元のテキストフィールドを残すことができます。たとえば、ProductDescriptionを保持する場合があります Productsのフィールド 統計クエリを容易にするため、またはデータウェアハウスのディメンションにデータを入力するためのテーブル。必要のない場合は、翻訳サブスキーマを脇に置きます。
- 多言語データベース設計:一度実行して正しく実行する
多言語データベース設計を作成するためのいくつかの代替案を見てきました。実装がより簡単で高速なものもあります。最後の解決策はもう少し複雑ですが、はるかに柔軟性があります。また、アプリケーションとデータベースを保守するときが来たときに、トラブルを回避できます。したがって、長期的には、はるかに安価になります。
時々、データベース設計の最短経路は、あなたが時間と労力を節約すると信じるようにあなたを誘惑します。しかし、それを選ぶとき、あなたはおそらくそれを数回降りなければならないという事実を見落としています。多言語データベース設計のベストプラクティスを無視すると、同じ仕事を何度も繰り返すことになります。