インメモリOLTP(以前は「Hekaton」と呼ばれていた機能)と、それが非常に特殊で大量のワークロードにどのように役立つかについては、多くの議論がありました。別の会話の最中に、たまたまCREATE TYPEに何かがあることに気づきました。 より一般的なユースケースがあるかもしれないと私に思わせたSQLServer2014のドキュメント:

CREATETYPEドキュメントへの比較的静かで前例のない追加>
シンタックスダイアグラムに基づくと、テーブル値パラメーター(TVP)は、永続テーブルと同じようにメモリを最適化できるようです。そしてそれで、車輪はすぐに回り始めました。
私がTVPを使用したことの1つは、顧客がT-SQLまたはCLRで高価な文字列分割メソッドを排除できるようにすることです(ここ、ここ、およびここの以前の投稿の背景を参照してください)。私のテストでは、通常のTVPを使用すると、CLRまたはT-SQL分割関数を使用した同等のパターンを大幅に上回りました(25〜50%)。私は論理的に疑問に思いました:メモリ最適化されたTVPからパフォーマンスが向上するでしょうか?
インメモリOLTPについては、多くの制限と機能のギャップがあるため、一般的に懸念があります。メモリ最適化データ用に個別のファイルグループが必要であり、テーブル全体をメモリ最適化に移動する必要があります。通常、最大のメリットは次のとおりです。ネイティブにコンパイルされたストアドプロシージャ(独自の制限セットがあります)も作成することで実現されます。これから説明するように、テーブルタイプに単純なデータ構造(整数や文字列のセットを表すなど)が含まれていると仮定すると、このテクノロジーをTVPにのみ使用すると、一部が排除されます。 これらの問題の。
テスト
永続的なメモリ最適化テーブルを作成しない場合でも、メモリ最適化ファイルグループが必要になります。それでは、適切な構造を備えた新しいデータベースを作成しましょう。
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
これで、今日のように通常のテーブルタイプを作成でき、非クラスター化ハッシュインデックスとバケット数を空中に引き出したメモリ最適化テーブルタイプを作成できます(メモリ要件とバケット数の計算の詳細については、ここの現実の世界):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
メモリ最適化ファイルグループがないデータベースでこれを試行すると、通常のメモリ最適化テーブルを作成しようとした場合と同じように、このエラーメッセージが表示されます。
