edXやCourseraなどのMOOCオンライン学習プラットフォームを実行している場合、どのように整理しますか?この記事では、その仕事をするデータベースモデルを見ていきます。
オンラインで学ぶトレンドの方法であるMOOC(Massive Open Online Course)について聞いたことがあると思います。まだの場合は、MOOCプログラムを、すべての資料、テスト、フィードバックをオンラインで利用できる大学の科目と考えてください。最も人気のあるオンラインMOOCプロバイダーの2つは、Coursera(スタンフォード大学によって設立された)とedX(マサチューセッツ工科大学とハーバード大学によって設立された)です。他の大学やパートナーと協力して、世界中の何百万人もの学習者に何百ものコースを提供しています。
この記事では、このタイプのサービスを実行するために使用できるデータベースモデルの簡略化されたバージョンについて説明します。まず、MOOCが実際にどのように機能するかについて非技術的な観点から説明しましょう。
MOOCプラットフォームはどのように機能しますか?
個人的には、Courseraを使用していて、非常に満足しています。したがって、この記事での私のコメントは、edXも同様のパターンに従っていると思いますが、主にCourseraのモデルに関連しています。
ビジネスモデルは何ですか?
アイデアはとてもシンプルです。パートナー(主に大学)は、オンラインコースの資料を作成します。これは通常、キャンパスの提供内容に基づいています。これらの資料には、ビデオ講義、リーディング、クイズ、ディスカッション、プロジェクト、オンラインテスト、場合によっては最終課題が含まれます。資料の多くはビデオベースであるため、学習者はその「人間的なタッチ」を得ることができます。教えられたことだけでなく、講師のおかげで、いくつかのコースを楽しんだ。
生徒は、提供された資料を視聴または読んだり、課題を完了したり、クイズに答えたり、テストを受けたりする必要があります。通常、1つ以上のプロジェクトの課題もあり、これらすべての課題の成績が最終成績を構成します。最終成績が特定のスコア(例:70%)を超える場合、学生はコースに合格し、証明書を受け取ります。一部の証明書は無料です。他の人は比較的少額の支払いを必要とします。同じことがコースにも当てはまります。
関連するコースは、スペシャライゼーションと呼ばれるより大きなエンティティに編成できます。スペシャライゼーションを完了すると、学生に別の証明書(およびより丸みのあるスキルセット)が与えられ、各コースを個別に完了するよりも費用がかからない場合があります。
すべてのコースと専門分野は、異なるセッションを持つことができます。毎月新しいセッションを行うものもあれば、毎年1つの新しいセッションを行うものもあります。オンデマンドで利用できるコースもあります。
オンライン証明書はまだ大学の証明書と同じ重みを持っていませんが、彼らはそれを目指しています。一部のコースはすでに大学の単位として承認されており、オンライン学習プログラムも現在現実のものとなっています。
パートナー、コース、学生は何人いますか?
簡単な答えは「たくさん」です。コースは数千人、パートナーは数百人、学生は数百万人で測定されます–世界のほぼすべての国から。
MOOCにどのような変化が期待できますか?
MOOCの優れている点は、変化にすばやく適応できることです。州や大学の規制による制限はなく、承認を待つ必要はありません。これは、特にIT関連のコースにとって非常に重要です。一部のコースと専門分野には新しいセッションがありません。他の新しいコースが表示され、既存のコースはさまざまな更新が行われます。
MOOCデータベースモデル
MOOCデータモデルを3つのサブジェクトエリアに分割しました:
コースの詳細専門分野の詳細学生の参加
