どのデータモデルを使用すると、本を快適に検索して地元の図書館で借りることができますか?
図書館に行って本を借りたことがありますか。たぶん、それは今日のインスタントインターネット知識と電子書籍の世界では古風に思えます。しかし、嗅覚、嗅覚、そして本を読むのが好きなあなたのこのアナログの部分はまだあると確信しています。あるいは、インターネット上で何かを見つけることができなかったときに、図書館を使わざるを得なかったのかもしれません。うん、すべてがオンラインというわけではない。
では、データモデルは図書館の本やローンをどのように整理するのでしょうか。このモデルに飛び込んで、どのように機能するか見てみましょう!
データモデル
このデータモデルを作成したとき、私は公共図書館を念頭に置いていました。公共図書館ネットワークのすべての図書館が同じモデル/システムを使用しているという仮定があります。一元化されており、メンバーはネットワーク内のすべてのライブラリのコレクションを閲覧できます。また、会員はネットワーク内のどの図書館からでも本を借りることができます。
ライブラリデータモデルは、2つのサブジェクトエリアに分割された13のテーブルで構成されています。それらの領域は次のとおりです。
本と図書館メンバーとローン
各主題分野を個別に調べ、すべての詳細を分析します。
本と図書館
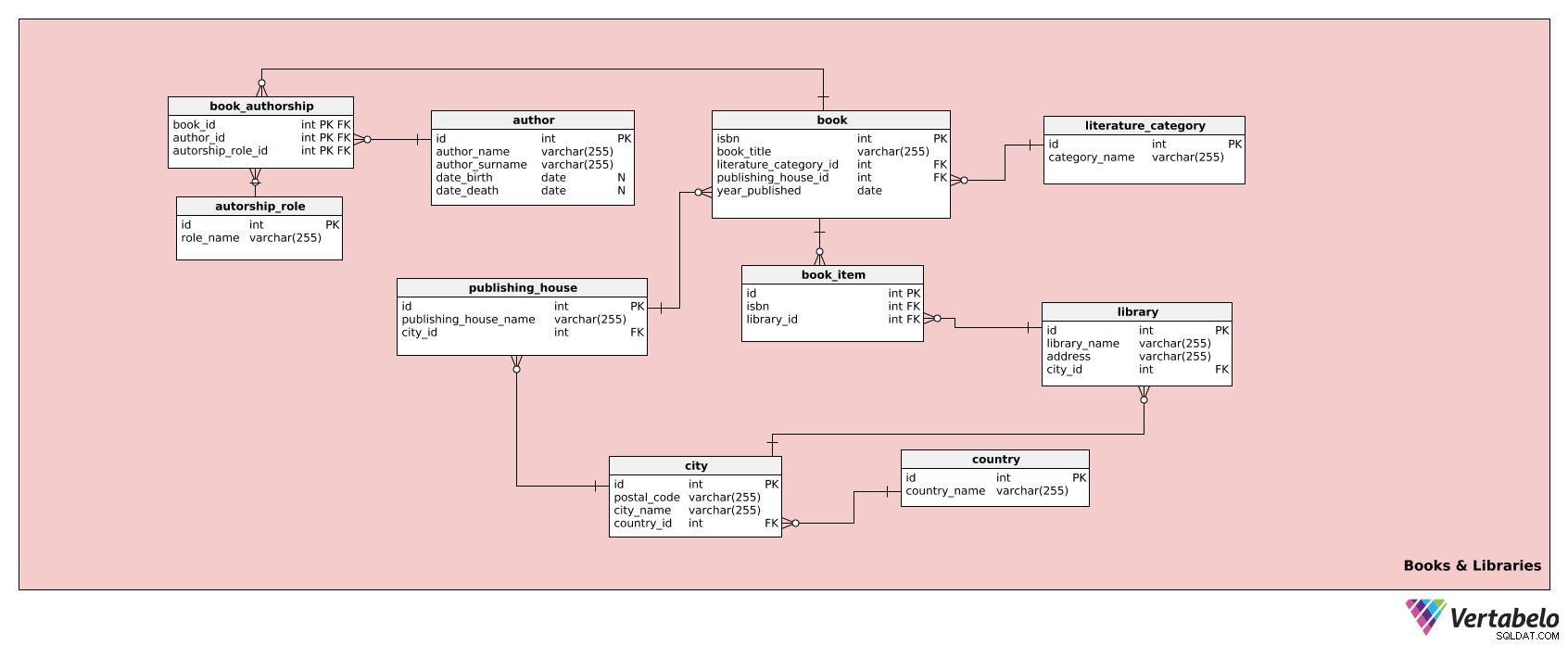
このサブジェクトエリアには、本や図書館に関する情報が保存されています。 10個のテーブルで構成されています:
作成者-
authorship_role -
literature_category 本-
book_authorship -
book_item -
Publishing_house ライブラリ都市国
最初のテーブルはauthor テーブル。それは、図書館がそのコレクションに持っている本のすべての著者(およびそれらの関連する詳細)をリストします。著者ごとに、次のものがあります。
-
id–その作成者の一意のID。 -
author_name–作成者の名。 -
author_surname–作成者の名前。 -
date_birth–著者の生年月日。 -
date_death–作者の死亡日。
authorship_role 表には、作成者が持つことができるすべての役割がリストされています。著者、共著者など。このテーブルには次の属性があります。
-
id–各役割の一意のID。 -
