データベースシステムを設計し、ビジネスプロセスをデータモデルにマッピングする方法を学びたいですか?その後、この投稿はあなたのためです。
この記事では、採用会社向けの簡単なデータベーススキーマを設計する方法を説明します。このチュートリアルを読むと、実際のアプリケーション用にデータベーススキーマがどのように設計されているかを理解できるようになります。
採用システムのビジネスプロセス
データベースまたはデータモデルを設計する前に、そのシステムの基本的なビジネスプロセスを理解することが不可欠です。作成するデータベーススキーマは、架空の求人企業またはチーム向けです。まず、新入社員の採用に関連する手順を見てみましょう。
- 企業は、彼らに代わって採用するために採用担当者に連絡します。場合によっては、企業は従業員を直接募集します。
- 採用担当者が採用プロセスを開始します。このプロセスには、最初のスクリーニング、筆記試験、最初の面接、フォローアップ面接、実際の採用決定など、複数のステップがあります。
- 採用担当者が特定のプロセスに合意すると(これは、クライアント、会社、または問題の仕事によって変わる可能性があります)、欠員はさまざまなプラットフォームで宣伝されます。
- 応募者は仕事への応募を開始します。
- 応募者は最終候補者に選ばれ、テストまたは最初の面接に招待されます。
- 応募者はテスト/面接に参加します。
- テストは採用担当者によって採点されます。場合によっては、テストは採点のために専門家に転送されます。
- 応募者の面接は、1人以上の採用担当者によって採点されます。
- 応募者は、テストと面接に基づいて評価されます。
- 採用決定が行われます。
採用システムデータベーススキーマ
前述のプロセスを考慮して、データベーススキーマは5つのサブジェクトエリアに分割されています。
ProcessJobs-
Application, Applicant, and Documents Test and InterviewsRecruiters and Application Evaluation
これらの各領域を、リストされている順序で詳細に確認します。以下に、データモデル全体を示します。
プロセス
プロセスカテゴリには、採用プロセスに関連する情報が含まれています。 3つのテーブルが含まれています:process 、step 、およびprocess_step 。それぞれを見ていきます。
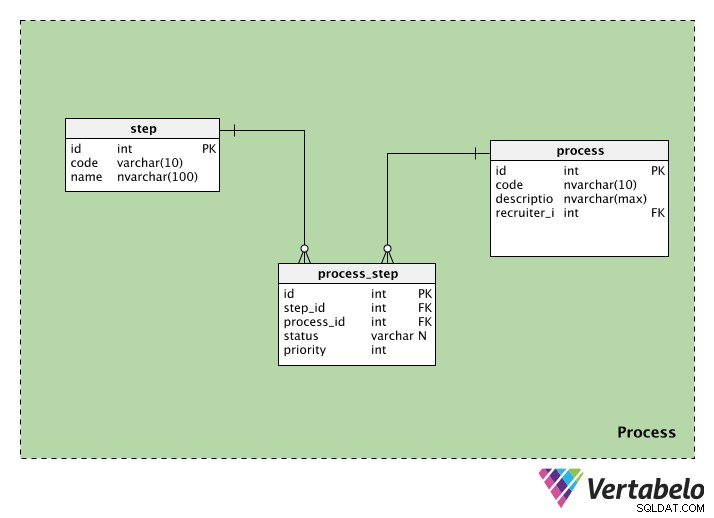
Process テーブルには、各採用プロセスに関する情報が格納されます。すべてのプロセスには、特別なID、コード、およびdescriptionがあります。 そのプロセスの。 recruiter_idもあります プロセスを開始する人の。
step 表には、その採用プロセス全体で実行される手順に関する情報が含まれています。すべてのステップにはidがあります およびcode 名前。名前の列には、「初期スクリーニング」、「筆記試験」、「HR面接」などの値を含めることができます。
1つのプロセスに複数のステップを含めることができ、1つのステップを多くのプロセスの一部にすることができるため、ルックアップテーブルが必要です。 process_step 表には、各ステップに関する情報が含まれています(step_id内) )およびそれが属するプロセス(process_id内) )。また、そのプロセスのそのステップのステータスを示すステータスもあります。ステップがまだ開始されていない場合、これはNULLになる可能性があります。最後に、priorityがあります 、ステップを実行する順序を示します。priorityが最も高いステップ 値が最初に実行されます。
ジョブ
次に、Jobs サブジェクトエリア。採用する仕事に関連するすべての情報が保存されます。このカテゴリのスキーマは次のようになります:
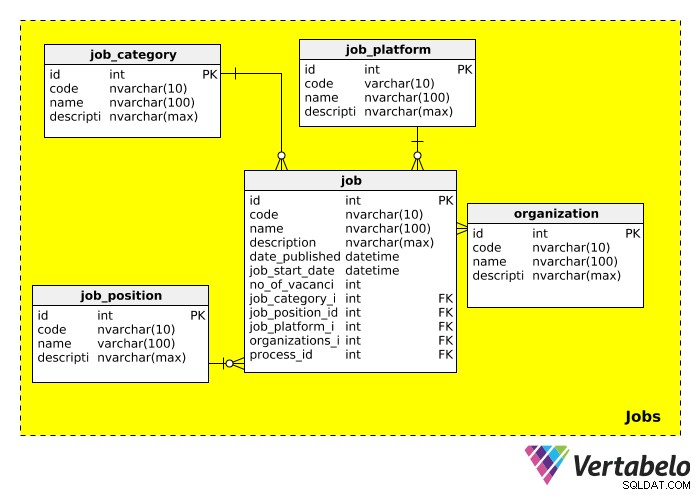
それぞれの表について詳しく説明しましょう。
