時間の経過とともに変化するエンティティの状態を管理する必要がある状況に遭遇したことがありますか?そこには多くの例があります。簡単なものから始めましょう:顧客レコードのマージ。
2つの異なるソースからの顧客のリストをマージするとします。次のいずれかの状態が発生する可能性があります。重複が特定された –システムは2つの潜在的に重複するエンティティを検出しました。 確認済みの重複 –ユーザーは、2つのエンティティが実際に重複していることを検証します。または確認済みの一意 –ユーザーは、2つのエンティティが一意であると判断します。これらの状況のいずれにおいても、ユーザーは「はい」または「いいえ」の決定を下すだけです。
しかし、もっと複雑な状況はどうでしょうか?州間の実際のワークフローを定義する方法はありますか?続きを読む…
物事が簡単にうまくいかない方法
多くの組織は、求人応募を管理する必要があります。単純なモデルでは、JOB_APPLICATION 、および次のような値を含む参照データテーブルを使用して、アプリケーションの状態を追跡できます。
| アプリケーションステータス |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
これらの値は、いつでも任意の順序で選択できます。各段階で論理的かつ正しい選択が行われるようにするために、エンドユーザーに依存しています。非論理的な一連の状態を禁止するものはありません。
たとえば、申請が却下されたとします。現在のステータスは明らかにAPPLICATION_REJECTEDになります 。経験の浅いユーザーが後でINVITED_TO_INTERVIEWを選択するのを防ぐために、アプリケーションレベルで実行できることは何もありません。 または他の非論理的な状態。
必要なのは、ユーザーが次の論理状態を選択するようにガイドするもの、つまり論理ワークフローを定義するものです。 。
また、さまざまな種類の求人応募に対してさまざまな要件がある場合はどうなりますか?たとえば、仕事によっては、適性検査を受ける必要がある場合があります。もちろん、これらをカバーするためにリストに値を追加することはできますが、現在の設計には、エンドユーザーが問題のアプリケーションのタイプに対して誤った選択を行うことを妨げるものは何もありません。現実には、さまざまなワークフローがあります さまざまなコンテキストの場合 。
考慮すべきもう1つのポイント:リストされているオプションは実際にはすべての状態ですか ?または、実際にはいくつかの結果 ?たとえば、求人は応募者が承認または拒否することができます。したがって、JOB_OFFER_MADE 実際には2つの結果があります:JOB_OFFER_ACCEPTED およびJOB_OFFER_DECLINED 。
別の結果として、求人が取り下げられる可能性があります。修飾子を使用して取り下げられた理由を記録することをお勧めします。これらの理由を上記のリストに追加しただけでは、エンドユーザーが論理的な選択を行うように導くものは何もありません。
したがって、実際には、状態、結果、および修飾子が複雑になるほど、ワークフローを定義する必要があります。 プロセスの 。
プロセス、状態、および結果の整理
データをモデル化する前に、データで何が起こっているのかを理解することが重要です。最初は、ここにタイプの厳密な階層があると考える傾向があるかもしれません:
上記の例を詳しく見ると、INVITED_TO_INTERVIEW およびJOB_OFFER_MADE 州は同じ可能な結果、つまりACCEPTEDを共有します およびDECLINED 。これは、多対多の関係があることを示しています。 状態と結果の間。これは、他の州、結果、および修飾子にも当てはまることがよくあります。
概念レベルでは、これがメタデータで実際に行われていることです。
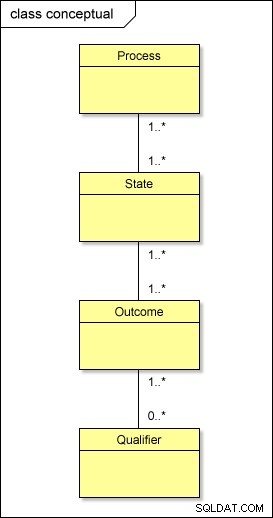
標準的なアプローチを使用してこのモデルを物理的な世界に変換する場合、PROCESS 、STATE 、OUTCOME 、およびQUALIFIER;また、中間テーブルが必要になります それらの間– PROCESS_STATE 、STATE_OUTCOME 、およびOUTCOME_QUALIFIER –多対多の関係を解決するため 。これは設計を複雑にします。
レベルの論理階層(プロセス→状態→結果→修飾子)を維持する必要がありますが、メタデータを物理的に整理するためのより簡単な方法があります。
ワークフローパターン
次の図は、ワークフローデータベースモデルの主なコンポーネントを定義しています。
左側の黄色のテーブルにはワークフローメタデータが含まれ、右側の青いテーブルにはビジネスデータが含まれています。
最初に指摘するのは、どのエンティティも管理できるということです。 このモデルに大きな変更を加える必要はありません。 YOUR_ENTITIY_TO_MANAGE テーブルはワークフロー管理下にあるものです。この例では、これはJOB_APPLICATION テーブル。
次に、wf_state_type_process_idを追加するだけです。 管理したいテーブルへの列。この列は、実際のワークフローのプロセスを示しています エンティティの管理に使用されています。これは厳密には外部キー列ではありませんが、WORKFLOW_STATE_TYPEをすばやくクエリできます。 正しいプロセスのために。 状態履歴を含むテーブル MANAGED_ENTITY_STATE 。ここでも、独自の特定のテーブル名を選択し、独自の要件に合わせて変更します。
メタデータ
ワークフローのさまざまなレベルは、WORKFLOW_LEVEL_TYPE 。このテーブルには、次のものが含まれています。
| タイプキー | 説明 |
|---|---|
| プロセス | 高レベルのワークフロープロセス。 |
| 状態 | プロセス中の状態。 |