そして、3つのスタンドアロンテーブルがあります:
機関講師学生
スタンドアロンテーブルは、サブジェクトエリアのさまざまなテーブルのデータソースとして使用されます。サブジェクトエリアにはほとんどのロジックが含まれているため、最初にそれらを説明してから、スタンドアロンテーブルに移動します。
コースと資料
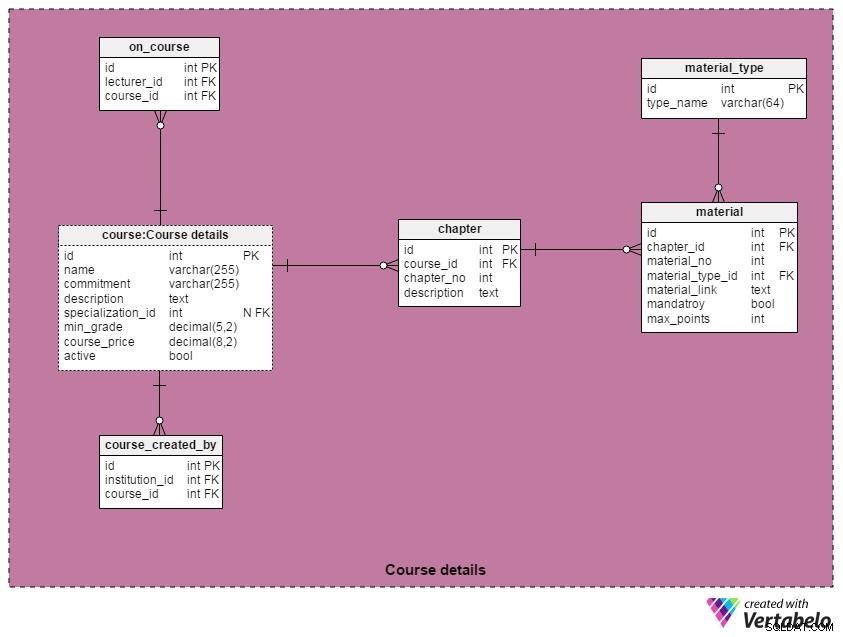
通常、人はあらゆる取引の最も重要な部分ですが、ここでは例外を設けます。コース資料がなければ、コースはありません。したがって、MOOCプラットフォームには関心がありません。 「コースの詳細」では、コース、関連機関、パートナー、および資料を説明するすべての表をグループ化しました。
このセクションで最も重要な表は、コースです。 テーブル。属性は次のとおりです。
名前 –一意のコース名コミットメント–コミットメントの可能性のテキスト説明。例: 「5週間の学習、5〜7時間/週」説明–コースの説明-
specialization_id–該当する場合は、関連する専門分野への参照。コースは、1つの専門分野にのみ参加できます。一部のコースは専門分野と提携していないため、この属性は必須ではありません。 -
min_grade–コースに合格するために必要な最低成績。通常、それはパーセンテージとして測定されます。ほとんどのCourseraコースでは、これは70%です。 -
course_price–コースに支払う料金。 アクティブ–コースに将来のセッションがあるかどうかを示すオン/オフスイッチ。アクティブなコースには新しいセッションがありますが、非アクティブなコースにはありません。
コースに注意してください テーブルの名前はcourse:Course details 。これは、コースを使用したためです モデルをより明確にするために、別の場所で再度テーブルを作成します。これを行うために、Vertabeloの[コピー]および[ショートカットとして貼り付け]オプションを使用しました。
各コースはいくつかの章で構成されています。 Courseraでは、学生は通常、各章を完了するために1週間あります。すべてのコースサブセクションまたはチャプターのリストは、チャプターに保存されます テーブル。 course_id 属性はコースへの参照です テーブル; chapter_no そのコースの章の序数です。これらの2つの属性は一緒になって、テーブルの代替キーを形成します。最後の属性、 description 、各章の詳細な説明を保存します。
各章は、ビデオ講義、リーディング、クイズ、テスト、プロジェクトで構成されています。さまざまな材料タイプを格納するために、データベースに個別の構造を作成することはありません。代わりに、これらの資料へのリンクを保存します。そして、それが資料の場所です テーブルが入ります。このテーブルの属性は次のとおりです。
-
chapter_id–関連する章への参照 -
Material_no–さまざまな章の資料に割り当てられた序数。chapter_idと一緒に 属性。この属性は、テーブルの代替(一意)キーを形成します。 -
Material_type_id–はMaterial_typeへの参照ですテーブル 必須–マテリアルが必須かオプションか(つまり、追加のクレジット用)を示すブール値-
max_points–この資料を完了した後に学生が達成できるポイントの最大数。ポイントが付与されない場合は、値として「0」を使用します。
マテリアルタイプ 表は、考えられるすべてのマテリアルタイプの辞書です。主キーの横にある唯一の属性はtype_nameです もちろん、一意の値のみが含まれている必要があります。予想される資料の種類には、「ビデオ講義」があります。 、「読み取り」 、「クイズ」 、「テスト」 、「最終試験」 および「プロジェクトの割り当て」 。
