データベースに参照テーブルがあることは大したことではありませんよね?コードまたはIDを各参照型の説明と関連付ける必要があります。しかし、文字通り何十もの参照テーブルがある場合はどうでしょうか。タイプごとに1つのテーブルのアプローチに代わるものはありますか? 一般的で拡張可能なを見つけるために読んでください すべての参照データを処理するためのデータベース設計。
この変わった外観の図は、エンタープライズシステムのすべての参照型を含む論理データモデル(LDM)の鳥瞰図です。教育機関からのものですが、あらゆる種類の組織のデータモデルに適用できます。モデルが大きいほど、より多くの参照型が明らかになる可能性があります。
参照型とは、参照データ、ルックアップ値、または–フラッシュしたい場合は–分類法を意味します 。通常、ここで定義された値は、アプリケーションのユーザーインターフェイスのドロップダウンリストで使用されます。レポートの見出しとして表示される場合もあります。
この特定のデータモデルには、約100の参照型がありました。ズームインして、そのうちの2つだけを見てみましょう。
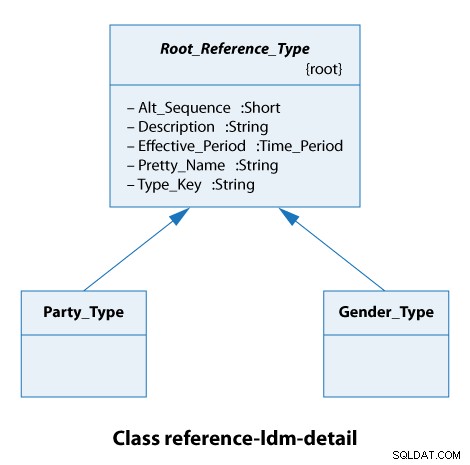
このクラス図から、すべての参照型がRoot_Reference_Type 。実際には、これは、すべての参照型がAlt_Sequenceからの同じ属性を持っていることを意味します Type_Keyまで 以下に示すように、包括的です。
| 属性 | 説明 |
|---|---|
Alt_Sequence | アルファベット以外の順序が必要な場合に代替シーケンスを定義するために使用されます。 |
Description | タイプの説明。 |
Effective_Period | 参照エントリを有効にするかどうかを効果的に定義します。参照が使用されると、参照の制約により削除できなくなります。無効にすることしかできません。 |
| タイプのきれいな名前。これは、ユーザーが画面に表示するものです。 |
Type_Key | タイプの一意の内部KEY。これはユーザーには表示されませんが、アプリケーション開発者はSQLでこれを広範囲に使用できます。 |
ここでのパーティーのタイプは、組織または個人のいずれかです。性別の種類は男性と女性です。したがって、これらは本当に単純なケースです。
従来の参照テーブルソリューション
では、実際のデータベースの物理的な世界に論理モデルをどのように実装するのでしょうか?
各参照型が独自のテーブルにマップされるという見方をすることができます。これを、より伝統的なクラスごとに1つのテーブルと呼ぶかもしれません。 解決。非常にシンプルで、次のようになります。
これの欠点は、これらのテーブルが数十から数十存在する可能性があり、すべてが同じ列を持ち、すべてが非常に同じことをしていることです。
さらに、さらに多くの開発作業を作成する可能性があります 。管理者が値を維持するために各タイプのUIが必要な場合、作業量は急速に増加します。これには厳格なルールはありません。実際には開発環境によって異なります。そのため、開発者と話し合う必要があります これがどのような影響を与えるかを理解するため。
しかし、すべての参照型が同じ属性または列を持っているとすると、論理データモデルを実装するためのより一般的な方法はありますか?はいあります!そして必要なのは2つのテーブルだけです 。
2テーブルソリューション
このテーマについて私が最初に話し合ったのは、90年代半ばにロンドンマーケットの保険会社で働いていたときでした。当時、私たちは物理的な設計に直行し、IDではなく自然/ビジネスキーを主に使用していました。参照データが存在する場合、一意のコード(VARCHAR PK)と説明で構成されるタイプごとに1つのテーブルを保持することにしました。実際、当時は参照テーブルがはるかに少なかったのです。多くの場合、制限されたビジネスコードのセットが列で使用され、データベースチェック制約が定義されている可能性があります。参照テーブルはまったくありません。
しかし、それ以来、ゲームは進んでいます。これが2つのテーブルによるソリューションです。 次のようになります:
ご覧のとおり、この物理データモデルは非常に単純です。しかし、それは論理モデルとはまったく異なります。何かがすべて洋ナシの形になっているからではありません。これは、物理設計の一環として多くのことが行われたためです。 。
reference_type 表は、LDMからの個々の参照クラスを表します。したがって、LDMに20の参照タイプがある場合、テーブルには20行のメタデータがあります。 reference_value 表には、すべての許容値が含まれています 参照型。