job_category 表は、仕事の種類を大まかに説明しています。 「IT」、「管理」、「財務」、「教育」などの職種が期待できます。
job_position 表には実際の役職が含まれています。 1つのタイトルを複数のジョブ(「ITマネージャー」、「セールスマネージャー」など)にアドバタイズできるため、ジョブポジション用に別のテーブルを作成しました。この表には、「ITチームリーダー」、「副社長」、「マネージャー」などの値が表示されることが期待できます。
job_platform 表は、求人を宣伝するために使用される媒体を示しています。たとえば、Facebook、オンライン求人掲示板、または地元の新聞に求人情報を投稿できます。その求人情報へのリンクは、descriptionに追加できます 分野。
organization 表には、採用プロセスの一環としてこのデータベースを使用したことのあるすべての企業に関する情報が格納されています。明らかに、この表は、他の会社の採用が行われているときに重要です。
このサブジェクトエリアの最後のテーブル、job 、実際の職務記述書が含まれています。ほとんどの属性は自明です。このテーブルには多くの外部キーが含まれていることに注意してください。つまり、このテーブルを使用して、カテゴリ、ポジション、プラットフォーム、採用組織、およびその求人に関連する採用プロセスを調べることができます。
申請書、申請者、および書類
スキーマの3番目の部分は、求職者、そのアプリケーション、およびアプリケーションに付属するすべてのドキュメントに関する情報を格納するテーブルで構成されています。
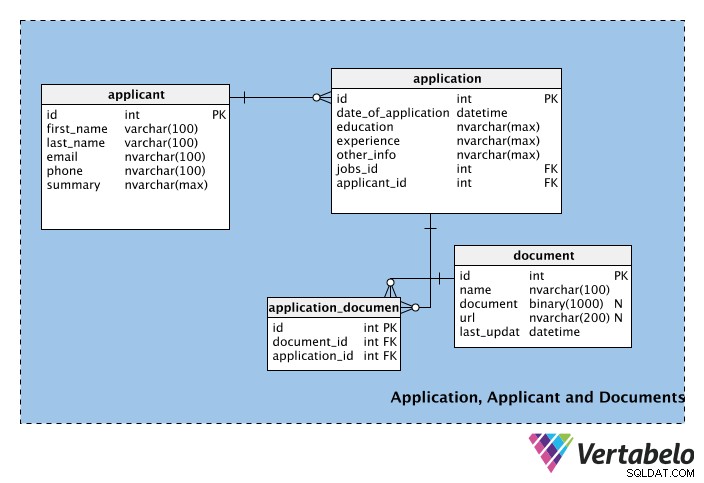
最初の表、applicant 、は、名、姓、電子メール、電話番号などの申請者の個人情報を格納します。概要フィールドは、申請者の短いプロファイル(段落など)を格納するために使用できます。
次の表には、各application 、その日付を含む。このテーブルには、experienceも含まれています およびeducation 列。これらの列は、applicant 表ですが、申請者は、提出するすべての申請書に特定の教育資格または職務経験を表示する場合と表示しない場合があります。したがって、これらの列はapplication テーブル。 other_info 列には、その他のアプリケーション関連の情報が格納されます。 application table、jobs_idおよびapplicant_idは、それぞれjobおよびapplicantテーブルからの外部キーです。
ジョブごとに複数のアプリケーションが存在する可能性がありますが、各アプリケーションは1つのジョブ専用であるため、jobs およびapplication テーブル。同様に、1人の申請者が複数の申請を提出できますが(つまり、異なる仕事のために)、各申請は1人の参加者からのみです。 applicants およびapplication これを処理するためのテーブル。
document 表は、申請者が申請書に添付できる補足文書を管理します。これらには、CV、履歴書、推薦状、カバーレターなどがあります。このテーブルには、ファイルをバイナリ形式で格納するdocumentという名前のバイナリ列があることに注意してください。ドキュメントへのリンクはurlに保存されている場合があります 分野; name列には、ドキュメントの名前とlast_updateが格納されます 申請者がアップロードした最新バージョンを示します。両方のdocument およびurl null許容です。どちらも必須ではなく、申請者はどちらかまたは両方の方法を使用して、申請に情報を追加することができます。
すべてのアプリケーションにドキュメントが添付されるわけではありません。 1つのドキュメントを複数のアプリケーションに添付でき、1つのアプリケーションに複数のサポートドキュメントを含めることができます。これは、application およびdocument テーブル。この関係を管理するには、ルックアップテーブルapplication_document 作成されました。