on_course 表は、各コースをそのコースを教えている講師と関連付けています。主キーと外部キーのペア( lecturer_id )のみが含まれます およびcourse_id )。外部キーのペアは、テーブルの一意のキーを形成します。
同様に、 course_created_by コースの作成に関与したすべての教育機関にコースを関連付けます。
専門分野
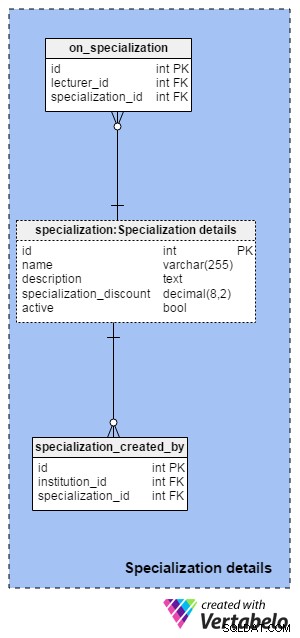
スタンドアロンコースは素晴らしいですが、新しいスキルを習得するには、複数のコースが必要になります。スペシャライゼーションはその方向への一歩です。これらは一連のコースであり、多くの場合4つまたは5つであり、学習したスキルを適用できる最終的なプロジェクトです。スペシャライゼーションに関連するすべてのテーブルは、スペシャライゼーションの詳細にあります。 範囲。
専門分野 tableは、このセクションの中央のテーブルです。専門分野ごとに、一意の nameを保存します およびdescription 。 specialization_discount は、スタンドアロンコースに個別に登録するのではなく、専門分野全体に登録した場合に学生が節約できる金額です。以前と同様に、 active 属性は、スペシャライゼーションに将来のセッションがあるかどうかを示す単純なオン/オフスイッチです。
専門分野に注意してください テーブルもモデルに2回表示されます。この領域内では、 specialization:Specialization detailsという名前が付けられています 。
on_specialization およびspecialization_created_by テーブルはon_course と同じ目的を持ち、同じロジックに従います およびcourse_created_by テーブル。もちろん、今回はコースではなく専門分野を扱います。
学生
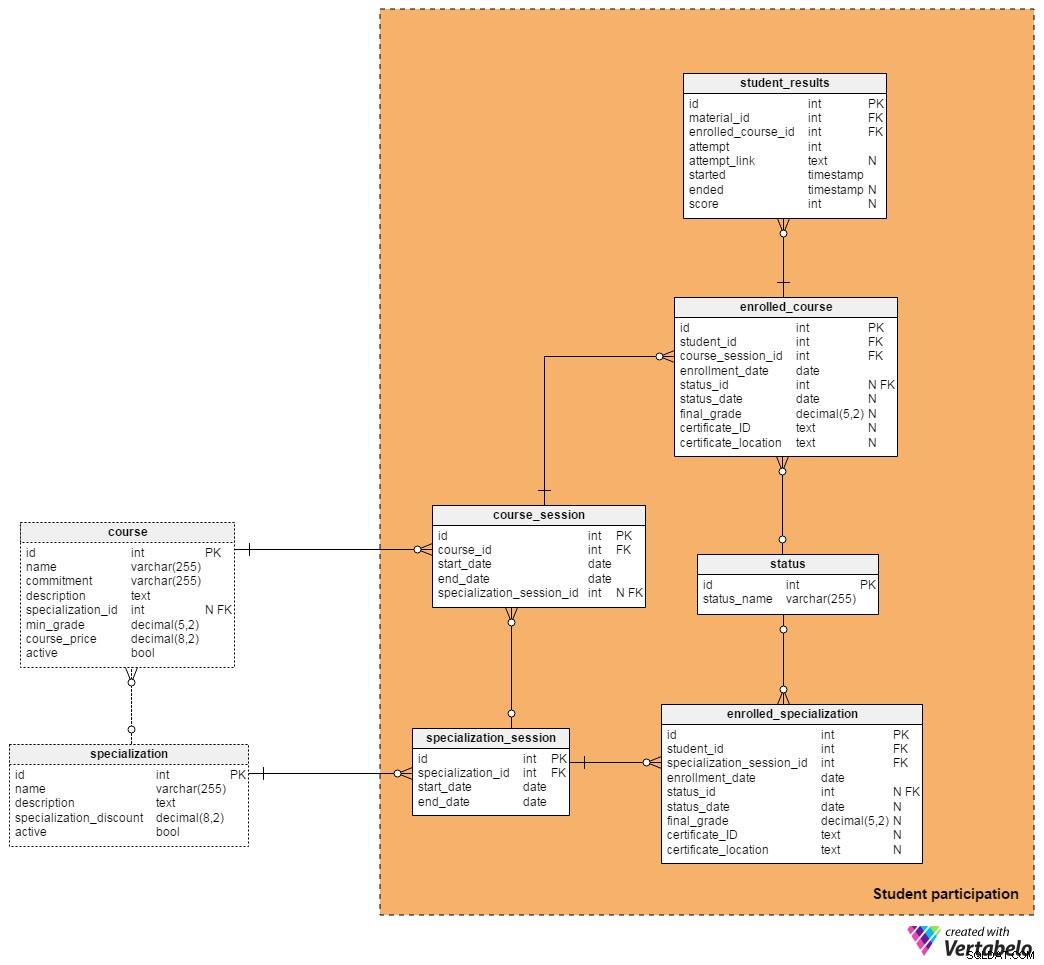
そして最後に、学生セクションに行きます。 学生の参加 エリアでは、生徒、セッション、生徒の成績の記録を保存します。
各コースとスペシャライゼーションは複数のセッションを持つことができるため、各コースとスペシャライゼーションの開始時と終了時を保存する必要があります。コースの場合、それは非常に簡単です。新しいセッションはそれぞれ、同じコースの新しいインスタンスにすぎません。新しいスペシャライゼーションセッションは、スペシャライゼーション全体とそのすべてのコースの新しいインスタンスです。
学生は専門分野から1つのコースまたはすべてのコースに登録できることを忘れないでください。 course_sessions およびspecialization_session 表はその情報を提供します。日付の他に、コースへの外部キーのみが含まれています およびspecialization_table テーブル。 外部キー開始日 ペアは、両方のテーブルで一意のキーを形成します。
コースセッションはスペシャライゼーションセッションの一部にすることもできるため、(必須ではない)外部キーを追加する必要があります。
ステータス 辞書には、コース中の生徒の成績に関連するすべての可能なステータスが一覧表示されます。考えられるステータスのいくつかは、「ドロップアウト」です。 、「合格」 および「失敗」 。
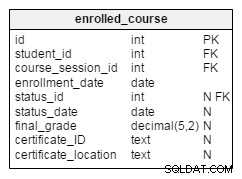
enrolled_courseを使用します コースセッションのすべての登録を保存するテーブル。このテーブルには、 student_idという2つの外部キーが含まれています。 およびcourse_session_id 、およびそれらが一緒になって、テーブルの代替(一意)キーを形成します。表の他の属性は次のとおりです。