role_name–その役割の名前。例: 「共著者」。これはテーブルの代替キーです。
テーブルliterature_category すべての書籍カテゴリを一覧表示します。例:スリラー、フランス文学、ロシアの写実主義、哲学など。表には次の属性が含まれています。
-
id–そのカテゴリの一意のID。 -
category_name–カテゴリの名前。例: "神秘"。これはテーブルの代替キーです。
次に、本があります テーブル。このテーブルには、ライブラリのコレクションに含まれるすべてのタイトルに関連するすべての詳細が格納されます。これは、すべての本でアイテムとして使用される表ではないことに注意してください。そのために、別のテーブル、つまり book_itemを使用します。 テーブル。 本 テーブルは次の属性で構成されています:
-
isbn–各書籍タイトルの一意のID。出版業界では国際標準書籍番号(ISBN)です。 -
book_title–本のタイトル。 -
literature_category_id–literature_categoryを参照しますテーブル。 -
Publishing_house_id–Publishing_houseを参照しますテーブル。 -
year_published–本が出版された年。
モデルの次の表は、 book_authorshipです。 テーブル。 bookに接続される交差テーブルです 、作成者 、および authorship_role テーブル。次の属性が含まれています:
-
book_id–bookを参照しますテーブル。 -
author_id–作成者を参照しますテーブル。 -
authorship_role_id–authorship_roleを参照しますテーブル。
これらの3つの属性が一緒になって、テーブルの複合主キーを形成します。複合主キーは、3つの属性すべての任意の組み合わせが一意でなければならないことを意味します。各組み合わせは1回だけ発生します。
それでは、 book_itemを見てみましょう。 テーブル。これは、各物理的な本の情報をライブラリに保存することとして前述しました。次の情報が含まれます:
-
id–アイテムとしての各本の一意のID。 -
isbn–bookを参照しますテーブル。 -
library_id–ライブラリを参照しますテーブル。
Publishing_houseテーブルは、モデルの次のテーブルです。図書館がコレクションに持っているすべての本の出版社をリストします。表の属性は次のとおりです。 テーブルはモデルの次のテーブルです。図書館がコレクションに持っているすべての本の出版社をリストします。表の属性は次のとおりです。