テストとインタビュー
次に、採用プロセスに関連するテストと面接に関する情報を格納するテーブルに移動します。
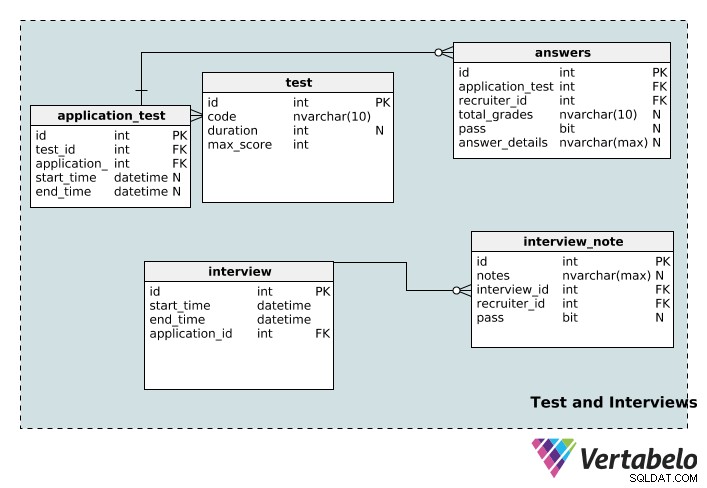
test テーブルには、一意のidを含むテストの詳細が格納されます 、code 名前、そのduration 分単位で、maximum そのテストで可能なスコア。
1つのアプリケーションを複数のアプリケーションに関連付けることができ、1つのテストを複数のアプリケーションに関連付けることができます。ここでも、この関係を実装するためのルックアップテーブルがあります:application_test 。 start_time およびend_time テストには特定の期間、開始時間、または終了時間がない可能性があるため、列はnull許容です。
テストは複数の採用担当者が採点でき、1人の採用担当者が複数のテストを採点できます。 answers tableは、これを可能にするテーブルです。 total_grades 列は候補者がテストでどれだけうまくいったかを記録し、合格列は単にその人が合格したか失敗したかを示します。個々のテストの詳細は、answer_detailsに記録されます。 桁。これらの3つの列はnull許容であることに注意してください。アプリケーションテストは、まだ採点していない採用担当者に割り当てられる場合があります。さらに、採用担当者は実際に受験する前にテストを割り当てることができます。
interview テーブルには基本情報(start_time)が格納されます 、end_time 、一意のid 、および関連するapplication_id )インタビューごとに。 1つの面接は1つのアプリケーションにのみ関連付けることができます。一方、1つのアプリケーションで複数の面接を行うことができます。したがって、アプリケーションと面接テーブルの間には1対多の関係が存在します。
1人のレビューアが複数のレビューアによって実施でき、1人のレビューアが複数のインタビューを受けることができます。これはもう1つの多対多の関係であるため、ルックアップテーブルinterview_note 。インタビューに関する情報を(interview_idに保存します) )、リクルーター(recruiter_id内 )、および面接に関する採用担当者のメモ。採用担当者は、応募者が面接に合格したかどうかを合格欄に記録することもできます。これは無効です。
採用担当者のアプリケーションの評価とステータス
採用モデルの最後の部分には、採用担当者、応募状況、応募評価に関する情報が保存されています。
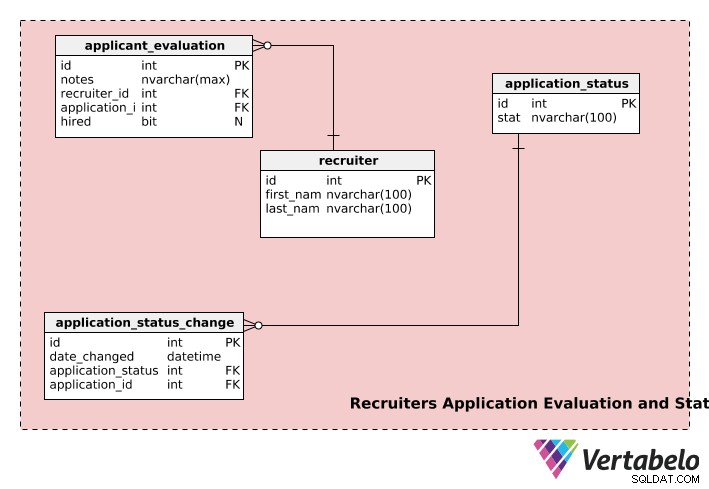
recruiters テーブルには、各採用担当者のfirst_nameが格納されます 、last_name 、および一意のid 番号。
application_evaluation テーブルには、アプリケーションの評価に関する情報が含まれています。 application_idに加えて およびrecruiter_id 、採用担当者のフィードバックが含まれています(notes )およびhiredでの最終的な採用決定(ある場合) 。 1つのアプリケーションを複数のリクルーターが評価でき、1つのリクルーターが複数のアプリケーションを評価できるため、両方のrecruiter およびapplication テーブルは、application_evaluation テーブル。
アプリケーションは、採用プロセス中に複数の段階を経ることができます。 「未提出」、「審査中」、「決定待ち」、「決定済み」など。ユーザーが申請を開始したが、採用担当者が審査するために申請していない場合、申請のステータスは「未提出」になります。申請書が提出されると、ステータスは「審査中」などに変更されます。 application_status テーブルは、そのような情報を格納するために使用されます。