このプロジェクトの時点で、開発者の間で非常に活発な議論がありました。 2つのテーブルのソリューションを好む人もいれば、タイプごとに1つのテーブルを好む人もいます。 方法。
各ソリューションには長所と短所があります。ご想像のとおり、開発者は主にUIの作業量に関心を持っていました。各テーブルの管理UIを一緒にノックするのはかなり速いだろうと考える人もいました。他の人は、単一の管理UIを構築することはより複雑になるだろうと考えましたが、最終的には報われます。
この特定のプロジェクトでは、2つのテーブルのソリューションが支持されました。もっと詳しく見てみましょう。
拡張可能で柔軟な参照データパターン
データモデルは時間の経過とともに進化し、新しい参照型が必要になるため、新しい参照型ごとにデータベースに変更を加える必要はありません。新しい構成データを定義する必要があります。これを行うには、reference_type テーブルを作成し、許容値の制御されたリストをreference_value テーブル。
このソリューションに含まれる重要な概念は、有効期間の定義の概念です。 特定の値に対して。たとえば、組織が新しいreference_value 将来的に受け入れられる「IDの証明」のその新しいreference_value effective_period_fromで 日付が正しく設定されています。これは事前に行うことができます。 その日付が来るまで、新しいエントリは表示されません アプリケーションのユーザーに表示される値のドロップダウンリスト。これは、アプリケーションが現在の値または有効な値のみを表示するためです。
一方、ユーザーが特定のreference_value 。その場合は、effective_period_toで更新してください。 日付が正しく設定されています。その日が経過すると、値はドロップダウンリストに表示されなくなります。それ以降は無効になります。ただし、テーブル内の行として物理的に存在するため、参照整合性は維持されます すでに参照されているテーブルの場合。
2つのテーブルのソリューションに取り組んでいるので、reference_type テーブル。これらは主にUIの懸念に集中していました。
たとえば、pretty_name reference_type UIで使用するためにテーブルが追加されました。大規模な分類では、検索機能付きのウィンドウを使用すると便利です。次にpretty_name ウィンドウのタイトルに使用できます。
一方、値のドロップダウンリストで十分な場合は、pretty_name LOVプロンプトに使用できます。同様に、UIで説明を使用して、ロールオーバーヘルプにデータを入力することもできます。
これらのテーブルに含まれる構成またはメタデータのタイプを確認すると、状況を少し明確にするのに役立ちます。
すべてを管理する方法
ここで使用されている例は非常に単純ですが、大規模なプロジェクトの参照値はすぐに非常に複雑になる可能性があります。したがって、これらすべてをスプレッドシートに保持することをお勧めします。その場合は、スプレッドシート自体を使用して、文字列連結を使用してSQLを生成できます。これはスクリプトに貼り付けられ、開発ライフサイクルと本番(ライブ)データベースをサポートするターゲットデータベースに対して実行されます。これにより、必要なすべての参照データがデータベースにシードされます。
2つのLDMタイプ、Gender_Typeの構成データは次のとおりです。 およびParty_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
reference_type Root_Reference_TypeのLDMサブタイプごとに 。 reference_type LDMクラスの説明から取得されます。 Gender_Typeの場合 、これは「人の性別を識別します」と表示されます。 DMLスニペットは、UIまたはレポートで使用される可能性のあるタイプと値の説明の違いを示しています。
reference_type Gender_Typeと呼ばれます 関連するreference_value.idsに13000000〜13999999の範囲が割り当てられています 。このモデルでは、各reference_type 重複しない一意のIDの範囲が割り当てられます。これは必ずしも必要ではありませんが、関連する値IDをグループ化することができます。これは、別々のテーブルがある場合に得られるものを模倣したものです。持っているのはいいことですが、これにメリットがないと思われる場合は、それを省くことができます。
PDMに追加されたもう1つの列は、admin_roleです。 。その理由は次のとおりです。
