統合トランスポートは、インターネットやニュースでよく耳にするものです。これは新しいことではありませんが、常に継続的な変更が行われていることは間違いありません。今日は、ゾーン、乗客、チケットの情報を処理できるデータモデルを見ていきます。
すべての背後にある考え方から始めて、統合されたトランスポートデータモデルを掘り下げてみましょう。
アイデア
輸送の統合は、その効率を最大化し、顧客にとっては使いやすさを最大化するために必要です。統合はコストだけでなく、時間、アクセスのしやすさ、快適さ、安全性にも関係しています。これは、大都市だけでなく小都市にも当てはまります。アイデアは、既存の輸送インフラストラクチャを使用し、より良い結果を得るためにそれを最適化することです。これは、新しいスケジュール、通知、回線、またはステーションを考え出すことを意味する場合があります。バスを待つか、自転車を借りるか、目的地まで歩いて行くかを決めるには、情報があれば十分かもしれません。
2つの例を使用してこれを説明しましょう。
大都市の場合、バス、タクシー、路面電車、鉄道、地下など、さまざまな交通手段が利用できます。これにより、さまざまな民間企業がさまざまな交通サービスを提供する可能性があります。これらのサービスのいくつかを組み合わせても、コストを削減し、効率を高め、チケットあたりのサービスを増やすことで、乗客と企業に確実に利益をもたらします。
小さな都市にも同様のメリットがあります。組み合わせるオプションの数は同じではないかもしれませんが、最大の効率を達成するためにそれらを編成することはできます。
この記事では、主に統合されたトランスポートチケットシステムに焦点を当てます。統合とさまざまな種類の輸送のすべての側面に焦点を当てるわけではありません。複雑すぎます。
これを念頭に置いて、モデルに移りましょう。
データモデル
モデルは2つのサブジェクトエリアで構成されています:
都市と企業チケット
リストされている順序で説明します。
都市と企業
最初のサブジェクトエリアには、都市に輸送ゾーンを設定するために必要なすべてのテーブルを保存します。
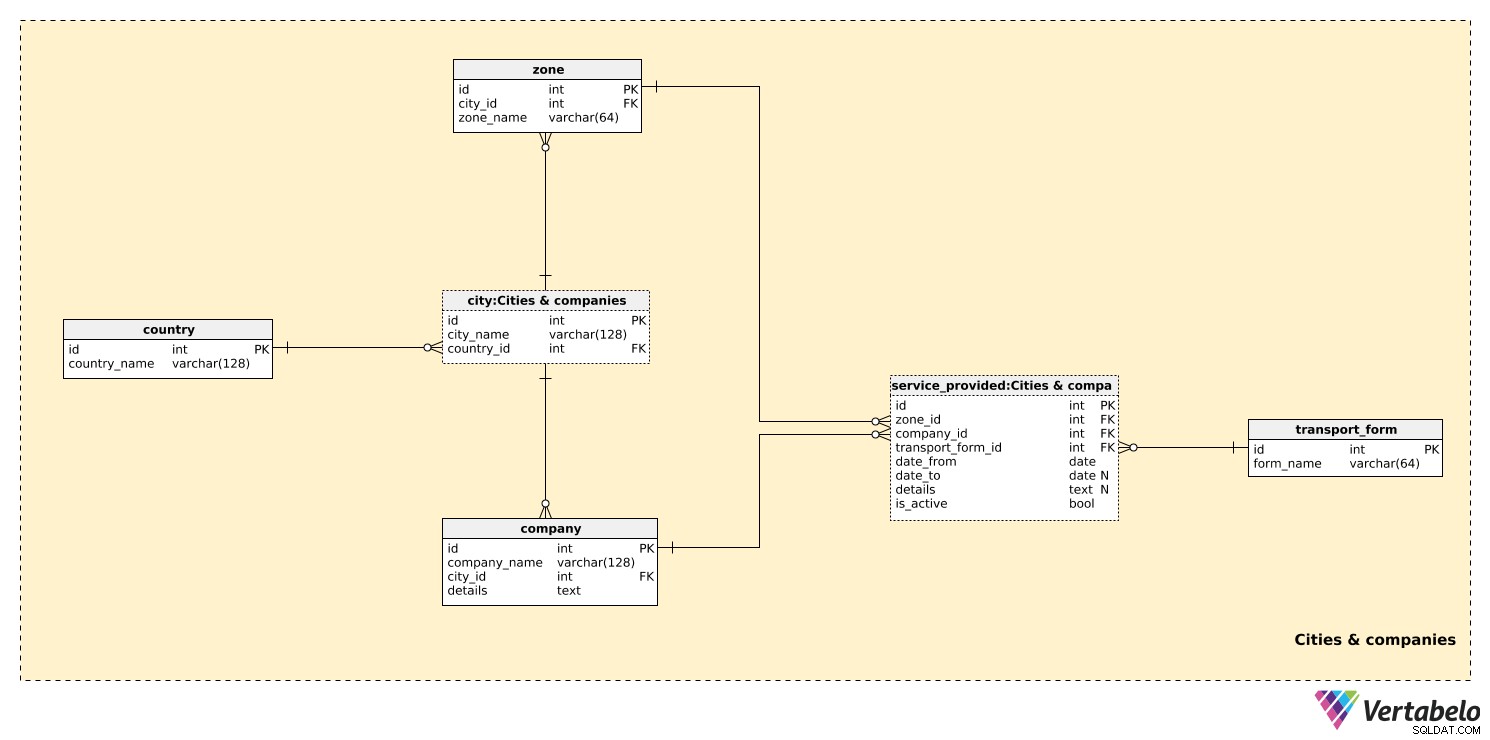
国 テーブルには、UNIQUE country_nameのリストが含まれています 値。このテーブルは、 cityでの参照としてのみ使用されます テーブル。私たちのモデルは1つの国のみの輸送をカバーすることが期待できますが、複数の国を含めるオプションが必要です。都市ごとに、一意の組み合わせ city_nameを保存します – country_id 。
小さな都市にはおそらく1つのゾーンしかありませんが、大きな都市には複数のゾーンがあります。可能なすべてのゾーンのリストがzoneに保存されます テーブル。ゾーンごとに、その zone_nameを保存します および関連する都市への参照。このペアは、このテーブルの代替キーを形成します。
