SQL Server 2012での多くの実行プランの改善の1つは、並列実行プランのスレッド予約と使用法の情報の追加でした。この投稿では、これらの数値が何を意味するのかを正確に調べ、並列実行を理解するための追加の洞察を提供します。
AdventureWorksデータベースの拡大バージョンに対して実行される次のクエリについて考えてみます。
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; クエリオプティマイザは並列実行プランを選択します:
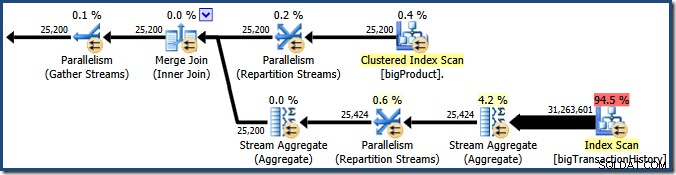
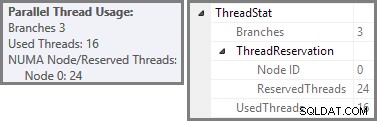
プランエクスプローラーは、ルートノードのツールチップに並列スレッドの使用法の詳細を表示します。 SSMSで同じ情報を表示するには、プランのルートノードをクリックし、[プロパティ]ウィンドウを開いて、 ThreadStatを展開します。 ノード。 SQL Serverで使用できる8つの論理プロセッサを備えたマシンを使用して、このクエリの一般的な実行からのスレッド使用情報を以下に示します。左側にプランエクスプローラー、右側にSSMSビューがあります。
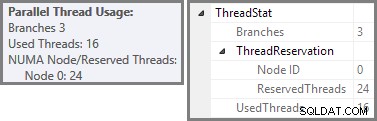
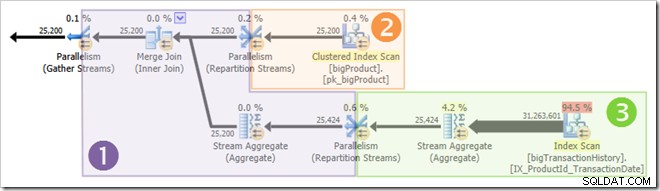
スクリーンショットは、実行エンジンがこのクエリ用に24スレッドを予約し、そのうち16スレッドを使用して終了したことを示しています。また、クエリプランに3つのブランチがあることも示しています。 、ブランチが何であるかを正確に示しているわけではありませんが。並列クエリの実行に関する私のSimpleTalkの記事を読んだ場合、ブランチは交換演算子によって制限された並列クエリプランのセクションであることがわかります。下の図は境界線を描き、枝に番号を付けています(クリックして拡大):

ブランチ2(オレンジ)
まず、ブランチ2をもう少し詳しく見てみましょう。
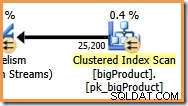
並列度(DOP)が8の場合、クエリプランのこのブランチを実行しているスレッドは8つあります。 これが実行計画全体であることを理解することが重要です。 これらの8つのスレッドに関する限り、より広い計画についての知識はありません。
シリアル実行プランでは、単一のスレッドがデータソースからデータを読み取り、複数のプランオペレーターを介して行を処理し、結果を宛先(SSMSクエリ結果ウィンドウやデータベーステーブルなど)に返します。
ブランチ 並列実行プランの場合、状況は非常に似ています。各スレッドはソースからデータを読み取り、いくつかのプランオペレーターを介して行を処理し、結果を宛先に返します。違いは、宛先が交換(並列処理)演算子であり、データソースも交換である可能性があることです。
オレンジ色のブランチでは、データソースはクラスター化インデックススキャンであり、宛先は再パーティションストリーム交換の右側です。取引所の右側は、プロデューサー側と呼ばれます。 、データ交換にデータを追加するブランチに接続するためです。
オレンジ色のブランチの8つのスレッドが連携して、テーブルをスキャンし、交換に行を追加します。交換は、行をページサイズのパケットにアセンブルします。パケットがいっぱいになると、交換機を越えて反対側にプッシュされます。交換で埋めることができる別の空のパケットがある場合、すべてのデータソース行が処理されるまで(または交換で空のパケットがなくなるまで)、プロセスが続行されます。
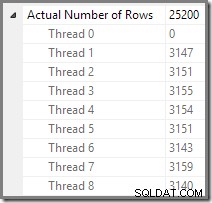
プランエクスプローラーのプランツリービューを使用して、各スレッドで処理された行数を確認できます。
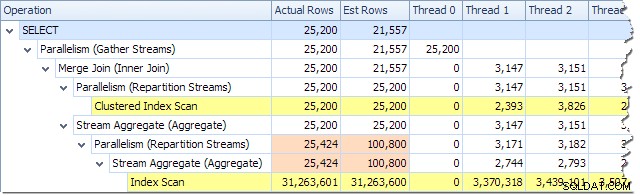
