SQL Serverのパフォーマンスチューニングに関する議論で出てくる最も一般的な用語の1つは、統計の待機です。 。これは、この2006年のMicrosoftドキュメント「SQLServer2005の待機とキュー」の前でさえもはるかに遡ります。
待機は絶対にすべてではありません。この方法は、インスタンスを調整する唯一の方法ではありません。個々のクエリを気にする必要はありません。実際、待機は、苦しんでいるクエリだけで、周囲のコンテキストがない場合、特に事後ずっと、役に立たないことがよくあります。これは、多くの場合、クエリが待機しているのはそのクエリのせいではないためです。 。何でもそうですが、例外はありますが、この非常に特殊な機能を提供するという理由だけでツールやスクリプトを選択する場合は、自分自身が不利益を被っていると思います。私はポール・ランダルが少し前に私にくれたアドバイスに従う傾向があります:
…一般的には、インスタンス全体の待機から始めることをお勧めします。 開始したことはありません 個々のクエリ待機を調べてトラブルシューティングします。
場合によっては、はい、個々のクエリをさらに深く掘り下げて、それが何を待っているかを確認したい場合があります。実際、Microsoftは最近、この分析を支援するためにshowplanにクエリレベルの待機統計を追加しました。ただし、これらの数値は、ワークロード全体にも影響を及ぼしていることを指摘するのに役立つ場合を除いて、通常、インスタンス全体のパフォーマンスを調整するのに役立ちません。昨日から5分間実行されたクエリがあり、その待機タイプがLCK_M_Sであることがわかります。 、あなたは今それについて何をするつもりですか?実際にクエリをブロックし、その待機タイプを引き起こした原因をどのように追跡しますか?他の理由でコミットされなかったトランザクションが原因である可能性がありますが、システム全体の状態を確認できず、個々のクエリとそれらが経験した待機だけに焦点を当てている場合はわかりません。
