シェアリングエコノミーの全体像を見逃している可能性はほとんどありません。好むと好まざるとにかかわらず。 Airbnb、Uber、Lyftなどの企業に人気があり、未使用のものを借りることで現金を稼ぐことができます。そのようなアプリケーションの背後にあるデータモデルを見てみましょう。
予備の部屋がありますか? Airbnbにサインアップして、それを借りて余分なお金を稼ぎましょう。車と自由な時間を手に入れましたか? Uberドライバーになりましょう。そして、それはそうです–これらの会社の背後にある考え方、そしてそれらに似た多くの会社はほとんど同じです。それはすべて、(ほとんど)見知らぬ人とリソースを共有することであり、両方の当事者に特典があります。所有者は未使用の資産に対してお金を受け取りますが、顧客は通常かなりの金額を受け取ります。これはお互いに有利な状況であるはずです。
もちろん、所有者と顧客を結び付け、重要な詳細を追跡するためのプラットフォームが必要です。本日は、タスクを管理できるデータモデルを紹介します。椅子に腰を下ろして、シェアリングエコノミーデータモデルを楽しんでください。
データモデルには何が必要ですか?
私たちが使用していないときに不動産を借りるという考えは非常に賢明なようです。まず、プロパティはその意図された目的のために使用されます。第二に、賃貸はある種の追加収入を生み出すでしょう。それは現金かもしれませんが、交換かもしれません(たとえば、ニューヨークの誰かがパリの誰かとアパートを1週間交換する)。
キャッシュレスモデルは本当にクールで、通常は相互理解、善意、誠実さに依存しています。ただし、この記事では、支払いが必要なシェアリングエコノミーモデルに焦点を当てます。キャッシュレスモデルほどロマンチックではありませんが、支払いモデルはかなり効果的です。
多数の不動産所有者が多数の関心のある顧客に到達するための、またはその逆の非常に簡単な方法が必要です。これは、データモデルの最初の要件です。ユーザーアカウントと、所有者と顧客の少なくとも2つの異なる役割があります。
次に必要なのは、アプリが利用可能なすべてのプロパティを一覧表示することです。 Airbnbの場合、これはアパートになります。 Uberの場合、これは車になります。この記事では、アパートの賃貸(Airbnbのようなデータモデル)に焦点を当てますが、他の目的の共有経済サービスに簡単に変換できるように、モデルを十分に一般的にしておきます。
不動産所有者ごとに、彼らが運営する場所を定義する必要があります。アパートの場合、これはかなり明白です(アパートが配置されている都市)。輸送サービスの場合、これは車やその所有者の現在の場所によって異なります。
プロパティまたはリソースごとに、使用期間とリクエスト/予約を追跡する必要があります。これにより、新しいリクエストが出されたときに利用可能な物件を見つけ、占有率と価格を計算することができます。他のプログラムを使用して、このデータを分析し、他の統計を生成することもできます。
