厳しい競争のこの時代において、ジョブポータルは、ジョブを公開および検索するための単なるプラットフォームではありません。彼らは高度なサービスと機能を活用して、顧客の関心を維持しています。いくつかの高度な機能を詳しく調べて、それらを処理できるデータモデルを構築しましょう。
前回の記事で、求人ポータルサイトに必要な基本機能について説明しました。モデルを以下に示します。このモデルをベースと見なし、新しい要件を満たすために変更します。まず、これらの要件(または拡張機能)を検討しましょう。
オンライン求人ポータルデータモデルに何を追加しますか?
簡単に説明すると、以前のデータモデルに4つの拡張機能を追加します。
- 求職者向けのパーソナルダッシュボード。 これにより、すべての求人応募が追跡され、ステータスの変更(つまり、応募の受信から審査への変更)に関する最新情報がリアルタイムで提供されます。
- プロファイルダッシュボード。 これは、求職者のプロフィールにアクセスしているユーザーと、過去1日、1週間、または1か月間に履歴書がダウンロードされた回数の詳細です。
- 有料サービス管理。 ジョブポータルは、多くの場合、専門家の履歴書の準備、ソーシャルプロファイル管理、キャリアコンサルティングなどのサービスを提供します。私たちの新しい機能は、有料のサービスをサポートできるようになります。
- 申請前のフォーム管理。 応募者が求人応募を提出すると、勤務時間、場所、身元調査に関連する簡単な質問票に記入するよう求められる場合があります。このフォームを採用担当者がカスタマイズし、質問と回答をシステムが取得できるように構築します。
拡張機能#1:パーソナルダッシュボード
回答する質問: 提出された申請書の現在の状況はどうなっていますか?面接の最終候補になりますか?まだ見たことがありますか?
job_application_status_idを配置することで、求人応募を追跡できます。 job_post_activity テーブル。この列には、求人応募の現在のステータスが表示されます。別のテーブルjob_application_status 、すべての可能なアプリケーションステータスを保持します。一部のステータスは、「送信済み」、「審査中」、「アーカイブ済み」、「拒否済み」、「面接の最終候補者リスト」、「募集中」などです。
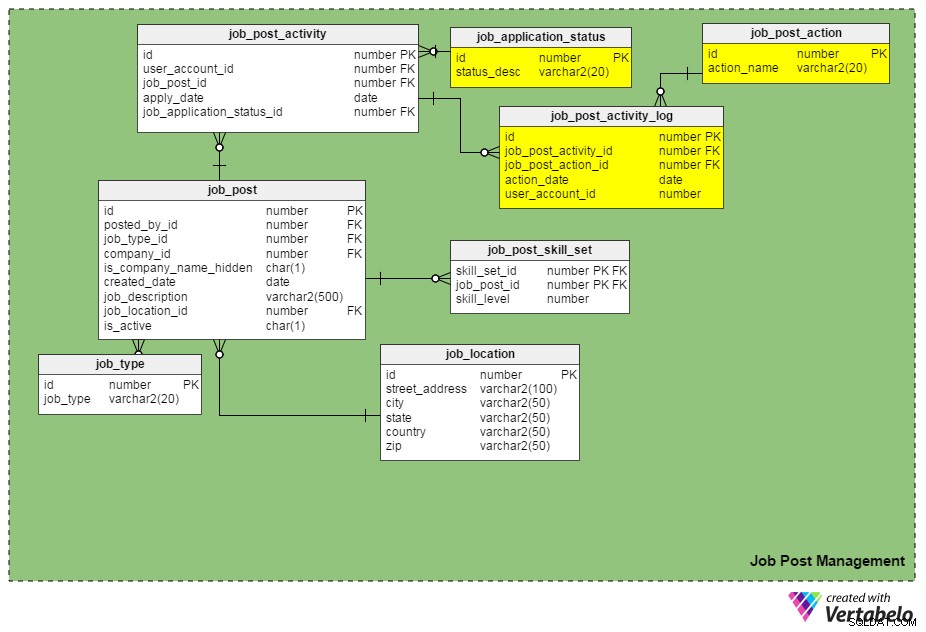
もう1つの新しいテーブル、job_post_activity_log 、ジョブアプリケーションで実行されたすべてのアクション、アクションを実行したユーザー、およびアクションがいつ実行されたかに関する情報を格納します。このテーブルには、次の列が含まれています。
-
id–テーブルの主キー。 -
job_post_activity_id–アクションが実行されるアプリケーションID。 -
job_post_action_id–実行されたアクションのID。これは、job_post_actionテーブル。ここに保存する可能性のあるアクションの種類には、「送信済み」、「表示済み」、「インタビュー済み」、「筆記テストの実施」、「処理中のオファー」、「ディスパッチされたオファー」、「受け入れられたオファー」などがあります。 -
action_date–アクションが実行された日付。 -
user_account_id–アクションを実行した人のID。
「job_post_action」は「job_application_status」と同じですか?それらはどのように異なりますか?