Plan Explorerを使用すると、すべてのスレッド間で行がどのように分散されているかを簡単に確認できます。 計画内の物理的な操作。 SSMSでは、単一のプランオペレーターの行分布を表示するように制限されています。これを行うには、オペレーターアイコンをクリックし、「プロパティー」ウィンドウを開いてから、「実際の行数」ノードを展開します。次の図は、オレンジ色のブランチと紫色のブランチの境界にあるRepartitionStreamsノードのSSMS情報を示しています。
ブランチ3(緑)
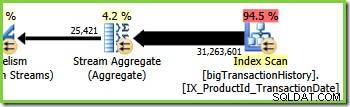
ブランチ3はブランチ2に似ていますが、追加のStreamAggregate演算子が含まれています。緑の枝にも8つのスレッドがあり、これまでに合計16のスレッドが見られます。 8つのグリーンブランチスレッドは、非クラスター化インデックススキャンからデータを読み取り、ある種の集計を実行し、その結果を別のRepartitionStreamsエクスチェンジのプロデューサー側に渡します。
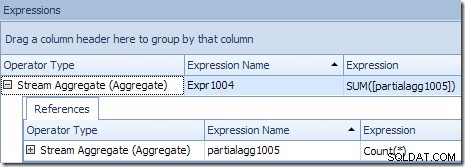
StreamAggregateのPlanExplorerツールチップは、製品IDでグループ化され、partialagg1005というラベルの付いた式を計算していることを示しています。 :
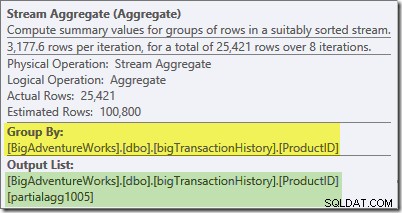
[式]タブには、各グループの行をカウントした結果の式が表示されます。

StreamAggregateはpartialを計算しています (「ローカル」とも呼ばれます)集計。部分(またはローカル)修飾子は、各スレッドが表示される行の集計を計算することを意味します。インデックススキャンからの行は、デマンドベースのスキームを使用してスレッド間で分散されます。事前に行の固定分散はありません。スレッドは、要求に応じてスキャンから一連の行を受け取ります。タイミングの問題やその他の要因に依存するため、どの行がどのスレッドに到達するかは基本的にランダムです。
各スレッドには異なる行が表示されます スキャンからですが、同じ製品IDの行 複数のスレッドで表示される場合があります。特定の製品IDグループの小計が複数のスレッドに表示される可能性があるため、集計は「部分的」です。各スレッドは、たまたま受け取った行のみに基づいて結果を計算するため、「ローカル」です。たとえば、テーブルに製品ID#1の行が1,000行あるとします。 1つのスレッドでこれらの行のうち432が表示され、別のスレッドで568が表示される場合があります。両方のスレッドに部分的 製品ID#1の行数(一方のスレッドで432、もう一方のスレッドで568)。
部分的な集約は、他の方法で可能になるよりも早く行数を減らすため、パフォーマンスの最適化です。緑のブランチでは、早期の集約により、パケットにアセンブルされて再パーティションストリーム交換を介してプッシュされる行が少なくなります。
ブランチ1(紫)

紫色の枝にはさらに8つのスレッドがあり、これまでに24になります。このブランチの各スレッドは、2つのRepartition Streamsエクスチェンジから行を読み取り、GatherStreamsエクスチェンジに行を書き込みます。このブランチは複雑でなじみがないように見えるかもしれませんが、他のクエリプランと同様に、データソースから行を読み取り、結果を宛先に送信するだけです。
計画の右側は、オレンジ色と緑色の枝に見られる2つの再パーティションストリーム交換の反対側から読み取られているデータを示しています。交換のこの(左側)側は、消費者として知られています。 ここに接続されているスレッドは行を読み取っている(消費している)ためです。 8つの紫色の分岐スレッドは消費者です 2つのRepartitionStreamsエクスチェンジでのデータの比較。
紫色のブランチの左側は、プロデューサーに書き込まれている行を示しています。 GatherStreams交換の側。 同じ8つのスレッド (Repartition Streamsエクスチェンジのコンシューマー)はプロデューサーを実行しています ここでの役割。
紫色のブランチの各スレッドは、単一のスレッドがシリアル実行プランのすべての操作を実行するのと同じように、ブランチのすべてのオペレーターを実行します。主な違いは、8つのスレッドが同時に実行され、それぞれが異なるインスタンスを使用して、任意の時点で異なる行で動作することです。 クエリプラン演算子の。