データモデル
データモデルは、次の5つのサブジェクト領域で構成されています。
国と都市ユーザーと役割サービスとドキュメントリクエスト提供されるサービス
各サブジェクトエリアは、リストされているのと同じ順序で表示されます。
セクション1:国と都市
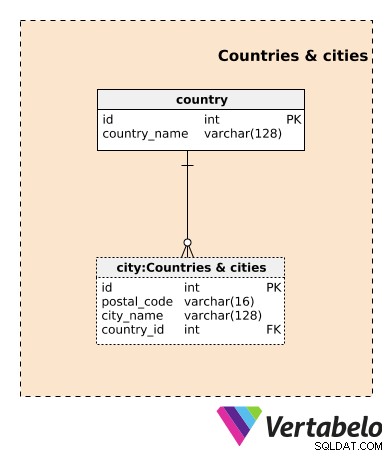
国と都市から始めましょう サブジェクトエリア。このデータモデルに固有ではありませんが、これらのテーブルは非常に重要です。不動産関連のサービスは通常、地理的に指向されています。私たちのモデルは、ある種の住居を借りることと密接に関連しているため、ここでは物理的な場所が重要です。もちろん、その場所は通常変更されません。物件の場所を変更する可能性のある非常に特殊なケースがいくつかありますが、私はその新しい場所にある住居を完全に新しい物件として扱います。
Uberのような車やドライバーのアプリの場合、車とドライバーの現在の場所も非常に重要です。 Airbnbスタイルのアパートの賃貸とは異なり、これらの物件の場所は頻繁に変更される可能性があります。
国 表には、当社が事業を行っている国の一意の名前のリストが含まれています。 都市 表には、私たちが事業を行っているすべての都市のリストが含まれています。このテーブルのUNIQUEの組み合わせは、 postal_codeの組み合わせです。 、 city_name 、および country_id 属性。
これらのテーブルには両方とも多くの追加属性が含まれている可能性がありますが、このモデルに値を追加しないため、意図的に省略しました。
セクション2:ユーザーと役割
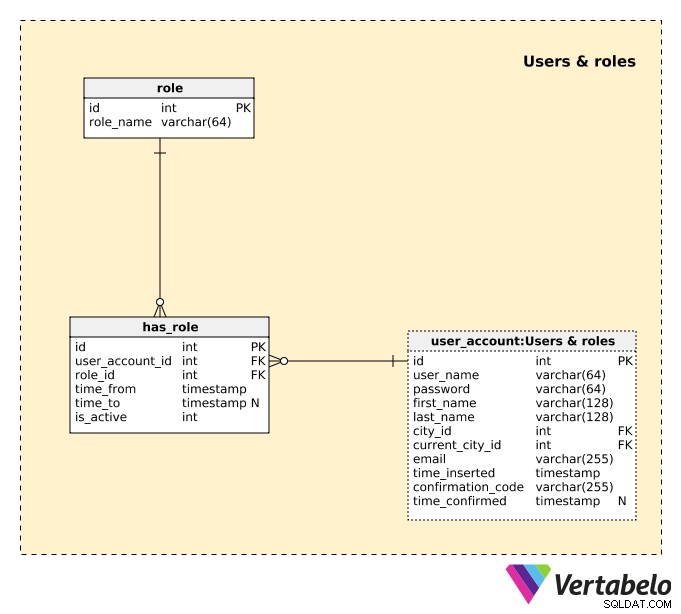
次に行う必要があるのは、アプリケーションでのユーザーとその動作またはロールを定義することです。これを行うには、ユーザーと役割の3つのテーブルを使用します サブジェクトエリア。
すべてのユーザーのリストはuser_accountにあります テーブル。ユーザーごとに、次の詳細を保存します:
-
user_name–ユーザーがアプリケーションにアクセスするために選択した一意の名前。 パスワード–ユーザーが選択したパスワードのハッシュ値。-
first_nameおよびlast_name–ユーザーの名前と名前。 -
city_id–cityへの参照ユーザーが通常いる場所。 -
current_city_id–cityへの参照ユーザーが現在いる場所。 メール–ユーザーのメールアドレス。-
time_inserted–このレコードがテーブルに挿入されたときのタイムスタンプ。 confirmation_code–ユーザーのメールアドレスを確認するために登録プロセス中に生成されるコード。-