私たちのシステムは、複数の運送会社に関する情報を保存することが期待できます。企業は独自のチケットを発行しますが、他の企業と共同でチケットを発行することもできます。 会社ごとに 、 company_nameの一意の組み合わせを保存します およびcity_id それが置かれている場所。必要な追加情報は、テキストの detailsに保存できます。 フィールド。
最後に定義する必要があるのは、各企業が提供する交通手段です。期待値には、「バス」、「路面電車」、「地下」、「鉄道」などがあります。 transport_formの値ごとに テーブルには、UNIQUEform_nameを格納します。
-
zone_id–ゾーンを参照します表は、この輸送形態がこの会社によって提供されている地域を示しています。 -
company_id–companyを参照しますこのゾーンでこのサービスを提供します。 -
Transportation_form_id–transport_formを参照します表は、提供されるサービスの種類を示します。 -
date_fromおよびdate_to–このサービスがこの会社によって提供された期間。date_toに注意してください このサービスがまだ利用可能であるか、有効期限が予想されていない場合は、NULL値を含めることができます。 詳細 –構造化されていないテキスト形式の他のすべての詳細。-
is_active–このサービスがアクティブ(継続中)であるかどうか。これは、date_fromの代わりに使用できる単純なオン/オフスイッチです。 –date_toサービスアクティビティ間隔。この属性の最適な使用法は、クエリを単純化することです。つまり、日付間隔をテストしてNULL値で「再生」する代わりに、この値をテストすることです。
チケット
前の主題分野は、主なもの、つまりチケットの準備にすぎませんでした。そして、それがこの主題分野がカバーするものです。
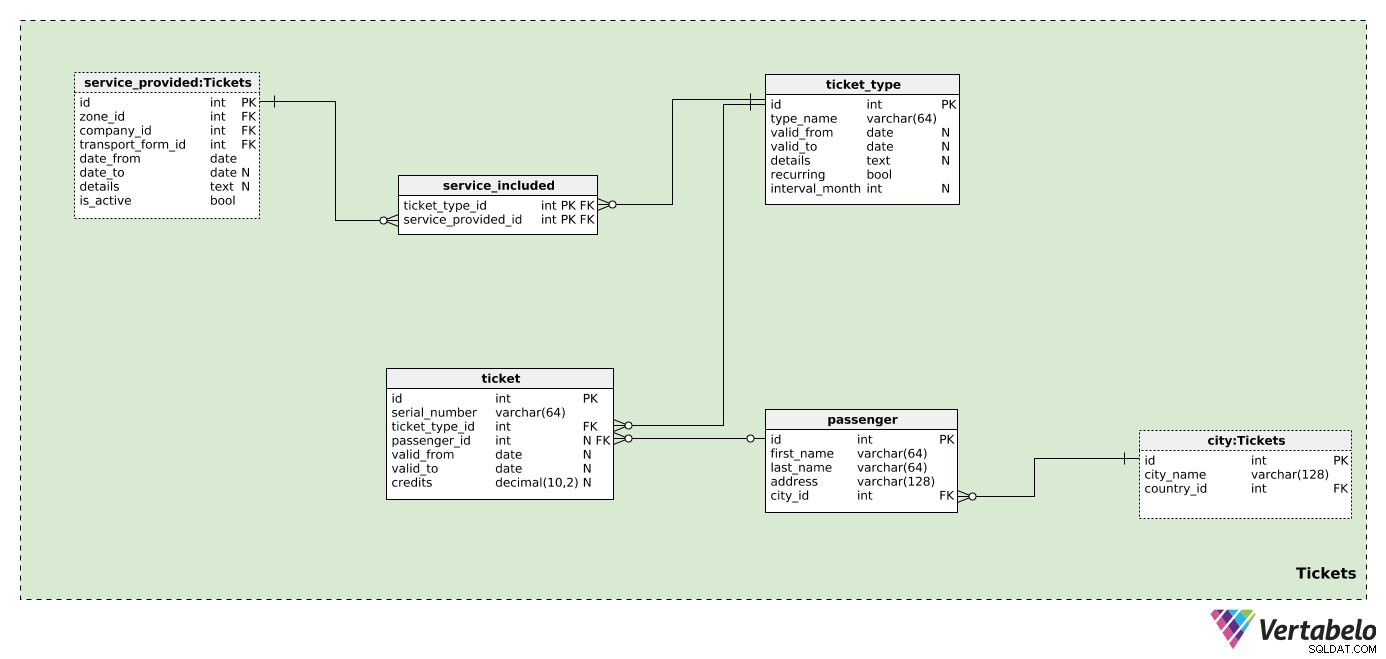
会社、ゾーン、交通機関のフォームを定義しましたが、このモデルのコアである乗客とチケットの準備はありません。 1つ以上の企業がカバーする1つ以上のゾーンに1つのチケットを使用できると想定します。
したがって、最初に各 ticket_typeを定義する必要があります 。この表では、データベース内の企業が販売している可能性のあるすべての種類のチケットを一覧表示します。タイプごとに、次の値を保存します。
-
type_name–このタイプを一意に示す名前。 -
valid_fromおよびvalid_to–このチケットタイプが有効であった(または有効だった)期間。どちらのフィールドもnull許容です。 NULL値は、これが有効だった開始日(または終了日)がないことを意味します。 詳細 –構造化されていないテキスト形式の必要な詳細。繰り返し–このチケットタイプが定期的(たとえば、毎年、毎月)であるかどうかを示すフラグ。-
interval_month–チケットタイプが繰り返し発生する場合、この属性には、繰り返し発生する間隔が月単位で含まれます(たとえば、月次チケットの場合は「1」、年次チケットの場合は「12」)。