このブランチのStreamAggregateはグローバルです。 集計。緑のブランチで計算された部分(ローカル)集計を組み合わせて(一方のスレッドで432カウント、もう一方のスレッドで568カウントの例を思い出してください)、各製品IDの合計を生成します。プランエクスプローラーのツールチップには、Expr1004というラベルの付いたグローバル結果式が表示されます。
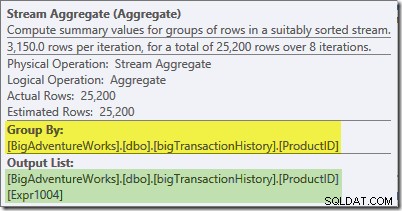
[式]タブに示されているように、製品IDごとの正しいグローバル結果は、部分的な集計を合計することによって計算されます。
(架空の)例を続けると、製品ID#1の1,000行の正しい結果は、432と568の2つの小計を合計することによって得られます。
8つの紫色のブランチスレッドはそれぞれ、2つのGather Streamsエクスチェンジのコンシューマー側からデータを読み取り、グローバルアグリゲートを計算し、製品IDでマージ結合を実行し、紫色のブランチの左端にあるGatherStreamsエクスチェンジに行を追加します。コアプロセスは、通常のシリアルプランとそれほど変わりません。違いは、行の読み取り元、送信先、およびスレッド間の行の分散方法にあります…
Exchange行の配布
アラートリーダーは、この時点でいくつかの詳細について疑問に思うでしょう。紫色のブランチは、製品IDごとに正しい結果をどのように計算しますか しかし、緑のブランチはできませんでした(同じ製品IDの結果が多くのスレッドに分散されました)?また、8つの個別のマージ結合(スレッドごとに1つ)がある場合、SQL Serverは、結合する行が同じインスタンスになることをどのように保証しますか 参加の?
これらの質問は両方とも、2つのRepartition Streamsがプロデューサー側(緑とオレンジのブランチ)からコンシューマー側(紫のブランチ)に行を交換する方法を調べることで答えることができます。最初に、オレンジと紫の枝に隣接するRepartitionStreams交換を見ていきます。
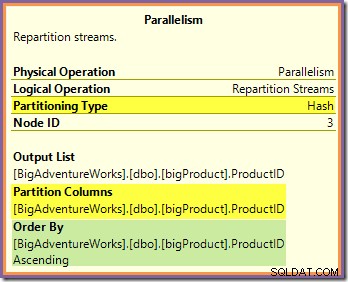
この交換は、製品ID列に適用されたハッシュ関数を使用して(オレンジ色のブランチからの)着信行をルーティングします。その結果、特定の製品IDのすべての行が保証されます。 同じ紫色の分岐スレッドにルーティングされます。オレンジと紫のスレッドは、このルーティングについて何も知りません。これはすべて、取引所によって内部的に処理されます。
オレンジ色のスレッドはすべて、行を要求した親イテレーター(交換のプロデューサー側)に行を返していることを知っています。同様に、すべての紫色のスレッドは、データソースから行を読み取っていることを「知っています」。交換は、着信オレンジスレッド行が入るパケットを決定します。これは、8つの候補パケットのいずれかである可能性があります。同様に、交換は、紫色のスレッドからの読み取り要求を満たすために、行を読み取るパケットを決定します。
特定のオレンジ(プロデューサー)スレッドが特定のパープル(コンシューマー)スレッドに直接リンクされているというイメージを取得しないように注意してください。これは、このクエリプランが機能する方法ではありません。オレンジの生産者はかもしれません 最終的にすべての紫色の消費者に行を送信します–ルーティングは、処理する各行の製品ID列の値に完全に依存します。
また、交換での行のパケットは、いっぱいになったとき(またはプロデューサー側でデータが不足したとき)にのみ転送されることに注意してください。パケットを一度に1行ずつ満たす交換を想像してください。ここで、特定のパケットの行は、プロデューサー側(オレンジ)のスレッドのいずれかから来る可能性があります。パケットがいっぱいになると、コンシューマー側に渡され、特定のコンシューマー(紫色)スレッドがパケットからの読み取りを開始できます。
緑と紫の枝に隣接するRepartitionStreams交換は、非常によく似た方法で機能します。