Jason Hall(@SQLSaurus)は、私にとっても興味深いことについて言及しました。彼は、クエリレベルの待機統計がチューニング作業の非常に重要な部分である場合、この方法論は最初からクエリストアに組み込まれていると述べました。最近追加されました(SQL Server 2017で)。ただし、実行ごとの待機統計は取得されません。 DMVに表示されるクエリ統計やプロシージャ統計のように、時間の経過に伴う平均を取得します。そのため、クエリの実行ごとにキャプチャされた他の指標に基づいて突然の異常が明らかになる可能性がありますが、すべてにわたって引き出された待機時間の平均には基づいていません。 死刑執行。待機の範囲をカスタマイズして集約することもできますが、ビジー状態のシステムでは、これでも、自分がやろうと思っていることを実行するのに十分な粒度ではない可能性があります。
この投稿のポイントは、顧客ベースで見られるより一般的な待機タイプのいくつかと、それらが発生したときに実行できる(実行すべきではない)アクションの種類について説明することです。 Cloud Syncのお客様からかなり長い間収集してきた匿名の待機統計のデータベースがあり、2017年5月以降、SQLskillsWaitsLibraryでこれらがどのように表示されるかをすべての人に示しています。
ポールは、図書館の背後にある理由と、この無料サービスとの統合について話します。基本的に、あなたはあなたが経験している、または興味を持っている待機タイプを調べ、彼はそれが何を意味し、あなたがそれについて何ができるかを説明します。この定性的な情報を、現在の待機がユーザーベースでどれほど普及しているかを示すグラフで補足し、他のすべての待機タイプと比較して、一般的な待機タイプか、もう少し何かを扱っているかをすばやく判断できるようにします。エキゾチック。 (SQL Sentryには、ノイズに相当する良性、バックグラウンド、およびキュー待機が含まれておらず、WAITFORやLAZYWRITER_SLEEPなど、そこにあるほとんどのスクリプトがフィルターで除外されることに注意してください。これらはパフォーマンスの問題の原因ではありません。)