-
id–各出版社の一意のID。 -
Publishing_house_name–出版社の名前(ペンギンブックス、マグロウヒル、サイモン&シュスターなど)。 -
city_id–cityを参照しますテーブル。この接続により、出版社の都市と国の両方を特定することもできます。Publishing_house_name–city_idペアはこのテーブルの代替キーです。
では、ライブラリに移りましょう。 テーブル。このテーブルは、 book_itemで参照されています テーブル。本の各コピーが保持されるライブラリを定義します。これが必要なのは、同じ本のタイトルがネットワーク内の複数の図書館で見つかる可能性があるためです(たとえば、各図書館にはおそらくロードオブザリングのコピーが少なくとも1つあります )。したがって、どの本がどの図書館にあるかを知る必要があります。これを実現するには、次の属性が必要です。
-
id–ライブラリの一意のID。 -
library_name–そのライブラリの名前。 アドレス–そのライブラリのアドレス。-
city_id–cityを参照しますテーブル。library_name-city_idペアはこのテーブルの代替キーです。
このモデルの次の表は、 city テーブル。これは、出版社、図書館、図書館員に関する情報に使用する都市の簡単なリストです。属性は次のとおりです。
-
id–都市の一意のID。 -
postal_code–その都市の郵便番号。 -
city_name–その都市の名前。 -
country_id–国を参照しますテーブル。
その後、このサブジェクト領域に残っているテーブルは countryの1つだけです。 テーブル。これは、図書館や書籍の出版社が所在するすべての国のリストです。次の属性で構成されています:
-
id–各国の一意のID。 -
country_name–国の名前。これはテーブルの代替キーです。
次に、2番目の主題分野を調べてみましょう。
会員とローン
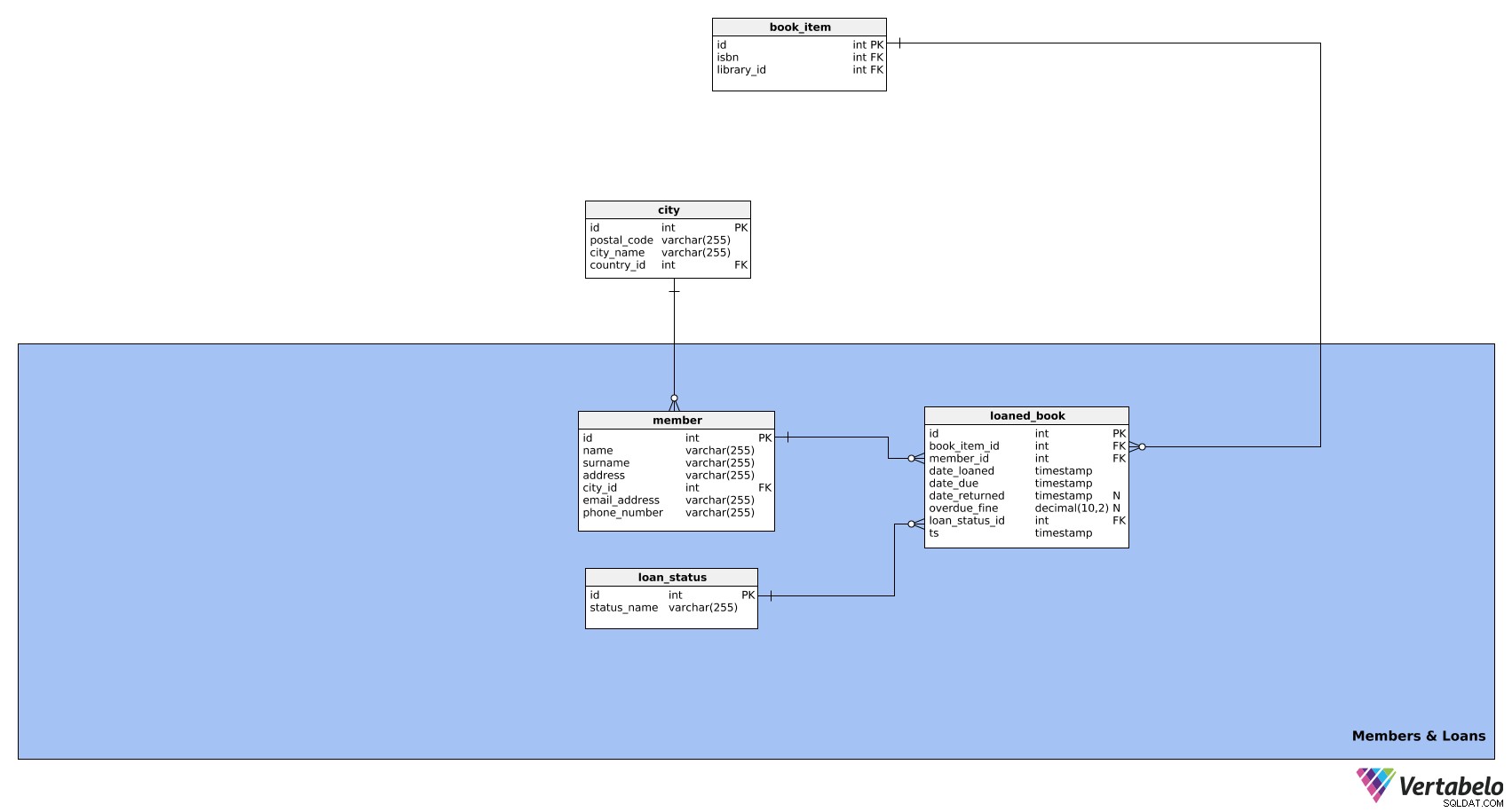
この主題分野の目的は、図書館員と彼らが借りている本に関する情報を管理することです。 3つのテーブルで構成されています:
メンバー-
loaned_book -
loan_status
それでは、テーブルについて話しましょう。