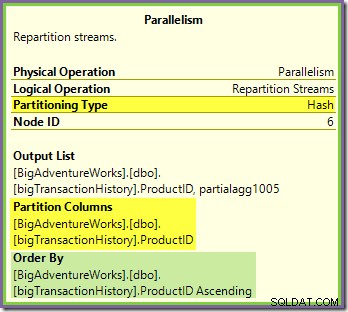
同じハッシュ関数を使用して、この交換で行がパケットにルーティングされます。 同じパーティショニング列 前に見たオレンジと紫の交換について。これは、両方を意味します Repartition Streamsは、同じ製品IDのルート行を同じ紫色の分岐スレッドに交換します。
これは、紫色のブランチのStream Aggregateがグローバル集約を計算する方法を説明しています。特定の紫色のブランチスレッドで特定の製品IDを持つ1つの行が表示された場合、そのスレッドはその製品IDのすべての行を表示することが保証されます(他のスレッドはそうします)。
共通交換パーティション列は、マージ結合の結合キーでもあるため、結合できる可能性のあるすべての行は、同じ(紫色の)スレッドによって処理されることが保証されます。
最後に注意すべきことは、両方の交換が注文を保持することです。 ツールチップのOrderBy属性に示されているように、(別名「マージ」)交換。これは、入力行を結合キーでソートするという結合結合の要件を満たしています。エクスチェンジは行自体を並べ替えることはなく、保存するように構成するだけでよいことに注意してください。 既存の注文。
スレッドゼロ
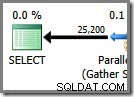
実行プランの最後の部分は、GatherStreamsエクスチェンジの左側にあります。これは常に単一のスレッドで実行されます。これは、通常のシリアルプラン全体を実行するために使用されるものと同じです。このスレッドは、実行計画では常に「スレッド0」とラベル付けされており、「コーディネーター」スレッドと呼ばれることもあります(特に役立つとは思わない指定です)。
スレッド0は、Gather Streams交換のコンシューマー(左側)側から行を読み取り、それらをクライアントに返します。この例では、交換以外にスレッドゼロのイテレータはありませんが、存在する場合は、すべて同じ単一スレッドで実行されます。 Gather Streamsもマージ交換であることに注意してください(Order By属性があります):

より複雑な並列計画には、最後のGatherStreams交換の左側にあるもの以外のシリアル実行ゾーンを含めることができます。これらのシリアルゾーンはスレッドゼロで実行されませんが、それは別の時間を探索するための詳細です。
予約および使用されたスレッドの再検討
この並列計画には3つのブランチが含まれていることがわかりました。これは、SQLServerが予約された理由を説明しています 24スレッド(DOP 8で3つのブランチ)。問題は、上のスクリーンショットで「使用済み」として報告されるスレッドが16個だけである理由です。
答えには2つの部分があります。最初の部分はこの計画には適用されませんが、とにかく知っておくことが重要です。報告されるブランチの数は、同時に実行できる最大数です。 。
ご存知かもしれませんが、特定のプランオペレーターは「ブロック」しています。つまり、最初の出力行を生成する前に、すべての入力行を消費する必要があります。ブロッキング(ストップアンドゴーとも呼ばれます)演算子の最も明確な例は、並べ替えです。最後の入力行が最初にソートされる可能性があるため、ソートでは、すべての入力行が表示される前に、ソートされた順序で最初の行を返すことはできません。
複数の入力(たとえば、結合と結合)を持つオペレーターは、一方の入力に関してはブロッキングできますが、もう一方の入力に関しては非ブロッキング(「パイプライン化」)できます。この例はハッシュ結合です。ビルド入力はブロックされていますが、プローブ入力はパイプライン化されています。ビルド入力は、プローブ行がテストされるハッシュテーブルを作成するため、ブロックされています。
ブロッキング演算子の存在は、1つ以上の並列ブランチが可能性があることを意味します。 他の人が開始する前に完了することが保証されています。これが発生した場合、SQLServerは再利用できます シーケンス内の後続のブランチのために、完了したブランチを処理するために使用されるスレッド。 SQL Serverはスレッドの予約に関して非常に保守的であるため、保証されているブランチのみです。 別の開始前に完了するには、このスレッド予約の最適化を利用してください。クエリプランにはブロッキング演算子が含まれていないため、報告されるブランチ数はブランチの総数にすぎません。