メッセージ41337、レベル16、状態0、行9MEMORY_OPTIMIZED_DATAファイルグループが存在しないか、空です。空でないMEMORY_OPTIMIZED_DATAファイルグループが1つあるまで、データベース用にメモリ最適化テーブルを作成することはできません。
通常の、メモリが最適化されていないテーブルに対してクエリをテストするために、SELECT INTOを使用して、AdventureWorks2012サンプルデータベースから新しいテーブルにデータをプルしました。 これらの厄介な制約、インデックス、拡張プロパティをすべて無視して、検索対象の列(ProductID)にクラスター化インデックスを作成しました。 ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
次に、4つのストアドプロシージャを作成しました。テーブルタイプごとに2つです。それぞれEXISTSを使用します およびJOIN アプローチ(私はEXISTSを好みますが、通常は両方を調べるのが好きです;後で、テストをEXISTSだけに制限したくない理由がわかります。 )。この場合、変数に任意の行を割り当てるだけなので、結果セットやその他の出力やオーバーヘッドを処理せずに、高い実行回数を観察できます。
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
次に、このタイプのテーブルに対して通常発生し、そもそもTVPまたは同様のパターンを必要とする種類のクエリをシミュレートする必要がありました。製品のリストを含むドロップダウンまたはチェックボックスのセットを備えたフォームを想像してください。ユーザーは、比較したい20、50、または200を選択し、リストします。値は、連続した適切なセットにはなりません。それらは通常、あちこちに散らばっています(予測可能な連続範囲の場合、クエリははるかに単純になります:開始値と終了値)。そこで、ランダムに並べた、テーブルから任意の20個の値を選択しました(たとえば、テーブルサイズの5%を下回ろうとしました)。再利用可能なVALUESを作成する簡単な方法 このような句は次のとおりです。
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; 結果(あなたの結果はほぼ確実に異なります):
(725)、(524)、(357)、(405)、(477)、(821)、(323)、(526)、(952)、(473)、(442)、(450)、(735) )、(441)、(409)、(454)、(780)、(966)、(988)、(512)、
直接のINSERT...SELECTとは異なります 、これにより、その出力を再利用可能なステートメントに操作して、TVPに同じ値を繰り返し入力し、テストを複数回繰り返すことが非常に簡単になります。