管理者は誰ですか
一部の分類には、ほとんどまたはまったく影響を与えずに値を追加または削除できます。これは、プログラムがロジック内の値を使用しない場合、またはタイプが他のシステムにインターフェイスされていない場合に発生します。このような場合、ユーザー管理者はこれらを最新の状態に保つことが安全です。
しかし、他の場合には、もっと注意を払う必要があります。新しい参照値は、プログラムロジックまたはダウンストリームシステムに意図しない結果をもたらす可能性があります。
たとえば、性別タイプの分類法に次のように追加するとします。
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
次のロジックがどこかに組み込まれている場合、これはすぐに問題になります。
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
明らかに、「男性でない場合は女性でなければならない」という論理は、拡張分類法には適用されなくなりました。
ここでadmin_role コラムが登場します。これは、物理的な設計に関する開発者との話し合いから生まれ、UIソリューションと連携して機能しました。ただし、クラスごとに1つのテーブルが選択されている場合は、reference_type 存在しなかったでしょう。そこに含まれるメタデータは、アプリケーションGender_Type 表–、これは柔軟性も拡張性もありません。
適切な権限を持つユーザーのみが分類法を管理できます。 これは、主題の専門知識に基づいている可能性があります( SME )。一方、一部の分類法は、影響分析、徹底的なテスト、および新しい構成に間に合うようにコード変更を調和的にリリースできるようにするために、ITによって管理される必要がある場合があります。 (これが変更要求によって行われるか、その他の方法で行われるかは、組織次第です。)
監査列がcreated_byであることに気付いたかもしれません。 、created_date 、updated_by 、およびupdated_date 上記のスクリプトではまったく参照されていません。繰り返しますが、これらに興味がない場合は、使用する必要はありません。この特定の組織には、すべてのテーブルに監査列を設定することを義務付ける標準がありました。
トリガー:一貫性を保つ
トリガーは、SQLのソース(スクリプト、アプリケーション、スケジュールされたバッチ更新、アドホック更新など)に関係なく、これらの監査列が一貫して更新されることを保証します。
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
私の経歴は主にOracleですが、残念ながらOracleは識別子を30バイトに制限しています。これを超えないようにするために、各テーブルには3〜5文字の短いエイリアスが与えられ、他のテーブル関連のアーティファクトはそのエイリアスを名前に使用します。したがって、reference_value のエイリアスはreva –各単語の最初の2文字。 行挿入前 行の更新前はbriと省略されます およびbru それぞれ。シーケンス名reva_seq 、など。
このようなトリガーをテーブルごとに手動でコーディングするには、開発者にとって意気消沈する多くの定型文の作業が必要です。幸い、これらのトリガーはコード生成を介して作成できます 、しかしそれは別の記事の主題です!
キーの重要性
ref_type_key およびtype_key 列は両方とも30バイトに制限されています。これにより、PIVOTタイプのSQLクエリで使用できるようになります(Oracleの場合。他のデータベースには同じ識別子の長さの制限がない場合があります)。
キーの一意性はデータベースによって保証され、トリガーによってその値が常に同じであることが保証されるため、これらのキーをクエリやコードで使用して、読みやすくすることができます(使用する必要があります)。 。これはどういう意味ですか?代わりに:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
あなたが書く:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
基本的に、キーはクエリの実行内容を明確に示しています 。
LDMからPDMへ、成長の余地あり
LDMからPDMへの道のりは、必ずしもまっすぐな道ではありません。また、一方から他方への直接的な変換でもありません。これは、独自の考慮事項と独自の懸念事項を導入する別個のプロセスです。
データベース内の参照データをどのようにモデル化しますか?