これで、各チケットタイプがカバーするゾーンを定義する準備が整いました。 service_included内 テーブルでは、UNIQUEペア ticket_type_idのみを保存します – service_available_id 。後者は、このチケットを使用できる会社とゾーンも示します。このテーブルでは、チケットごとに複数のゾーンを定義できます。ゾーンは異なる会社に属する可能性があります。これらは事前定義されたチケットタイプであるため、各チケットタイプには、ここで定義されたゾーンがあります(個々の乗客ごとではありません)。
このモデルでは、乗客の詳細をあまり多く保存しません。 乗客ごとに 、 first_nameのみを保存します 、 last_name 、 address 、および彼らが住んでいる都市への参照。このデータはすべてチケットに表示されます。
モデルの最後のテーブルはticket です テーブル。ここでは使い捨てチケットには焦点を当てません。むしろ、サブスクリプションとプリペイドチケットを処理します。これらのチケットには、残高、有効日、またはその両方があります。これは、会社とその規則に基づいて大幅に異なる可能性があります。数社がチケットを発行することを決定した場合、この表でそれをサポートできます。重要な詳細をすべて把握できます。チケットごとに、以下を保存します:
-
serial_number–各チケットの一意の指定。これは数字と文字の組み合わせである可能性があります。 -
ticket_type_id–そのチケットのタイプを参照します。 -
passenger_id–そのチケットを所有している乗客(存在する場合)を参照します。プリペイドチケットの場合、所有者がいない可能性があります。 -
valid_fromおよびvalid_to–このチケットが有効である期間を示します。 NULL値は、下限または上限がないことを示します。 クレジット–そのチケットで現在利用可能なクレジット(数値として)。プリペイドチケットの場合、乗客はチケットに追加のクレジットを購入すると想定できます。チケットが1か月間(または他の期間)有効であり、使用に制限がない場合、この値はNULLになる可能性があります。
統合トランスポートデータモデルの改善
このモデルが大幅に簡略化されていることがわかります。これは、統合トランスポートが大きすぎて1つの記事でカバーできないためです。このモデルでは変更できると思うことがいくつかあります:
- ゾーンが単純化されすぎています。それらをより動的に定義できるはずです。
- 路線(バス路線など)は対象外です。あるゾーンから別のゾーンに移動した場合などはどうなりますか?
- チケットの使用履歴は保存されません。
- 企業や乗客の登録はありません。
これらはすべて、重要なデータが不足していて、より詳細な分析を行うことができないという事実につながります。それで、あなたはどう思いますか?このモデルには何が必要ですか?何を追加または削除しますか?コメントであなたのアイデアを共有してください。