この領域の最初のテーブルはメンバーです テーブル。これには、図書館のメンバーに関するすべての関連情報が含まれています。その属性は次のとおりです。
-
id–各メンバーの一意のID。 名前 –メンバーの名。名前–メンバーの名前。アドレス–メンバーの住所。-
city_id–cityを参照しますテーブル。 -
email_address–メンバーのメールアドレス。 -
phone_number–メンバーの電話番号。
次の表はloaned_book テーブル。これまでに貸し出されたすべての本に関する情報が保存されます。このようにして、図書館の持ち物と貸出された本のステータスを追跡できます。このテーブルは、次の属性で構成されています。
-
id–貸し出されたすべての本の一意のID。 -
book_item_id–book_itemを参照しますテーブル。 -
member_id–メンバーを参照しますテーブル。 -
date_loaned–この本が貸与された日付。 -
date_due–この本を返却する必要がある日付。 -
date_returned–本が実際に図書館に返却された日付。書籍が返却されるまで日付がわからないため、これはNULLになる可能性があります。 -
overdue_fine–メンバーが支払う延滞料(ある場合)。通常、date_returnedの差に基づいて計算されます。 およびdate_due。時間通りに返却された本には罰金がないため、これはNULLになる可能性があります。 -
loan_status_id–loan_statusを参照しますテーブル。 -
ts–そのローンステータスが入力されたときのタイムスタンプ。
loan_status テーブルはデータモデルの最後のテーブルです。これは、考えられるすべてのローンステータスのリストにすぎません。アクティブ、延滞、返品など。このテーブルは次の属性で構成されます。
-
id–すべてのローンステータスの一意のID。 -
status_name–ローンのステータスを説明する名前。これはテーブルの代替キーです。
以上です。データモデルの詳細をすべて確認しました。
図書館データモデルについてどう思いますか?
このモデルでは一般的な原則について説明したので、すべてのライブラリで(いくつかの調整を加えて)行う必要があります。私たちが見逃したライブラリの詳細を知っていますか?それとも、モデルが便利で簡単に適用できると思いましたか?コメントセクションであなたの意見を持ってください。