最初は同じように見えますが、実際には異なります。 2つの同様のフィールドが必要な正当な理由があります:
- 候補者は2人以上の人から別々に面接を受けます。 この場合、すべての面接ラウンドが完了するまで、求人応募のステータスは同じままです(つまり、「採用プロセス中」)。ただし、個々のインタビュアーのレコードは、
job_post_activity_logテーブル、および彼らは「インタビューされた」アクションを持っています。 - 同じ会社の複数の採用担当者がアプリケーションを表示できます。 これらの2つの属性を使用することで、申請者の情報を失うことはありません。
- 選択した候補者にオファーを行うには、複数の承認が必要です (つまり、財務チームからの承認、採用部門のマネージャーからの承認など)。この場合、求人応募のステータスは「審査中のオファー」のままですが、データベースは、
job_post_activity_logテーブル。
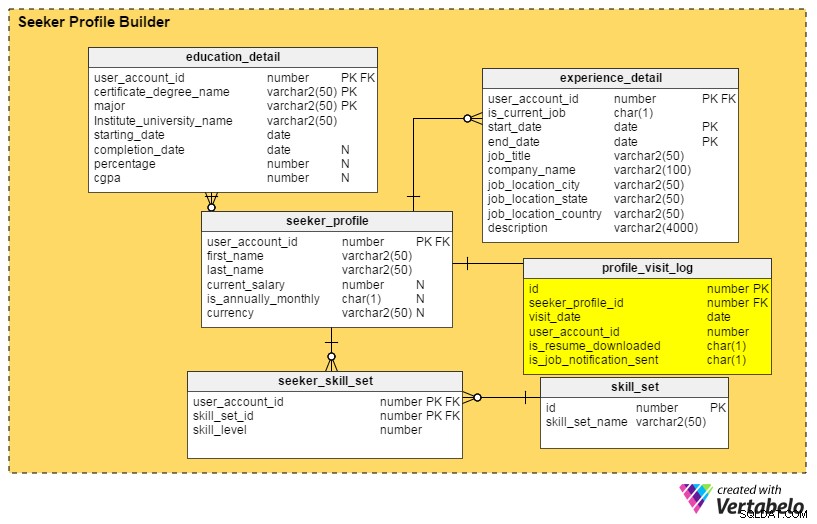
拡張機能#2:プロファイルダッシュボード
回答する質問: 最近私のプロフィールを見つけたのは誰ですか?先月、1週間、または1日に、採用担当者は何回閲覧しましたか?トップ企業の採用担当者は私のプロフィールを見ましたか?
これらすべての質問に対する回答は、profile_visit_log テーブル。このテーブルには、プロファイルにアクセスしたユーザー、プロファイルが表示された日時など、すべてのプロファイル訪問データがキャプチャされます。この表の列は次のとおりです。
-
id–テーブルの主キー。 -
seeker_profile_id–どのプロファイルにアクセスしたか。 -
visit_date–プロファイルにアクセスしたとき。 -
user_account_id–プロフィールを見た人。 -
is_resume_downloaded–訪問中に関連する履歴書がダウンロードされたかどうかを示すフラグ列。この列は、採用担当者が履歴書をダウンロードした回数を導き出すのに役立ちます。 -
is_job_notification_sent–別のフラグ列。これは、ジョブ通知がプロファイルの所有者に送信されたかどうかを示します。
機能強化#3:有料サービス管理
回答する質問: オンラインポータルは追加の有料サービスをどのように活用できますか?