application_status_change テーブルは、提出されたすべてのアプリケーションのステータス変更の記録を維持するために使用されます。 date_changed 列には、ステータス変更の日付が格納されます。この表は、さまざまなアプリケーションの各段階の処理時間を分析する場合に便利です。さらに、特定の列のステータスは、application_idを使用して取得できます。 application_status_change テーブル。
簡単な採用のユースケース
私たちのデータベースが採用プロセスにどのように役立つか見てみましょう。
ある会社から、プログラミングの経験を持つITマネージャーを雇うように割り当てられたとします。私たちのデータベースは、次の手順を実行することで、そのような人を雇うのに役立ちます。
- 最初のステップは、新しい採用プロセスを開始することです。そのために、データは
processおよびstepsテーブル。採用担当者は、必要な数のステップを追加できます。 - 上記のタスク中に、採用担当者は新しいジョブを作成し、
job、job_category、job_position、およびorganizationテーブル。最後に、求人広告はjob_platformテーブル。 - 次に、申請者はデータを
applicantテーブル。次に、applicationテーブル。 - 申請者は、申請書に書類を添付することもできます。このデータは
documentおよびapplication_documentテーブル。 - ユーザーが複数のジョブに応募する場合は、手順3と4を繰り返します。
- 申請書が提出されると、申請書のステータスは「送信済み」(または採用担当者が選択した別のステータス名)に設定されます。
- 採用担当者はアプリケーションを評価し、フィードバックを
application_evaluationテーブル。この段階では、採用された列には情報が含まれていません。 - 十分な数の応募を受け取ると、採用担当者は
process_stepテーブル。 - 次のステップが何らかのテストを実施することである場合、採用担当者はデータを
testテーブル。 - 手順9で作成したテストは、特定のアプリケーションに割り当てられます。各テストを各アプリケーションに割り当てる情報は、
application_testテーブル。各段階で、アプリケーションのステータスは変化し続けることに注意してください。これはapplication_status_changeテーブル。 - 申請者がテストを完了すると、各申請テストの成績が採用担当者によってマークされ、
answerテーブル。 - テストが行われると、
process_stepテーブルが実行されます。次のステップは面接だとしましょう。 - インタビューデータは
interviewテーブル。採用担当者はコメントを入力し、その人が面接に合格したかどうかを言います。これはinterview_noteテーブル。 process表にはさらにインタビューとテストのステップが含まれており、最後のステップに到達するまで実行されます。-
process_stepテーブルは通常、採用決定です。応募者がテストと面接に合格し、会社がそれらを採用することを決定した場合、データはapplication_evaluationテーブルとその人が雇われます。
採用システムのデータモデルについてどう思いますか?
この記事では、採用システム用の非常に単純なデータベーススキーマを作成する方法を説明しました。スキーマを4つのカテゴリに分けて、それぞれについて詳しく説明しました。最後に、ユースケースを実行して、スキーマが実際に従業員の採用に役立つことを示しました。
データベース設計の仕事は活況を呈しています。データベーススキルを追加したいですか? SQLの基本を学びたいと考えている初心者でも、SQLでのテーブルの作成に分岐したい経験豊富な専門家でも。インタラクティブコース| Vertabelo Academy "target =" _ blank ">データベース設計、LearnSQL.comの自習型コースをご覧ください。