以前、NOEXPANDを使用する利点について書きました。 EnterpriseEditionでもヒント。詳細はすべてリンクされた記事にありますが、簡単に要約すると:
- SQLServerは自動的に作成するだけです
NOEXPANDの場合のインデックス付きビューの統計 テーブルヒントが使用されます。このヒントを省略すると、統計を手動で作成しても解決できない統計の欠落に関する実行プランの警告が発生する可能性があります。 - SQLServerはのみを使用します クエリがビューと
NOEXPANDを直接参照する場合、カーディナリティ推定計算で自動または手動で作成されたビュー統計 ヒントが使用されます。最も些細なビュー定義を除くすべての場合、これは、このヒントを使用しない場合、カーディナリティ推定の品質が低下する可能性が高く、多くの場合、最適な実行計画が得られないことを意味します。 - ビュー統計がない、または使用できない場合、ベーステーブルの統計が利用可能な場合でも、オプティマイザはカーディナリティの推定値を推測する可能性があります。これは、クエリプランの一部が、自動ビューマッチング機能によってインデックス付きビュー参照に置き換えられたが、上記のようにビュー統計が利用できない場合に発生する可能性があります。
NOEXPANDを使用しない場合の別の結果があります ヒントは、数年前の記事「フィルター処理されたインデックスを使用したオプティマイザーの制限」で言及しました:
NOEXPANDEnterprise Editionでも、ビューインデックスによって提供される一意性の保証がオプティマイザによって使用されるようにするためのヒントが必要です。
この記事では、そのステートメントとその意味を詳しく調べます。
デモのセットアップ
次のスクリプトは、単純なテーブルとインデックス付きビューを作成します。
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); これにより、単一列のヒープテーブルと、一意のクラスター化インデックスを持つ同じテーブルの無制限のビューが作成されます。これは、インデックス付きビューの現実的な使用例を意図したものではありません。しかし、それは気を散らすものを最小限に抑えて重要なポイントを説明するのに役立ちます。重要な点は、ここのベーステーブルにはインデックスがまったくない(クラスター化インデックスもない)が、ビューにはインデックスがあり、そのインデックスは一意であるということです。
クエリの例
ベーステーブルに対する次の簡単なクエリについて考えてみます。
SELECT DISTINCT
T.col1
FROM dbo.T AS T; このクエリに表示される実行プランは、使用しているSQLServerのエディションによって異なります。 Enterprise Edition(または同等のもの)でない場合は、次のようなプランが表示されます:

SQL Serverクエリオプティマイザーは、ベーステーブルをスキャンし、DistinctSort演算子を使用して指定された識別性を適用することを選択しました。 Enterprise Edition以外では自動インデックスビューマッチングを使用できないため、この平面形状は完全に予想されます。これ以降、「Enterprise Editionまたは同等のもの」と言うのはやめますが、これから「Enterprise Edition」と言うときは、自動ビューマッチングをサポートするエディションを意味していると推測し続けてください。
EXPANDVIEWSヒント
これは少し脇にありますが、Enterprise Editionで同じプランを取得するには、EXPAND VIEWSを使用する必要があります。 クエリのヒント:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
ビュー参照がないときにこのヒントを使用するのは少し奇妙に思えるかもしれません。 クエリで、しかしそれはそれがどのように機能するかです。 EXPAND VIEWS ヒントは、クエリのコンパイルと最適化中にインデックス付きビューのマッチングを無効にすることを効果的に指定します。明確にするために:このヒントがないと、Enterprise Editionはクエリ(の一部)を1つ以上のインデックス付きビューに一致させる可能性があります。
自動ビューマッチングを有効にした場合
EXPAND VIEWSなし ヒント、たとえば、Developer Editionで同じクエリをコンパイルすると、異なるプランが生成されます。
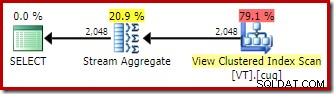
インデックス付きビューマッチングの適用は、実行プランがベーステーブルスキャンの代わりにビュークラスター化インデックスのスキャンを特徴とすることを意味します。
この場合、クエリが(ベーステーブルではなく)ビューを直接参照している場合、同じプランが作成されます。
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; すべてのエディションで、クエリの最適化が開始される前にビュー参照が展開されます。 Enterpriseと同等のエディションでは、展開されたフォームは後でビューに一致する場合があります。これは、クエリコンパイラとオプティマイザがSQLServerでインデックス付きビューをどのように使用するかを考えるときに理解するための重要な概念です。
ストリームアグリゲート
これまでに見た2つのプランの最も興味深い違いは、ビューが一致したプランのStreamAggregateです。テーブルスキャン演算子とビュースキャン演算子の推定コストを見ると、まったく同じであることがわかります。オプティマイザーは、データへのアクセスをより安価にしたため、インデックス付きビューを使用することを決定しませんでした。むしろ、ビューインデックスをスキャンすると、DISTINCTが可能になります (最初の計画のように)ハッシュアグリゲートまたは個別ソートではなく、ストリームアグリゲートとして実装する必要があります。