time_confirmed–電子メールアドレスが確認されたときのタイムスタンプ。確認が完了するまで、この属性にはNULL値が含まれます。
ユーザーは、役割に応じてアプリケーションでさまざまな権限を持ちます。 1人のユーザーが同時に複数のアクティブな役割を持つ可能性もあります。彼らは、ある物件の所有者であり、別の物件の顧客である可能性があります。その場合、ユーザーは同じログイン詳細を使用し、役割を切り替えるオプションがあります。各役割には、アプリ内に独自の画面があります。
可能なすべての役割のリストは、 roleに保存されます 辞書。各ロールは、その role_nameによって一意に定義されます 。わかりやすくするために、「プロパティの所有者」と「顧客」の2つの役割しか期待できません。
ユーザーは、異なる期間中に同じ役割を複数回割り当てることができます。そのようなケースの1つは、ユーザーが未使用のアパートを借りていて、必要だったためにアパートを借りないことにした場合です。しかし、数か月後、同じユーザーがアパートを再び借りることに決めました。この場合、彼らの役割を無効にしてから、再度有効にします。
これまでにユーザーに割り当てられたすべての役割のリストは、 has_roleに保存されます。 テーブル。この表のレコードごとに、以下を保存します:
-
user_account_id–関連するユーザーのID。 -
role_id–関連する役割のID。 -
time_from–この役割がシステムに挿入されたときのタイムスタンプ。 -
time_to–この役割が非アクティブ化されたときのタイムスタンプ。役割がまだアクティブである限り、これにはNULL値が含まれます。 -
is_active–何らかの理由で役割が非アクティブ化されると、Falseに設定されます。
このテーブルに新しいレコードを挿入するときは、重複するレコードをチェックする必要があります。これにより、同じ期間中に同じ役割を2回有効にすることを回避できます。
セクション3:サービスとドキュメント
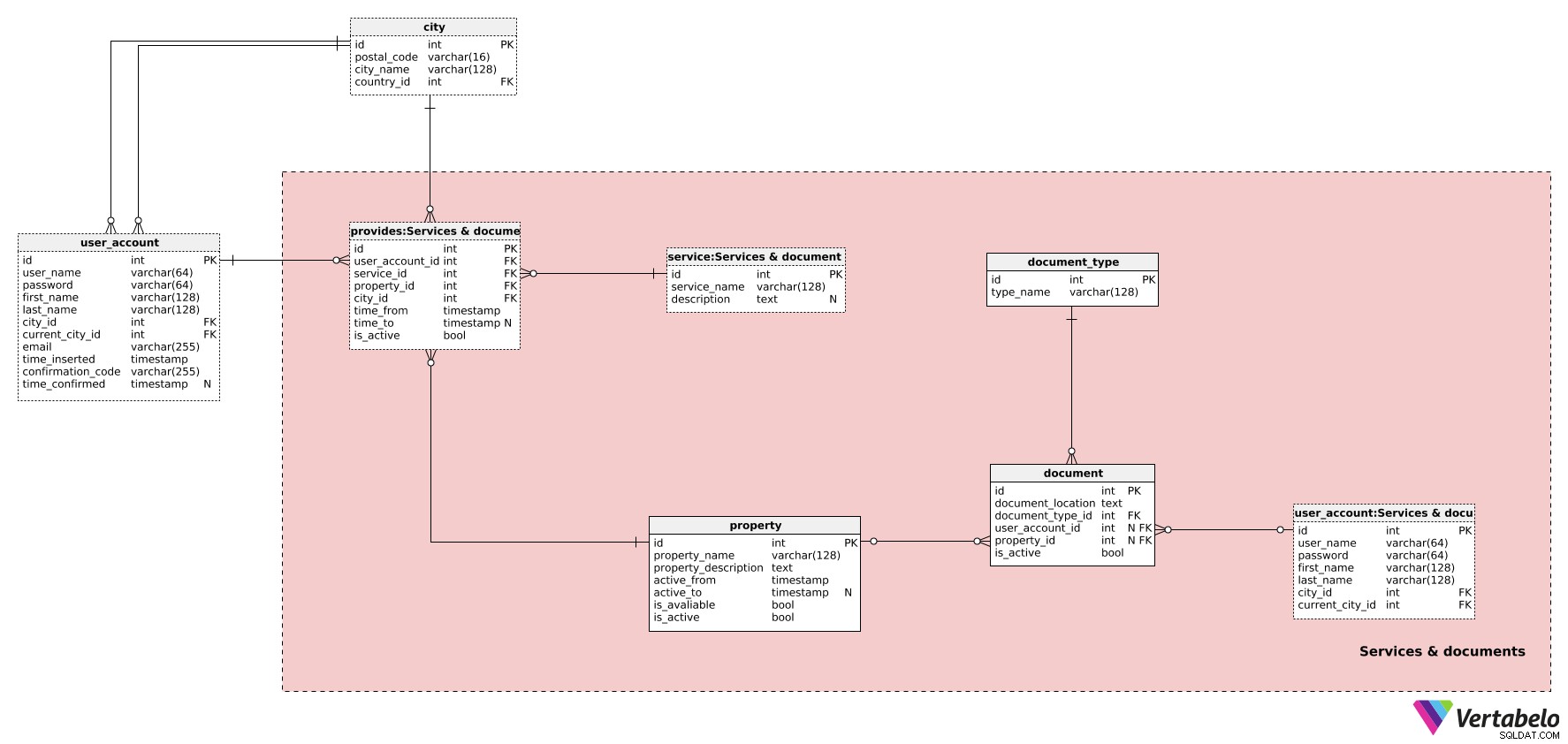
次に定義する必要があるのは、ユーザーが提供するサービスです。また、関連するドキュメントを追跡する必要があります。そのためには、サービスとドキュメントのテーブルが必要です サブジェクトエリア。
プロパティから始めましょう テーブル。プロパティは、住居、車、自転車など、私たちのサービスの対象が何であれ、ユーザーが自分のプロパティを管理することを期待できます。プロパティごとに、以下を定義する必要があります:
-
property_name–ユーザーが選択したそのプロパティの画面名。この名前は、アプリで潜在的な顧客にプロパティを表示するときに使用されます。簡潔で説明的であり、そのプロパティを他のプロパティと区別する必要があります。 -