CXPACKETのグラフの例を次に示します。 、最も一般的な待機タイプ:
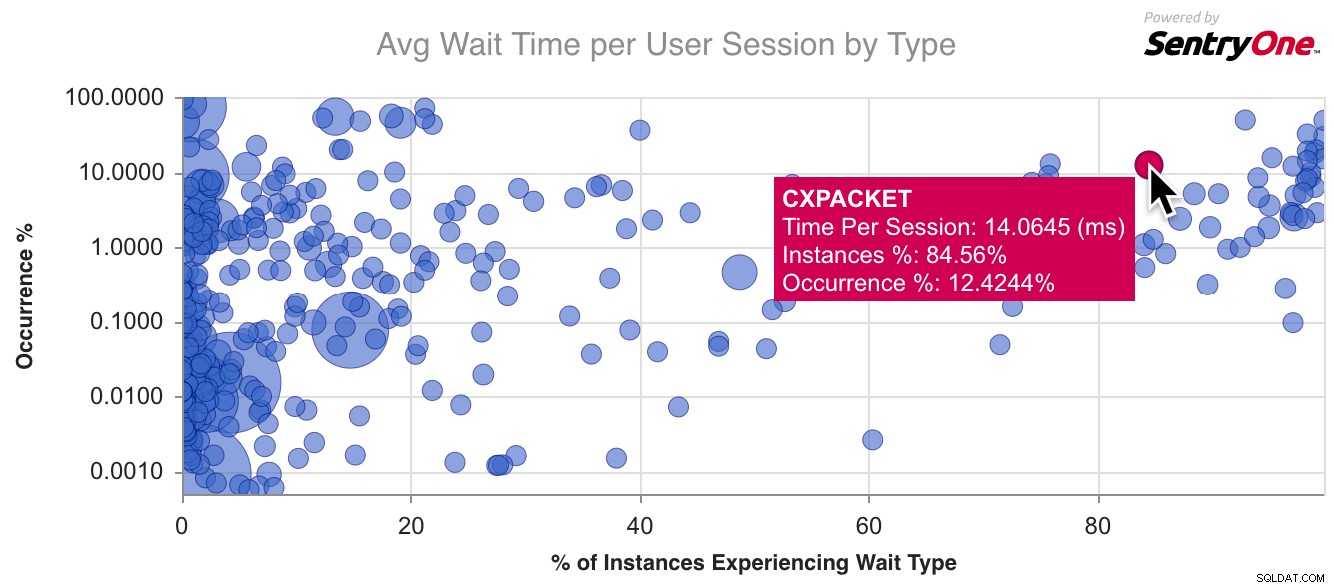
私はこれより少し先に進み、より一般的な待機タイプのいくつかをマッピングし、それらが共有するプロパティのいくつかに注目し始めました。チューナーが経験している待機タイプについての質問に変換されます:
- 待機タイプはクエリレベルで解決できますか?
- 待機の主な症状は他のクエリに影響を与える可能性がありますか?
- 問題を「解決」するために、単一のクエリとそれが経験した待機タイプのコンテキスト外で、より多くの情報が必要になる可能性がありますか?
この投稿を書き始めたときの私の目標は、最も一般的な待機タイプをグループ化してから、上記の質問に関連するメモを書き始めることでした。ジェイソンは最も一般的なものを図書館から引き出し、それから私はホワイトボードにいくつかのチキンスクラッチを描きました。それは後で少し片付けました。この最初の調査は、ジェイソンがアラスカでの最新のTechOutboundSQLCruiseについて行った講演につながりました。私がこの投稿を終える数ヶ月前に彼が話をまとめてくれたのはちょっと恥ずかしいので、それを続けましょう。これが私たちが見るトップウェイト(2014年のポールの調査とほぼ一致します)、上記の質問に対する私の答え、そしてそれぞれについてのいくつかの解説です:
下の表のリンクを操作するには、より広い画面でこのページにアクセスしてください。
| |
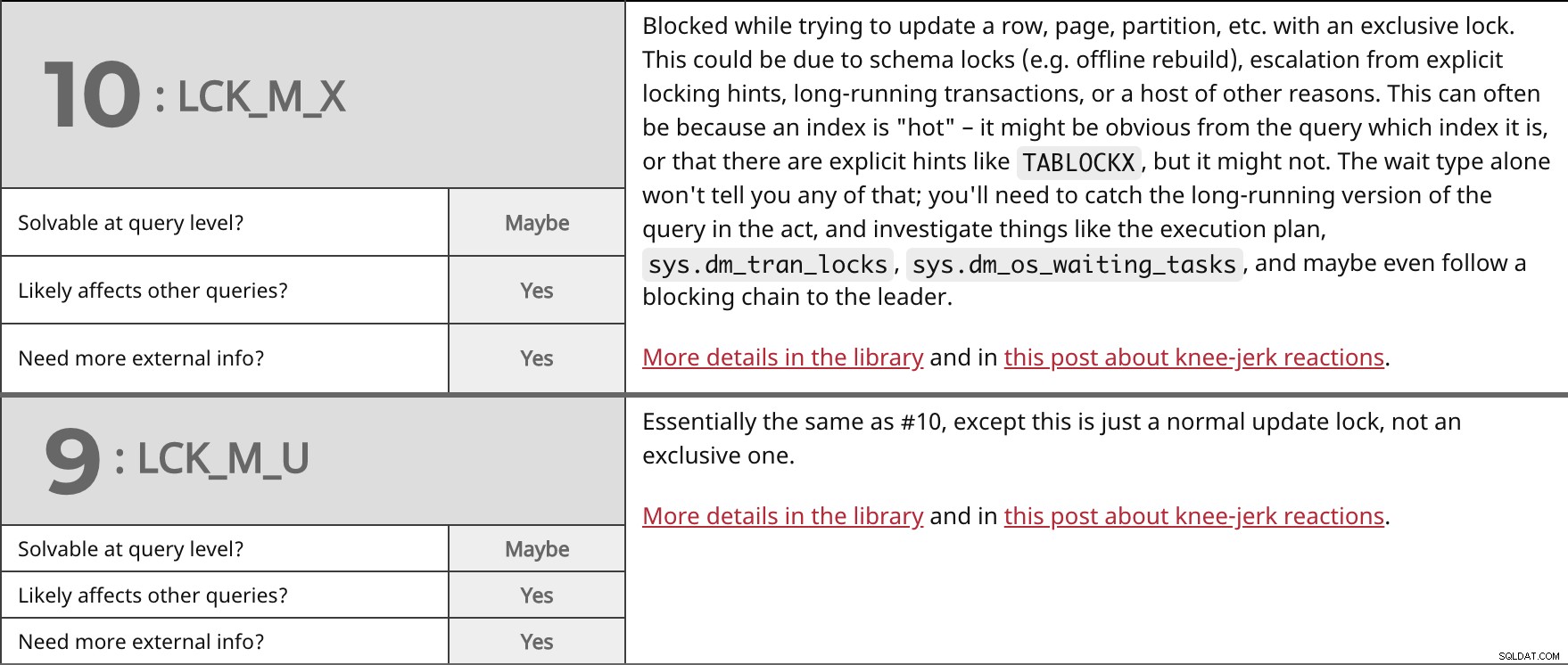