-
enrollment_date–学生がそのコースに登録した日付 -
status_id–ステータスへの参照辞書;これは、学生がそのコースでどのように実行したかを記録します -
status_date–ステータスが割り当てられた日付 -
final_grade–学生がそのコースで達成した成績(パーセンテージ) -
certificate_ID–学生がコースに合格したときにプラットフォームが生成する証明書識別番号 -
certificate_location–証明書が保存されている正確な場所へのリンク

enrolled_specialization テーブルは、 enrolled_courseと同じロジックに従います テーブル。違いは、コースではなく専門分野に学生を関連付けることです。

student_resultsを使用します 特定の教材に関する生徒のパフォーマンスを保存するためのテーブル。マテリアルごとに( Material_id )および各学生の登録( enrolled_course_id )複数回試行する可能性があります。したがって、 try 属性は、各生徒の試行の序数です。これらの3つの属性が一緒になって、テーブルの代替キーを形成します。
この表では、attempt_link 学生によって提出されたテストまたはプロジェクトの各インスタンスの場所です。試行ごとに、ランダムに選択された質問を使用して「新しい」テストを生成すると想定できます。資料に生徒の回答が必要ない場合、リンクは存在しないため、ここにNULL値を保存します。
最後に、 student_results 学生が開始したときのテーブルストア およびend 試行とスコア 達成。また、採点されていない課題のパフォーマンス結果を保存したり、視聴した動画や時間、読んだ資料などを記録したりすることもできます。
機関

機関 表は、コースを作成した、または講師がコースに参加しているすべての教育機関を一覧表示する単純なカタログです。
講師

ここではもっと詳細な表を使用することもできますが、各講師の名前、役職、大学名を保存するだけで十分です。当然のことながら、これはすべて講師に保管されています テーブル。
学生
表の概要を学生で締めくくります テーブル。繰り返しになりますが、ここで必要なのは基本的な属性だけであり、それらは自明である必要があります。
このモデルをどのように改善できますか?
このモデルは、MOOCプラットフォームを作成するために必要な基本機能をサポートしています。それでも、おそらく多くの便利な追加機能を簡単に思いつくことができます。これが私が思いついたいくつかです:
- ビデオ講義のコース言語と字幕
- マシンのグレーディング
- 生徒はお互いの課題を確認して採点します
- 財政援助
- 学生がコースを中退した後にコースを再開できるようにするオプション
ウィキペディアによると、 ... Courseraのデータベースサーバー(RDS上で実行)は100億のSQLクエリに応答し、Courseraは1か月あたり約500TBのトラフィックを処理します。 これは2013年のことです。実際のMOOCデータベースモデルはこの記事で紹介したもののように見えるかもしれませんが、モデリングとインフラストラクチャについてはまだまだやるべきことがたくさんあります!
この記事では、MOOCプラットフォームの背後にあるモデルの複雑さを示してみました。例として、主にCourseraとedXに焦点を当てました。このモデルには18個のテーブルが含まれていますが、表面を傷つけるだけです。モデルに実装する改善点についてコメントし、共有してください。重要なことを見逃したと思われる場合は、お知らせください。
オンラインで学ぶのが好きですか? LearnSQL.com –ブラウザで利用できるインタラクティブSQLコースをお試しください。