多くのオンラインポータルは、仕事を投稿および検索するためのプラットフォームに加えて、専門家の履歴書作成、キャリアコンサルティングなどの他のサービスを提供します。また、求職者が夢の街で夢の仕事を見つけるのに役立つ製品も提供しています。たとえば、主要な求人サイトの1つは、あなたのプロフィールを採用担当者のリストのトップに保つ製品を提供しているため、より多くの面接のオファーを得ることができます。これらの製品またはサービスのほとんどは、サブスクリプションベースで利用できます。ユーザーがサービスまたは製品を購入すると、その製品またはサービスの使用に対して特定の期間(つまり、1か月、3か月、1年)にわたって支払います。
これらの求人ポータルを見て、単独で提供されている製品やサービスはほとんどないことに気づきました。ほとんどの場合、複数の製品とサービスが1つのパッケージにバンドルされており、このパッケージは求職者または採用担当者のいずれかに提供されます。
これらすべての点を考慮して、有料のサービスと製品を既存のオンライン求人サイトに組み込むための次のデータモデルを思いつきました。
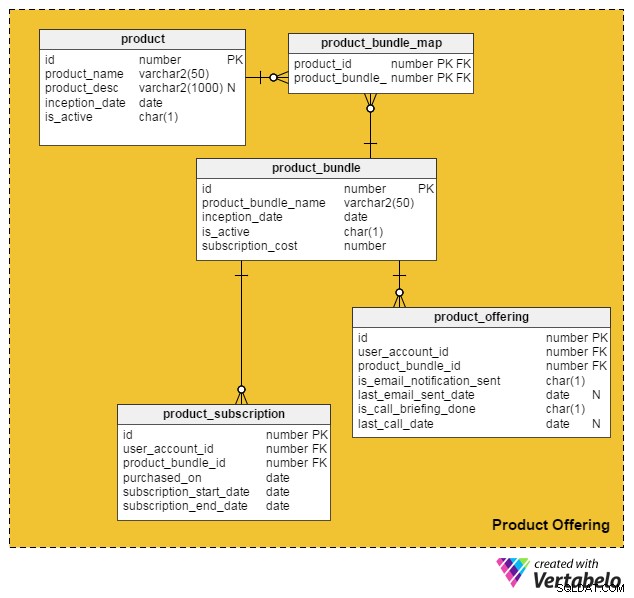
product 表には、個々の製品に関する詳細が含まれています。 (製品とサービスの両方を「製品」と呼びます)。この表の列は次のとおりです。
-
id–このテーブルの主キー。ポータルで提供される各製品に一意のIDを提供します。 -
product_name–製品の名前を保持します。 -
product_desc–製品の簡単な説明を保存します。 -
inception_date–製品が導入された日付。 -
is_active–製品がアクティブかどうか。
商品とサービスをまとめてまとめて顧客に提供できるため、product_bundle そのようなすべてのバンドルのレコードを格納するテーブル。属性は次のとおりです。
-
id–テーブルの主キー。各製品バンドルに一意のIDを提供します。 -
product_bundle_name–バンドルの名前を保存します。 -
inception_date–バンドルが導入された日付。 -
is_active–バンドルがアクティブかどうかを示します。 -
subscription_cost–バンドルに要求された価格を保存します。
単一の製品を顧客に提供できますか?
はい。このデータモデルでは、単一の製品を独自の「バンドル」にすることができます。次の表は、これと他のいくつかの重要な機能を処理します。
product_bundle_map テーブルには、バンドルの一部であるすべての製品のリストが格納されます。その属性は自明です。
次の表、product_subscription 、顧客が製品バンドルをサブスクライブするときに機能します。どの顧客がどのバンドルにスクライブしたかの詳細を記録します。この表の列は次のとおりです。
-
id–テーブルの主キー。 -
user_account_id–バンドルを購入したユーザー。 -
product_bundle_id–ユーザーが購入した製品バンドル。 -
purchased_on–購入日。 -
subscription_start_date–サブスクリプションが開始される日付。製品の購入日とサブスクリプションの開始日は異なる場合があることに注意してください。したがって、これらには2つの異なる列があります。 -
subscription_end_date–サブスクリプションが終了する時期。
ファイナルテーブル、product_offering 、主にマーケティングに使用されます。通常、求人ポータルはユーザーの最近の活動(求職者と採用担当者の両方)を分析し、どの製品がどのユーザーにとって有益であるかを決定します。次に、電子メールまたは電話を使用して、選択した製品について顧客に連絡します。このテーブルの列は次のとおりです。
-
id–テーブルの主キー。 -
user_account_id–求人ポータルが対象としているユーザー。 -
product_bundle_id–ポータルマーケターがユーザーに一致させた製品バンドル。 -
is_email_notification_sent–製品の提供に関する電子メールが送信されたかどうか。 -
last_email_sent_date–ユーザーがマーケティングチームから製品の電子メールを最後に受信したとき。マーケターは、ユーザーに複数の通知を送信し、他の通知を定期的に送信するのが一般的です。この列には、最後の通知が送信された日付が格納されます。 -
is_call_briefing_done–顧客が製品について説明する電話を受けたかどうか。 -
last_call_date–最新の電話の日付。顧客に対して複数の呼び出し(フォローアップ呼び出し)が行われる可能性があります。
機能強化#4:事前申請フォーム管理
回答する質問: 採用担当者は、すべての潜在的な求職者が記入したカスタマイズされた同意書をどのように入手できますか?