行、ページ、パーティションなどを排他ロックで更新しようとしているときにブロックされました。これは、スキーマロック(オフライン再構築など)、明示的なロックヒントからのエスカレーション、長時間実行されるトランザクション、またはその他の多くの理由が原因である可能性があります。これは多くの場合、インデックスが「ホット」であることが原因である可能性があります。クエリから、インデックスがどのインデックスであるか、またはTABLOCKXのような明示的なヒントがあることが明らかな場合があります。 、しかしそうではないかもしれません。待機タイプだけでは、そのことはわかりません。実行中のクエリの実行時間の長いバージョンをキャッチし、実行プラン、sys.dm_tran_locksなどを調査する必要があります。 、sys.dm_os_waiting_tasks 、そしておそらくリーダーへのブロッキングチェーンをたどることさえあります。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
|---|---|---|
| クエリレベルで解決可能ですか? | たぶん | |
| | はい | |
| さらに外部情報が必要ですか? | はい | |
| |
基本的に#10と同じですが、これは単なる通常の更新ロックであり、排他的なものではありません。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | はい | |
| さらに外部情報が必要ですか? | はい | |
| |
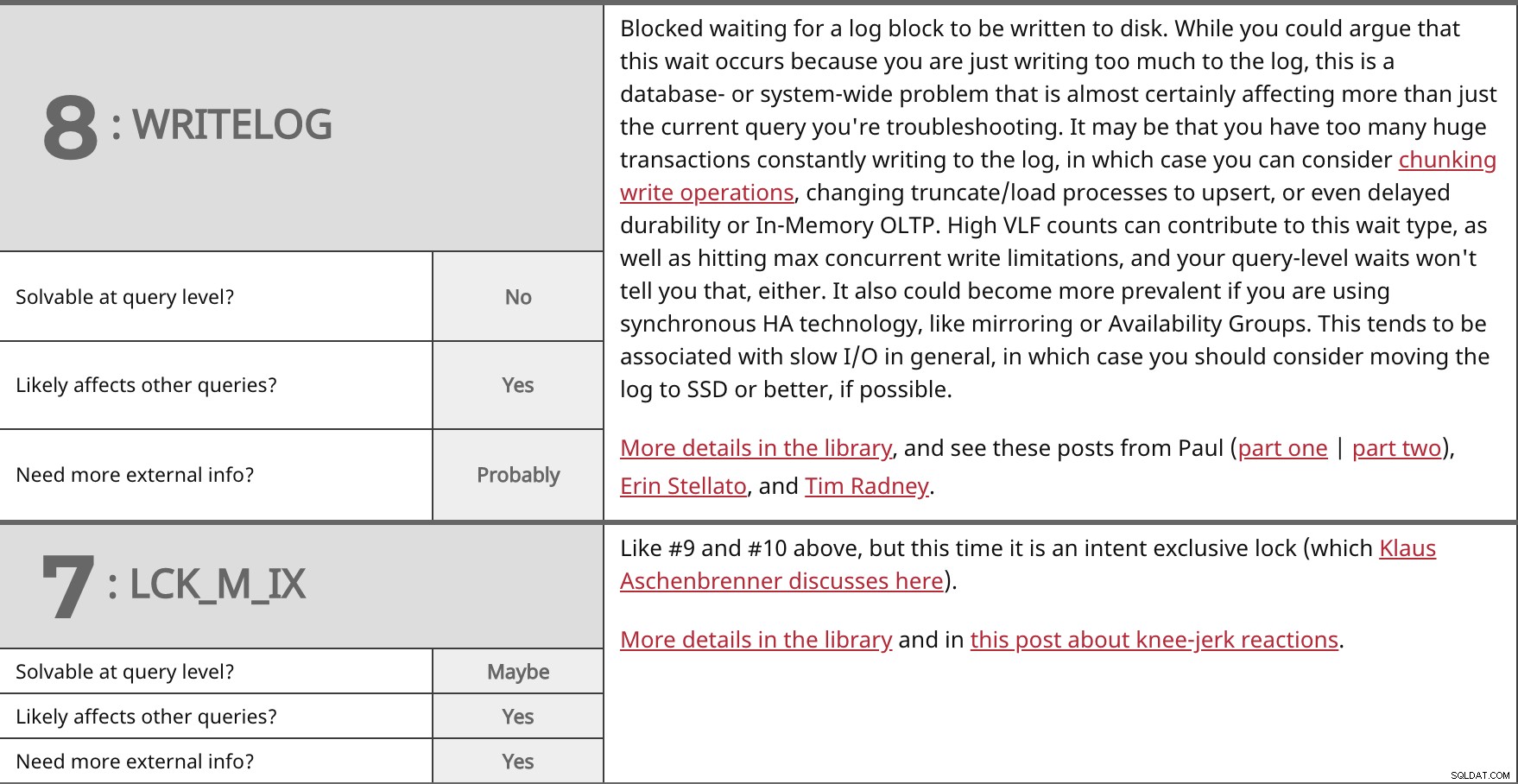
ログブロックがディスクに書き込まれるのを待ってブロックされました。ログへの書き込みが多すぎるためにこの待機が発生すると主張することもできますが、これはデータベース全体またはシステム全体の問題であり、トラブルシューティングしている現在のクエリ以外にもほぼ確実に影響を及ぼします。ログに絶えず書き込む巨大なトランザクションが多すぎる可能性があります。その場合は、書き込み操作のチャンク化、切り捨て/ロードプロセスのアップサートへの変更、または耐久性やインメモリOLTPの遅延を検討できます。 