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
SQL Sentry Plan Explorerを使用してこのバッチを実行すると、結果のプランに大きな違いがあります。メモリ内TVPは、ネストされたループ結合と20の単一行クラスター化インデックスシークを使用できます。従来のTVPのクラスター化されたインデックススキャン。そしてこの場合、EXISTSとJOINは同じ計画を生み出しました。これは、値の数がはるかに多い場合に役立つ可能性がありますが、値の数がテーブルサイズの5%未満になると仮定して続行しましょう:
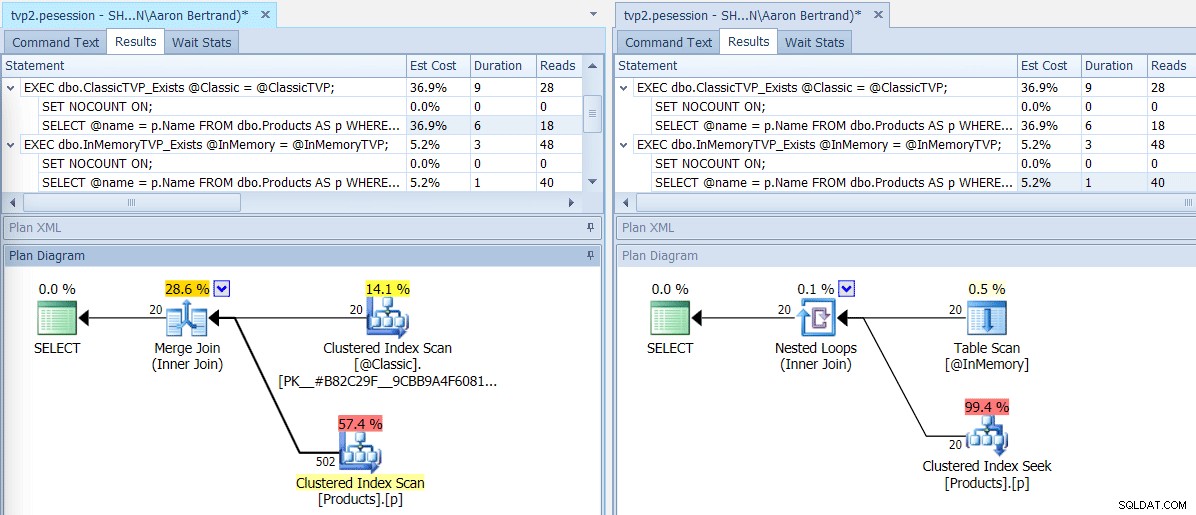
 スキャン/シーク演算子のツールチップ、主な違いを強調表示–左側のクラシック、In-右側のメモリ
スキャン/シーク演算子のツールチップ、主な違いを強調表示–左側のクラシック、In-右側のメモリ
さて、これは大規模に何を意味するのでしょうか? showplanコレクションをオフにし、テストスクリプトを少し変更して、各プロシージャを100,000回実行し、累積ランタイムを手動でキャプチャします。
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
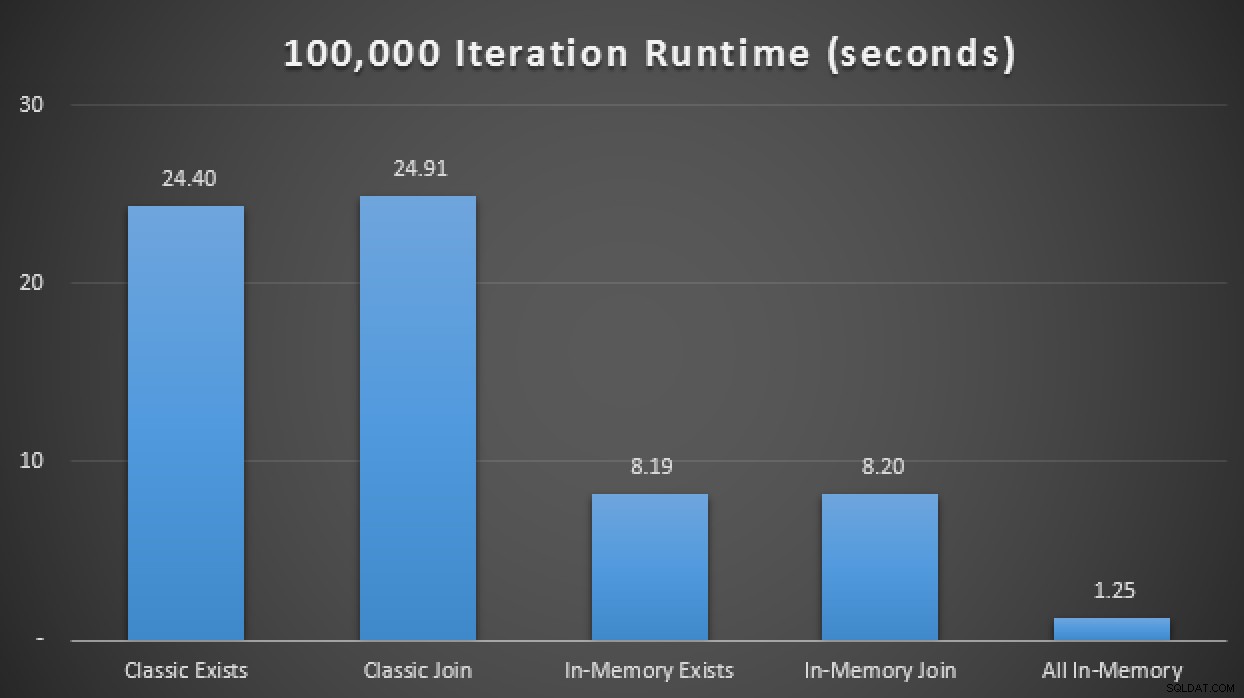
SELECT SYSDATETIME(); 結果では、10回の実行で平均すると、少なくともこの限られたテストケースでは、メモリ最適化テーブルタイプを使用すると、OLTP(実行時間)でおそらく最も重要なパフォーマンスメトリックが約3倍向上したことがわかります。
>
実行時の結果はインメモリTVPで3倍の改善を示しています
インメモリ+インメモリ+インメモリ:インメモリインセプション
通常のテーブルタイプをメモリ最適化テーブルタイプに変更するだけで何ができるかを確認したので、3つの要素であるメモリ内を適用したときに、この同じクエリパターンからパフォーマンスをさらに引き出すことができるかどうかを見てみましょう。テーブル。ネイティブにコンパイルされたメモリ最適化ストアドプロシージャを使用します。これは、メモリ内のテーブルテーブルをテーブル値パラメータとして受け入れます。
まず、テーブルの新しいコピーを作成し、作成済みのローカルテーブルからデータを入力する必要があります。
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