property_description–非構造化形式の追加のテキスト説明。ここでは、アパートの大きさから、顧客が到着したときにウェルカムドリンクを受け取るかどうかまで、基本的にすべての詳細を期待できます。輸送サービスでのウェルカムドリンクは、発生する可能性がはるかに低くなります。 -
active_fromおよびactive_to–そのプロパティがシステムでアクティブだった期間。active_toプロパティが非アクティブ化されるまで、属性にはNULL値が含まれます。 -
is_available–このプロパティが特定の時間に利用可能かどうかを示すフラグ。 -
is_active–そのプロパティがシステムでまだアクティブであるかどうかを示すフラグ。この属性の値は、同時にactive_toにFalseに設定されます。 設定されています。
次に、サービスに移動します 辞書。ここで、「長期家賃」、「短期家賃」、「輸送」など、考えられるすべてのサービスタイプを定義します。これには、サービスタイプの一意の名前と追加の説明 、必要に応じて。
関連するプロパティ、サービス、ユーザーを提供に保持します テーブル。プロパティが利用可能だった期間を保存します。交通機関の場合、これは車と運転手が実際に私たちの会社で働いていた時期を教えてくれます。アパートの賃貸の場合、物件がいつ利用可能になったのかを教えてくれます。ここの各レコードには、次のものがあります。
-
user_account_id–そのサービスを提供するユーザーのID。 -
service_id–サービスのID提供されるタイプ。 -
property_id–プロパティを参照します使用済み。 -
time_fromおよびtime_to–このプロパティがこのサービスを提供するために使用されたとき。time_toこのレコードが非アクティブ化されるまで、属性にはNULL値が含まれます。 -
is_active–このプロパティが使用されなくなるか、このユーザーがこのサービスの提供を停止すると、Falseに設定されます。これは、time_toと同時に設定されます 設定されています。
このサブジェクト領域の残りの2つのテーブルは、ドキュメントに関連しています。 (user_accountテーブルはオリジナルのコピーであり、関係の重複を避けるためにここで使用されます。)当社は多くの不動産所有者と協力し、すべてを直接チェックする機会はほとんどありません。サービス品質を確保する1つの方法は、すべてを十分に文書化することです。
ドキュメントに関連する最初のテーブルは、 document_typeです。 テーブル。この単純な辞書には、UNIQUE type_nameのリストが含まれています 値。ここでは、「物件の写真」や「所有者ID」などの値を期待できます。