Stream Aggregateには、グループ化列の順序で入力が必要です。この場合、distinctは単一の列によるグループ化と同等であり、ビューの一意のクラスター化インデックスが必要な順序付けを保証します。オプティマイザーのコストモデルは、このクエリの個別ソートまたはハッシュアグリゲートよりも安価なオプションとしてストリームアグリゲートを識別します。これは、自動ビューマッチングが利用可能な場合に、オプティマイザがインデックス付きビューにアクセスすることを選択するための基礎です。
以上のことをすべて理解しても、Stream Aggregateはまだ予想外です。ビューインデックスによって提供される一意性の保証を考えると、このグループ化操作を実行する必要はまったくありません。 ユニーク クラスタ化インデックスにより、列に重複が含まれていないことがすでに保証されています。
これは、一言で言えば、問題です。自動ビューマッチングが使用される場合、オプティマイザはビューインデックスによって提供される順序保証を認識しますが、一意性保証は認識しません。
NOEXPANDヒントの使用
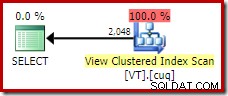
このクエリの理想的な実行プランを取得するには、ビューを直接参照し、NOEXPANDを使用する必要があります。 テーブルのヒント:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); これにより、経験豊富なデータベース担当者が期待する計画が得られます。個別の操作が冗長であり、削除できることを正しく認識するもの:
2番目の例
ビューインデックスによって提供される一意性の保証を利用できないと、最終的な実行プランに他の影響を与える可能性があります。ここで、インデックス付きビューの自己結合について考えてみましょう(ここでも、概念を説明するためだけに、これは現実的なクエリを意図したものではありません):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Developer Editionを使用すると、選択した実行プランはインデックス付きビューにまったくアクセスせず、ハッシュ結合を備えています(有用なインデックスが欠落していることを示す場合もあります):
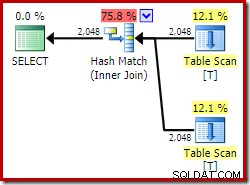
次に、まったく同じクエリを試してみましょう。ただし、NOEXPAND 各ビュー参照のヒント:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; 実行プランには、2つのインデックス付きビューアクセスとマージ結合が含まれるようになりました。
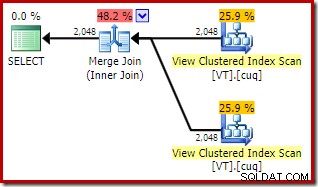
この新しいプランの推定コストはハッシュ結合プランよりもはるかに低いのに、オプティマイザーが以前にこのオプションを選択しなかったのはなぜですか?元のクエリにマージ結合ヒントを追加することで、その理由を理解できます。
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
これにより、似たようなが得られます。 NOEXPANDであっても、ビューへのアクセスを選択するプラン 指定されていません:
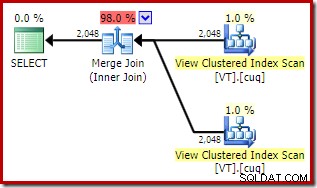
この計画の全体的な推定コストは、前の両方の例よりも高くなっています。このプランのマージ参加は、以前よりも推定総コストの高い割合を占めています(98%対48.2%)。
この理由は、マージ結合のプロパティを確認することでわかります。 NOEXPANDで 計画では、それは1対多のマージ結合でした。真上の計画では、多対多のマージ結合です。オプティマイザーのコストモデルでは、重複を処理するためにtempdbワークテーブルが必要になるため、多対多のマージ結合に高いコストが割り当てられます。
結論
一意のインデックスによって提供される保証は強力な最適化ツールになる可能性があるため、自動インデックスマッチングが現在それを利用できないのは残念です。潜在的な利点は、前述の簡単な例に見られるように、不要な集約を排除したり、1対多のマージ結合を有効にしたりすることだけではありません。一般に、オプティマイザーが一意性の保証を利用できなかったため、実行プランが最適ではないことを見つけるのは難しい場合があります。
このオプティマイザの制限は、ビューが実体化されるために必要な一意のクラスタ化されたインデックスにのみ適用されません。より複雑なシナリオでは、追加の非クラスター化インデックスもビューに存在する場合があります。おそらく、他の方法で実施または表現することが難しいクロステーブル関係を反映するためです。これらの非クラスター化インデックスが一意であると定義されている場合、自動インデックスマッチングが使用されていると、オプティマイザーはこれらの保証も見落とします。
これを統計情報の作成と使用に関する制限に追加すると、自動ビューマッチングに依存すると、実行計画が劣る可能性があるようです。最も安全なオプションは、インデックス付きビューを明示的に参照し、NOEXPANDを使用することです。 毎回ヒント–少なくともこれらの問題が製品で解決されるまで。
緩和要因
この記事で説明されている問題は、一意のビューインデックスによって提供される一意性の保証にのみ適用されることを強調しておく必要があります。オプティマイザが必要な一意性情報を別の方法で取得できる場合 、最適化問題が回避される可能性が高いです。
たとえば、ビューによって参照されるベーステーブルに適切な一意のインデックスがある場合があります。または、集計を含むビューの場合、オプティマイザーはビューのGROUP BYから有用な一意性の保証をすでに推測できます。 句。ビュークラスター化インデックスをグループ化キーに追加する一般的な方法では、その場合、追加の一意性情報は追加されません。
それでも、この「一意性の監視」により、明示的なビュー参照とNOEXPANDを使用することで、より高品質の実行計画を取得できる場合があります。 EnterpriseEditionでもヒント。