| 結果 | 状態がどのように終了するか、その結果。 |
| QUALIFIER | 結果のオプションのより詳細な修飾子。 |
WORKFLOW_STATE_TYPE およびWORKFLOW_STATE_HIERARCHY 従来の部品表(BOM)構造を形成します 。この構造は、実際の製造部品表を非常によく表しており、データモデリングでは非常に一般的です。階層を定義したり、多くの再帰的な状況に適用したりできます。ここでは、これを利用して、プロセス、状態、結果、およびオプションの修飾子の論理階層を定義します。
階層を定義する前に、個々のコンポーネントを定義する必要があります。これらは私たちの基本的な構成要素です。これらをTYPE_KEYで参照します 簡潔にするために(これはユニークです)。この例では、次のようになります。
| ワークフローレベルタイプ | ワークフロー状態Type.Typeキー |
|---|---|
| 結果 | 合格 |
| 結果 | 失敗 |
| 結果 | 承認済み |
| 結果 | 拒否 |
| 結果 | CANDIDATE_CANCELLED |
| 結果 | EMPLOYER_CANCELLED |
| 結果 | 拒否されました |
| 結果 | EMPLOYER_WITHDRAWN |
| 結果 | NO_SHOW |
| 結果 | 採用 |
| 結果 | NOT_HIRED |
| 状態 | APPLICATION_RECEIVED |
| 状態 | APPLICATION_REVIEW |
| 状態 | INVITED_TO_INTERVIEW |
| 状態 | インタビュー |
| 状態 | TEST_APTITUDE |
| 状態 | SEEK_REFERENCES |
| 状態 | MAKE_OFFER |
| 状態 | APPLICATION_CLOSED |
| プロセス | STANDARD_JOB_APPLICATION |
| プロセス | TECHNICAL_JOB_APPLICATION |
これで、階層の定義を開始できます。ここで、ビルディングブロックを取得し、構造を定義します。州ごとに、考えられる結果を定義します。実際、このワークフローシステムのルールでは、各状態を終了する必要があります 結果:
| 親タイプ–状態 | 子タイプ–結果 |
|---|---|
| APPLICATION_RECEIVED | 承認済み |
| APPLICATION_RECEIVED | 拒否されました |
| APPLICATION_REVIEW | 合格 |
| APPLICATION_REVIEW | 失敗 |
| INVITED_TO_INTERVIEW | 承認済み |
| INVITED_TO_INTERVIEW | 拒否 |
| インタビュー | 合格 |
| インタビュー | 失敗 |
| インタビュー | CANDIDATE_CANCELLED |
| インタビュー | NO_SHOW |
| MAKE_OFFER | 承認済み |
| MAKE_OFFER | 拒否 |
| SEEK_REFERENCES | 合格 |
| SEEK_REFERENCES | 失敗 |
| APPLICATION_CLOSED | 採用 |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | 合格 |
| TEST_APTITUDE | 失敗 |
私たちのプロセスは、それぞれが一定期間存在する一連の状態にすぎません。以下の表では、論理的な順序で示されていますが、これは実際の処理順序を定義するものではありません。
| 親タイプ–プロセス | 子タイプ–状態 |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | インタビュー |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | インタビュー |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
BOM階層に関して重要なポイントがあります。物理的な部品表がアセンブリとサブアセンブリを最小のコンポーネントまで定義するのと同じように、階層内にも同様の配置があります。これは、「アセンブリ」と「サブアセンブリ」を再利用できることを意味します。
例として:両方のSTANDARD_JOB_APPLICATION およびTECHNICAL_JOB_APPLICATION プロセス INTERVIEWがあります 状態 。次に、INTERVIEW 状態 PASSEDがあります 、FAILED 、CANDIDATE_CANCELLED 、およびNO_SHOW 結果 そのために定義されています。
プロセスで状態を使用すると、それはすでにアセンブリであるため、子の結果を自動的に取得します。これは、INTERVIEWで両方のタイプの求人応募に同じ結果が存在することを意味します ステージ。さまざまなタイプの求人応募に対してさまざまな面接結果が必要な場合は、たとえば、TECHNICAL_INTERVIEWを定義する必要があります。 およびSTANDARD_INTERVIEW それぞれが独自の特定の結果をもたらすと述べています。
この例では、2種類の求人応募の唯一の違いは、技術的な求人応募には適性テストが含まれていることです。
行く前に
この2部構成の記事のパート1では、ワークフローデータベースパターンを紹介しました。これを組み込んで、データベース内の任意のエンティティのライフサイクルを管理する方法を示しました。
パート2では、実際のワークフローを定義する方法を紹介します。 追加の構成テーブルを使用します。これは、ユーザーに許容される次のステップが提示される場所です。また、BOMでの「アセンブリ」と「サブアセンブリ」の厳密な再利用を回避するための手法についても説明します。