答えの2番目の部分は、スレッドが発生した場合でも、スレッドは再利用される可能性があるということです。 別のブランチのスレッドが起動する前に完了します。この場合、スレッドの全数は引き続き予約されていますが、実際の使用量は少なくなる可能性があります。並列プランが実際に使用するスレッドの数は、特にタイミングの問題によって異なり、実行ごとに異なる可能性があります。
並列スレッドはすべて同時に実行を開始するわけではありませんが、その詳細は別の機会を待つ必要があります。クエリプランをもう一度見て、ブロッキング演算子がないにもかかわらず、スレッドがどのように再利用されるかを確認しましょう。
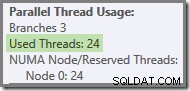
ブランチ1のスレッドは、ブランチ2または3のスレッドが起動する前に完了できないことは明らかであるため、そこでスレッドが再利用される可能性はありません。ブランチ3もありそうもない ブランチ1またはブランチ2のいずれかが起動する前に完了する必要があります。これは、実行する作業が非常に多いためです(集計するのに約3200万行)。
ブランチ2は別の問題です。製品テーブルのサイズが比較的小さいということは、ブランチが前に作業を完了できる可能性が十分にあることを意味します。 ブランチ3が起動します。製品テーブルを読み取っても物理的なI/Oが発生しない場合、8つのスレッドが25,200行を読み取り、オレンジと紫の境界の再パーティションストリーム交換に送信するのにそれほど時間はかかりません。
これは、この投稿でこれまでに見たスクリーンショットに使用されたテスト実行で起こったこととまったく同じです。8つのオレンジ色のブランチスレッドは、緑色のブランチに再利用できるほど迅速に完了しました。合計で16の一意のスレッドが使用されたため、実行プランで報告されます。
クエリがコールドキャッシュを使用して再実行される場合、物理I / Oによって導入される遅延は、オレンジ色のブランチスレッドが完了する前に緑色のブランチスレッドが確実に起動するのに十分です。スレッドは再利用されないため、実行プランでは、24個の予約済みスレッドすべてが実際に使用されたと報告されています。
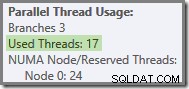
より一般的には、2つの極値(このクエリプランでは16と24)の間の「使用済みスレッド」がいくつでも可能です。
最後に、最終的なGatherStreamsの左側にあるプランのシリアル部分を実行するスレッドはカウントされないことに注意してください。 並列スレッドの合計で。並列実行に対応するために追加された追加のスレッドではありません。
最終的な考え
SQL Serverが並列実行を実装するために使用する交換モデルの利点は、スレッド間の行のバッファリングと移動のすべての複雑さが、交換(並列処理)演算子の内部に隠されていることです。計画の残りの部分は、取引所に囲まれたきちんとした「ブランチ」に分割されます。ブランチ内では、各オペレーターはシリアルプランの場合と同じように動作します。ほとんどの場合、ブランチオペレーターは、より広いプランが並列実行を使用していることをまったく知りません。
並列実行を理解するための鍵は、交換境界で並列計画を(精神的に)分解し、各ブランチをDOPの個別のシリアルとして描くことです。 計画、すべてが行の個別のサブセットで同時実行を実行します。特に、そのような各シリアルプランは、そのブランチ内のすべてのオペレーターを実行することに注意してください。SQLServerは実行しません 各オペレーターを独自のスレッドで実行してください!
最も詳細な動作を理解するには、特に行が交換内でどのようにルーティングされるか、エンジンが正しい結果を保証する方法について少し考える必要がありますが、知っておく価値のあるほとんどのことには少し考える必要がありますね。
>