次に、既存のメモリ最適化テーブルタイプをTVPとして使用するネイティブにコンパイルされたストアドプロシージャを作成します。
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO 注意点がいくつかあります。ネイティブにコンパイルされたストアドプロシージャのパラメータとして、通常のメモリ最適化されていないテーブルタイプを使用することはできません。試してみると、次のようになります。
メッセージ41323、レベル16、状態1、プロシージャInMemoryProcedureテーブルタイプ'dbo.ClassicTVP'はメモリ最適化テーブルタイプではないため、ネイティブにコンパイルされたストアドプロシージャでは使用できません。
また、EXISTSは使用できません ここでもパターン。試してみると、次のようになります。
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
インメモリOLTPとネイティブにコンパイルされたストアドプロシージャには、他にも多くの注意事項と制限があります。テストから明らかに欠落していると思われるいくつかのことを共有したいと思います。
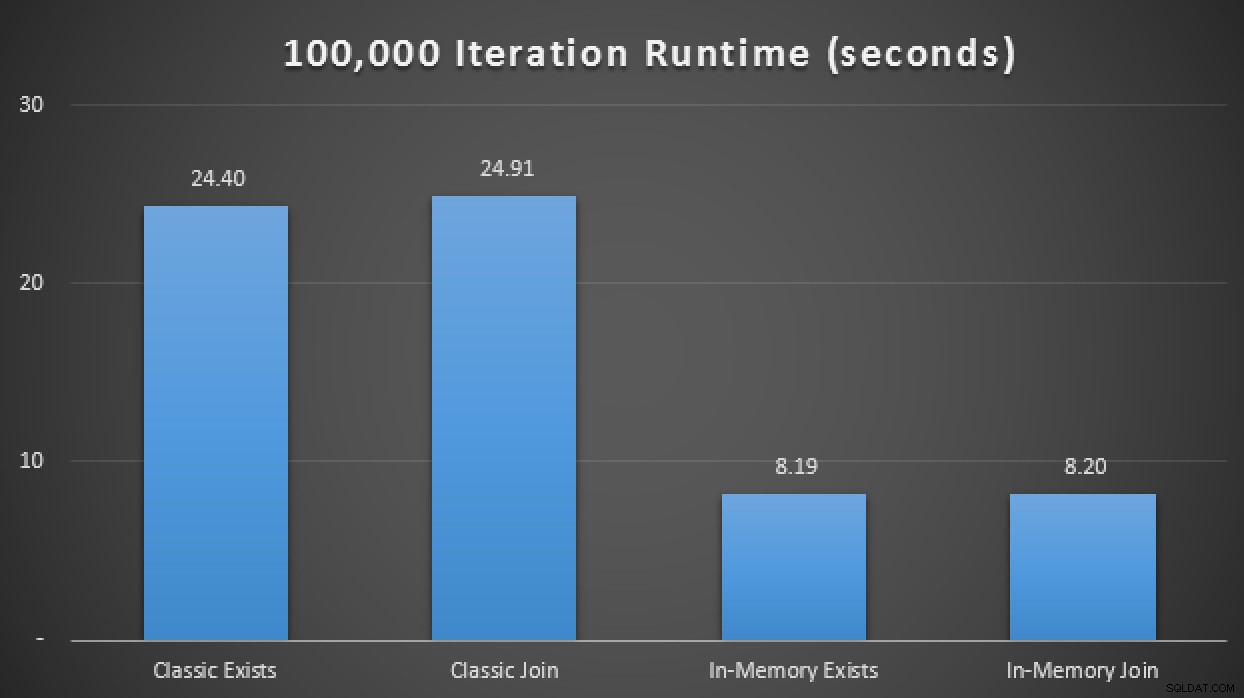
したがって、この新しいネイティブにコンパイルされたストアドプロシージャを上記のテストマトリックスに追加すると、平均して10回の実行で、わずか1.25秒で100,000回の反復が実行されることがわかりました。これは、通常のTVPの約20倍の改善と、従来のテーブルと手順を使用したインメモリTVPの6〜7倍の改善に相当します。
実行時の結果は、インメモリ全体で最大20倍の改善を示しています
結論
現在TVPを使用している場合、またはTVPに置き換えることができるパターンを使用している場合は、テスト計画にメモリ最適化TVPを追加することを絶対に検討する必要がありますが、シナリオで同じ改善が見られない場合があることに注意してください。 (もちろん、TVPには一般に多くの警告と制限があり、すべてのシナリオに適しているわけではないことを覚えておいてください。ErlandSommarskogには、今日のTVPに関するすばらしい記事があります。)
実際、ボリュームと同時実行性の下限では違いがないことがわかるかもしれませんが、現実的な規模でテストしてください。これは、単一のSSDを搭載した最新のラップトップでの非常に単純で工夫されたテストでしたが、実際のボリュームやとげのあるメカニカルディスクについて話している場合、これらのパフォーマンス特性ははるかに重要になる可能性があります。より大きなデータサイズに関するいくつかのデモンストレーションを伴うフォローアップがあります。