VLFカウントが高いと、この待機タイプが発生するだけでなく、同時書き込みの最大制限に達する可能性があります。クエリレベルの待機でも、そのことはわかりません。また、ミラーリングや可用性グループなどの同期HAテクノロジーを使用している場合は、さらに普及する可能性があります。これは一般にI/Oが遅いことに関連する傾向があります。その場合、可能であれば、ログをSSD以上に移動することを検討する必要があります。 ライブラリの詳細については、Paul(パート1 |パート2)、Erin Stellato、TimRadneyからのこれらの投稿を参照してください。 | |
| クエリレベルで解決可能ですか? | いいえ | |
| | はい | |
| さらに外部情報が必要ですか? | おそらく | |
| |
上記の#9および#10と同様ですが、今回はインテント専用ロックです(Klaus Aschenbrennerがここで説明します)。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | はい | |
| さらに外部情報が必要ですか? | はい | |
| |
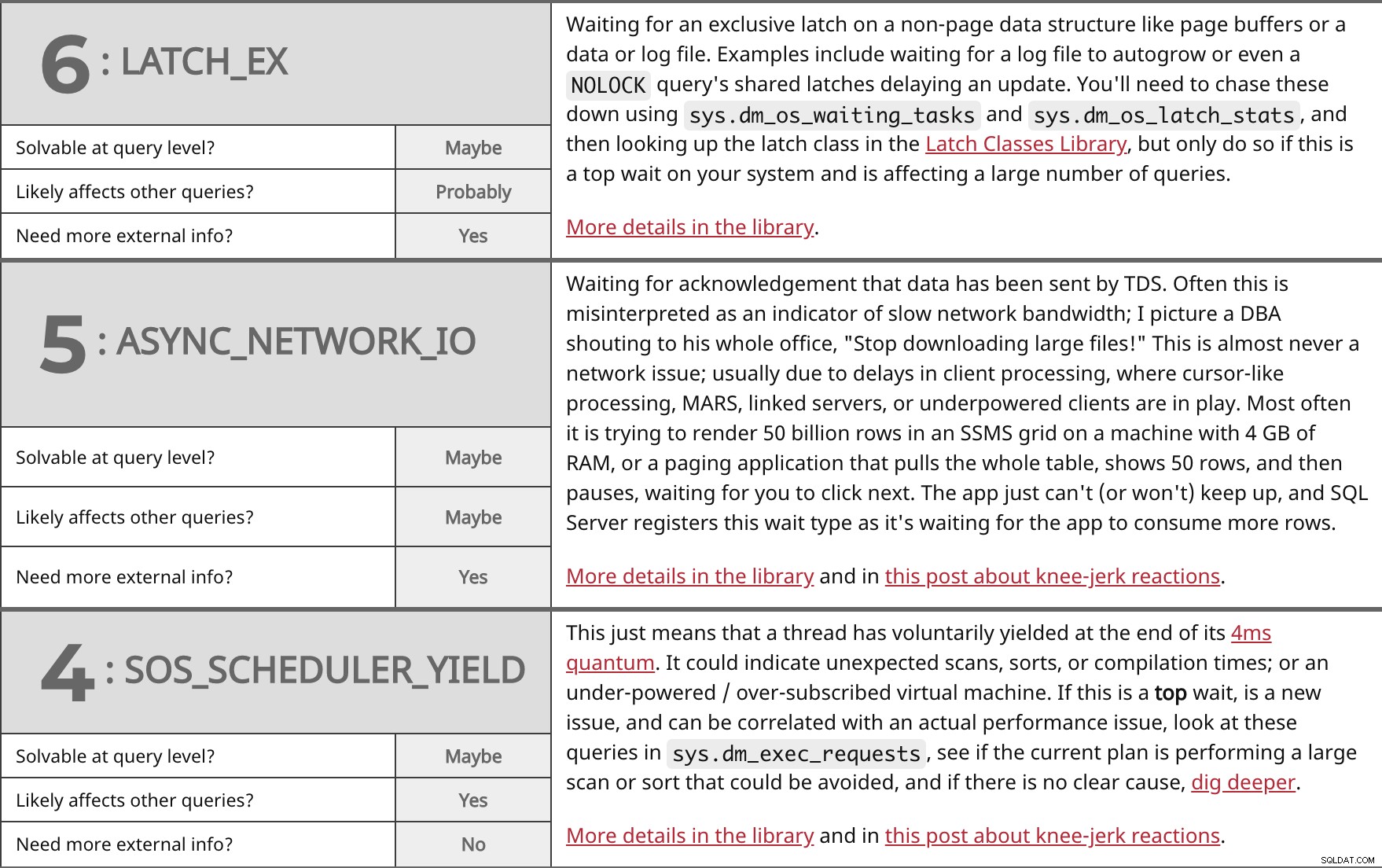
ページバッファやデータまたはログファイルなどの非ページデータ構造での排他的ラッチを待機しています。たとえば、ログファイルが自動拡張されるのを待つことや、NOLOCKを待つこともあります。 更新を遅らせるクエリの共有ラッチ。 sys.dm_os_waiting_tasksを使用してこれらを追跡する必要があります およびsys.dm_os_latch_stats 、次にラッチクラスライブラリでラッチクラスを検索しますが、これがシステムの最上位の待機であり、多数のクエリに影響を与えている場合にのみ実行してください。 ライブラリの詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | おそらく | |