すべてのドキュメントのリストはdocumentに保存されます テーブル。これらのドキュメントは、ユーザーアカウント、プロパティ、またはその両方に関連している可能性があります。ドキュメントごとに、以下を保存します:
-
document_location–そのドキュメントへのフルパス。 -
document_type_id–document_typeへの参照辞書。 -
user_account_id–user_accountへの参照テーブル。この属性は、ドキュメントがユーザーに関連している場合にのみ値を保持しますまたは ドキュメントがプロパティに関連しているが、ユーザーもそのプロパティを所有している場合。 -
property_id–関連するプロパティへの参照 。 -
is_active–このドキュメントがまだアクティブ(有効)であるかどうかを示します。
セクション4:リクエスト
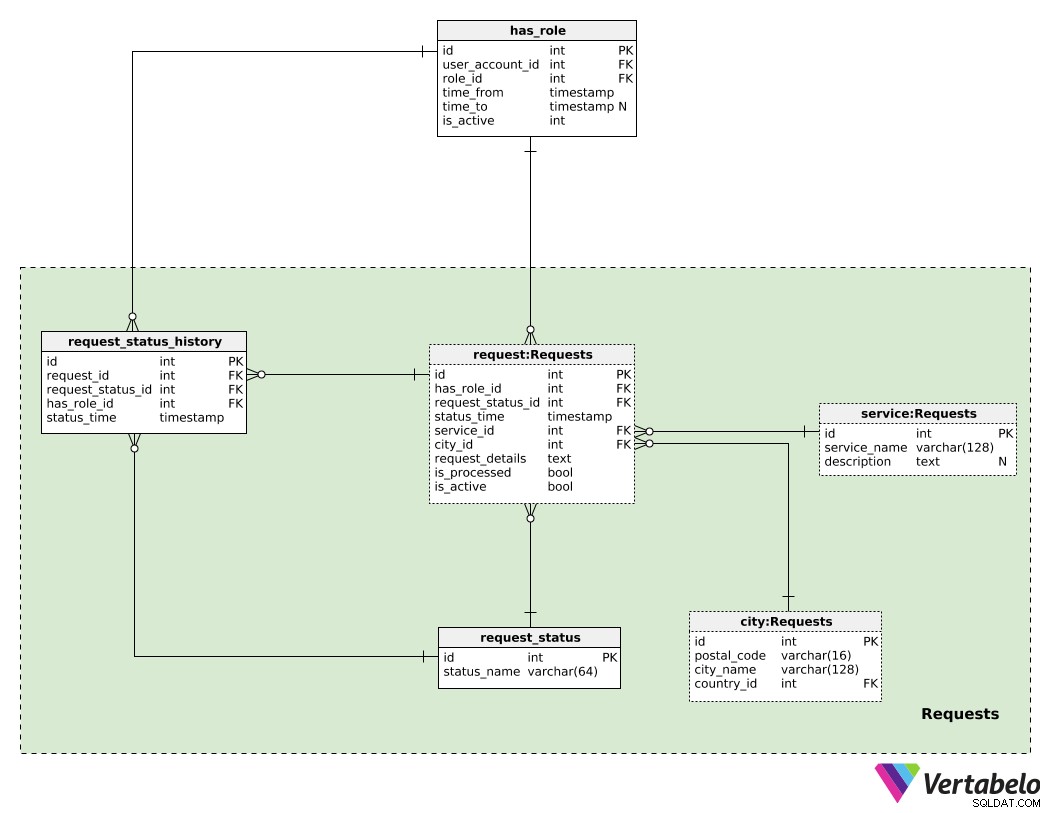
サービスを提供する前に、いくつかのユーザーリクエストを取得する必要があります。アパートの賃貸では、顧客はリストを検索して希望の住居を見つけた後、希望の物件をリクエストします。交通機関の場合、顧客はモバイルアプリケーションを介してリクエストを送信します(たとえば、空港にいて、20分で乗車する必要があります)。次のセクションでは、リクエストの処理方法について説明します。とりあえず、それらをどのように管理するか見てみましょう。
このサブジェクトエリアの中央のテーブルは、 request テーブル。リクエストごとに、以下を保存します:
-
has_role_id–ユーザーへの参照(およびhas_roleを介したユーザーの現在の役割表)そのリクエストを行ったのは誰か。 -
request_status_id–そのリクエストの現在のステータスへの参照。 -
status_time–そのステータスが割り当てられたときのタイムスタンプ。 -
service_id–サービスのIDそのリクエストには必要です。 -
city_id–cityへの参照このサービスが必要な場所。 -
request_details–構造化されていないテキスト形式のすべての追加リクエストの詳細。 -
is_processed–このリクエストが処理されたかどうか(つまり、サービスプロバイダーに割り当てられたかどうか)を示すフラグ。 -
is_active–このフラグは、顧客がリクエストをキャンセルした場合、またはリクエストが何らかの理由でアプリによってキャンセルされた場合にのみFalseに設定されます。
考えられるすべてのステータスのリストは、 request_statusに保存されます。 status_nameの辞書 UNIQUE(そして唯一の)値として。 「リクエストが送信されました」、「プロパティが予約されています」、「ドライバーに割り当てられています」、「ドライブが進行中です」、「完了しました」などの値が期待できます。