多くの場合、求職者は投稿を申請するときに特定の質問に答えます。これには通常、犯罪歴調査への同意などが含まれます。ただし、他にもさまざまな種類の同意が必要になる場合があります。たとえば、マーケティングの仕事には多くの出張が必要になる場合があります。ビジネスプロセスアウトソーシング(BPO)の仕事では、従業員が墓地(つまり深夜)のシフトで働く必要がある場合があります。これらは事前申請フォームで対処されます。
求人応募の際には、必ず同意を得るのが最善です。このように、これらの要件を満たしたくない候補者は、その仕事に応募しません。
データモデルにジャンプする前に、まず同意書に関するいくつかの基本的な事実を強調しましょう。
- 求人情報には複数の同意書を含めることができます。
- 各同意書には、さまざまなセクションに関連するさまざまな質問があります。
- 質問は、フォームでの質問のタグ付け方法に応じて、必須またはオプションとして設定できます。質問は、ある形式ではオプションで、別の形式では必須にすることができます。
- 各質問には、(1)はい、(2)いいえ、または(3)該当なしのいずれかで回答できます。
- すべての回答が記録されます。
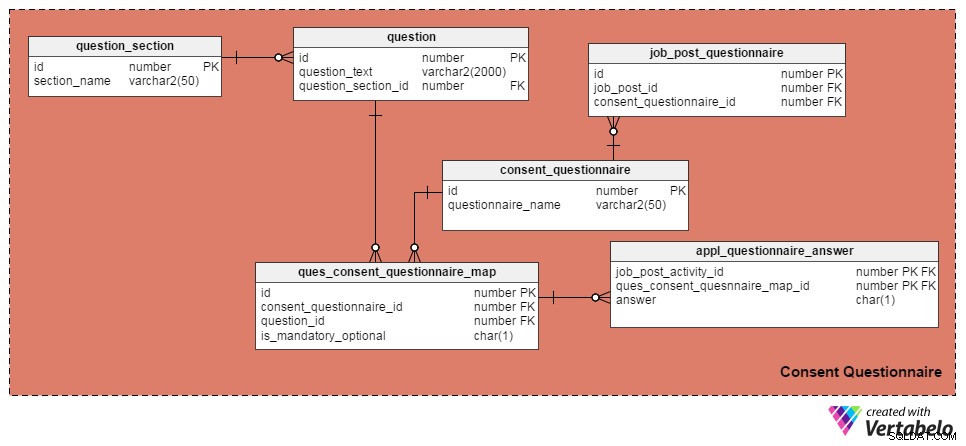
次の4つの表を使用して、質問と同意書を管理しました。 1つ目は、question テーブル、質問のリストを保持します。次の属性があります:
-
id–テーブルの主キー。各質問に一意のID番号を与えます。 -
question_text–実際の質問テキストを保存します。 -
question_section_id–質問が表示されるセクション。 (例:「ソフトウェア開発に5年以上携わったことがありますか?」は、「実務経験」セクションに表示されます。)これは、question_sectionテーブル。
question_section テーブルにはセクション情報が格納されます。これは、同じトピックに関連する質問をグループ化する方法です。 idは別として テーブルの主キーである属性。唯一の属性はsection_nameです。 、これは自明です。
consent_questionnaire テーブルには同意フォーム名が含まれます。その2つの属性も自明です。
ques_consent_questionnaire_map テーブルはこの主題分野の中核です。このサブジェクトエリアの他のすべてのテーブルは、直接または間接的に接続されています。その目的は、同意書にタグ付けされた質問のリストを保持することです。この表の列は次のとおりです。
-
id–このテーブルの主キー。 -
consent_questionnaire_id–同意書のID番号。 -
question_id–質問のID番号。 -
is_mandatory_optional–特定の同意書に対して質問が必須かオプションかを示します。質問は複数の同意書の一部にすることができますが、一部では必須であり、その他ではオプションである場合があります。これが、この列をquestionテーブル。
次のいくつかの表では、個々の求人情報へのタグ同意フォームについて説明し、候補者の回答を記録します。 job_post_questionnaire テーブル。どの同意書が求人情報の一部であるかに関する情報を格納します。求人情報でタグ付けされた1つ以上の同意書が存在する場合があります。この表の列は次のとおりです。
-
id–テーブルの主キー。 -
job_post_id–同意書にタグが付けられているジョブ投稿を示します。 -
consent_questionnaire_id–求人情報にタグ付けされた同意書。
次に、appl_questionnaire_answer 表には、申請者が記入した各同意書の質問に対する個々の回答が記録されます。この表の列は次のとおりです。
-
job_post_activity_id–job_post_activityテーブル。質問に回答した候補者に関する情報が保存されます。 -
quest_consent_quesnnaire_map_id–quest_consent_questionnaire_mapテーブル。どの質問からどの同意書に回答するかを保存します。 answer–求職者の実際の回答。モデル内のすべての質問は「はい」(回答=「Y」)、「いいえ」(回答=「N」)、または「該当なし」(回答='X')。
新しく改善されたオンライン求人ポータルデータモデル
完成したデータモデルを以下に示します。
何を追加しますか?
オンライン求人ポータルに追加する他の機能について考えてみてください。コメントセクションであなたの意見を共有してください。