| さらに外部情報が必要ですか? | はい | |
| |
データがTDSによって送信されたことの確認応答を待機しています。多くの場合、これはネットワーク帯域幅が遅いことを示すものと誤解されます。 DBAがオフィス全体に「大きなファイルのダウンロードをやめろ!」と叫んでいるのを想像します。これがネットワークの問題になることはほとんどありません。通常、カーソルのような処理、MARS、リンクされたサーバー、またはパワー不足のクライアントが機能しているクライアント処理の遅延が原因です。ほとんどの場合、4 GBのRAMを搭載したマシンのSSMSグリッドで500億行をレンダリングしようとしている、またはテーブル全体をプルして50行を表示してから一時停止し、[次へ]をクリックするのを待つページングアプリケーションです。アプリは追いつくことができない(または追いつかない)ため、SQL Serverは、アプリがより多くの行を消費するのを待機しているため、この待機タイプを登録します。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | たぶん | |
| さらに外部情報が必要ですか? | はい | |
| |
これは、スレッドが4msの量子の終わりに自発的に降伏したことを意味します。予期しないスキャン、ソート、またはコンパイル時間を示している可能性があります。または、パワー不足/サブスクライブ過剰の仮想マシン。これがトップの場合 待機します。これは新しい問題であり、実際のパフォーマンスの問題と関連付けることができます。sys.dm_exec_requestsでこれらのクエリを確認してください。 、現在の計画で回避できる大規模なスキャンまたは並べ替えが実行されているかどうかを確認し、明確な原因がない場合は、さらに深く掘り下げます。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | はい | |
| さらに外部情報が必要ですか? | いいえ | |