request_status_history テーブルには、リクエストに関連するすべてのステータスの履歴が保存されます。このテーブルのレコードごとに、関連するリクエストのID( request_id )を保存します )、ステータスID( request_status_id )、ユーザーアカウントIDと、そのステータスを設定したときにユーザーが持っていた役割( has_role_id )。また、各ステータスがいつ割り当てられたかを記録します( status_time 。
セクション5:提供されるサービス
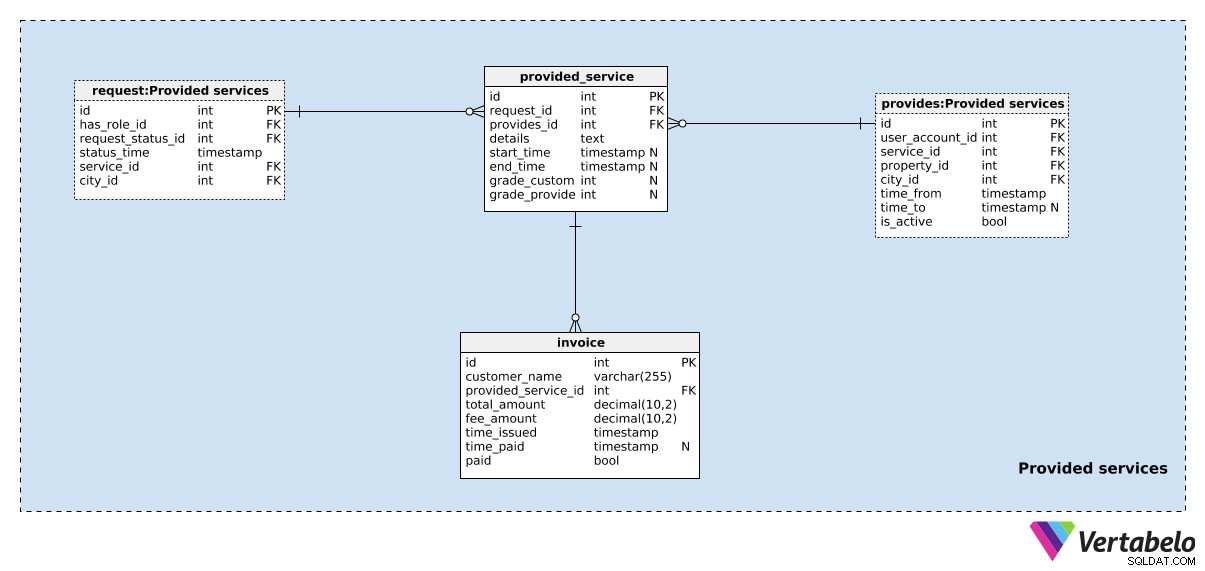
リクエストが送信されたら、処理する必要があります。リクエストは、(リクエストされたサービスタイプ、場所などに基づいて)適切なサービスプロバイダーに自動的に割り当てられるか、サービスプロバイダーによって手動で受け入れられます。これを処理するには、あと2つのテーブルが必要です。
1つ目はProvided_service です テーブル。各レコードには、次のものが含まれます。
-
request_id–関連するリクエストのID。 -
provides_id–提供への参照このアクションに含まれるサービスプロバイダーとプロパティを示す表。 詳細 –構造化されたテキスト形式のすべての追加の詳細。この構造には、リクエストの詳細を説明するタグと値を含めることができます。乗車の場合、これは始点と終点、走行距離などを意味します。-
start_timeおよびend_time–このサービスが提供された期間。これらの値は両方とも、サービスが開始および終了した直後に設定されます。 -
grade_customerおよびgrade_provider–顧客とそのサービスのサービスプロバイダーによって与えられた成績。
モデルの最後のテーブルは請求書です テーブル。顧客に請求します( customer_name )提供されるサービス( Provided_service_id )。請求書ごとに、 total_amountを知る必要があります 、支払った料金( fee_amount )、請求書が発行されたとき( time_issued )、および支払われた時期( time_paid )支払済みフィールドは、請求書が支払われたかどうかを示すフラグとして機能します。
シェアリングエコノミーデータモデルについてどう思いますか?
今日は、AirbnbやUberなどの企業で使用できるデータモデルについて説明しました。このようなビジネスモデルのバックボーンは、顧客とサービスプロバイダーです。このモデルに追加できる詳細がいくつかあります。それでも、モデルがすぐに大きくなりすぎるので、そうしないことにしました。私が何かを追加すべきだったと思いますか?もしそうなら、下のコメントで教えてください。