| |
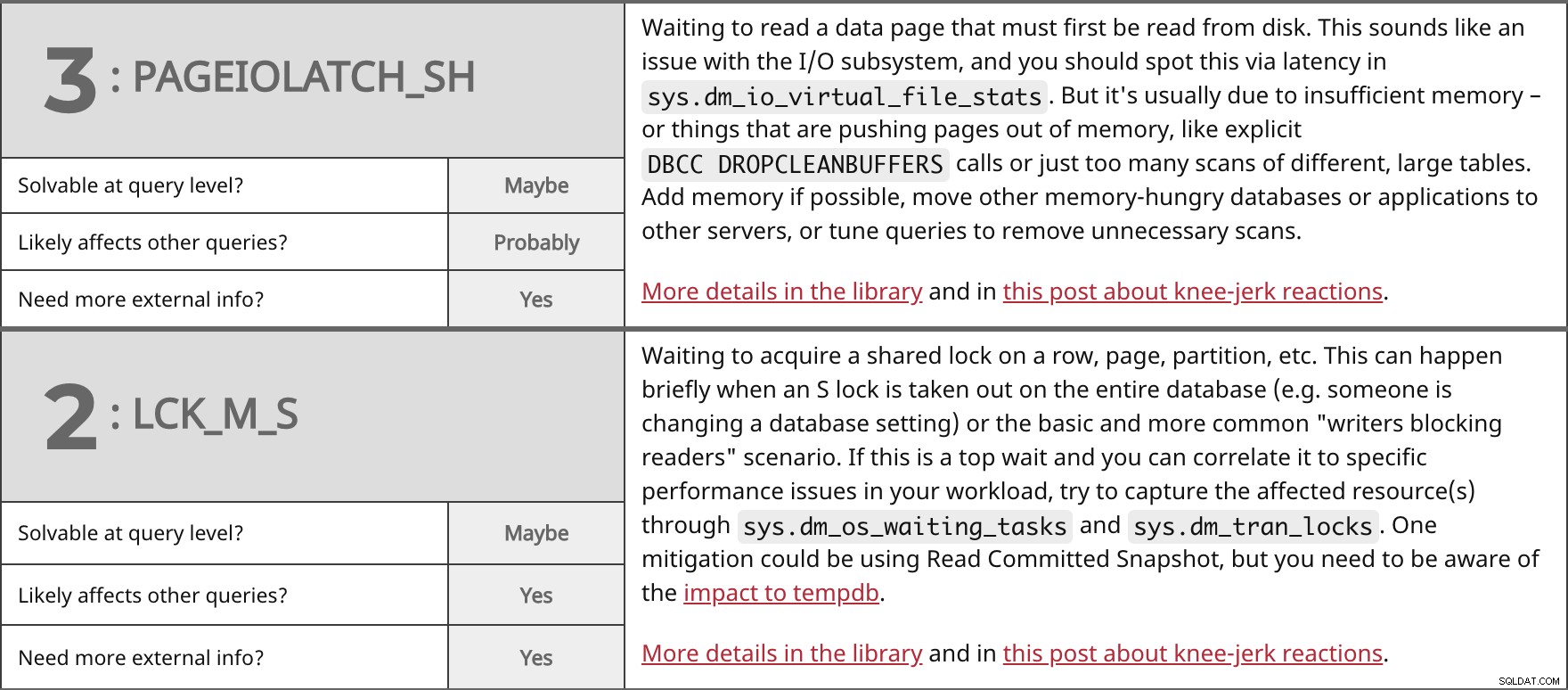
最初にディスクから読み取る必要があるデータページの読み取りを待機しています。これはI/Oサブシステムの問題のように聞こえます。これは、sys.dm_io_virtual_file_statsのレイテンシーを介して特定する必要があります。 。ただし、これは通常、メモリ不足、または明示的なDBCC DROPCLEANBUFFERSなどのページをメモリから押し出していることが原因です。 呼び出し、または異なる大きなテーブルのスキャンが多すぎます。可能であればメモリを追加するか、メモリを大量に消費する他のデータベースまたはアプリケーションを他のサーバーに移動するか、クエリを調整して不要なスキャンを削除します。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | おそらく | |
| さらに外部情報が必要ですか? | はい | |
| |
行、ページ、パーティションなどの共有ロックの取得を待機しています。これは、データベース全体でSロックが解除されたときに一時的に発生する可能性があります(たとえば、誰かが変更しているデータベース設定)または基本的でより一般的な「ライターがリーダーをブロックする」シナリオ。これがトップウェイトであり、ワークロードの特定のパフォーマンスの問題に関連付けることができる場合は、sys.dm_os_waiting_tasksを介して影響を受けるリソースをキャプチャしてみてください。 およびsys.dm_tran_locks 。軽減策の1つは、コミットされたスナップショットの読み取りを使用することですが、tempdbへの影響に注意する必要があります。 ライブラリとこの投稿のニージャーク反応に関する詳細。 | |
| クエリレベルで解決可能ですか? | たぶん | |
| | はい | |
| さらに外部情報が必要ですか? | はい | |
| |
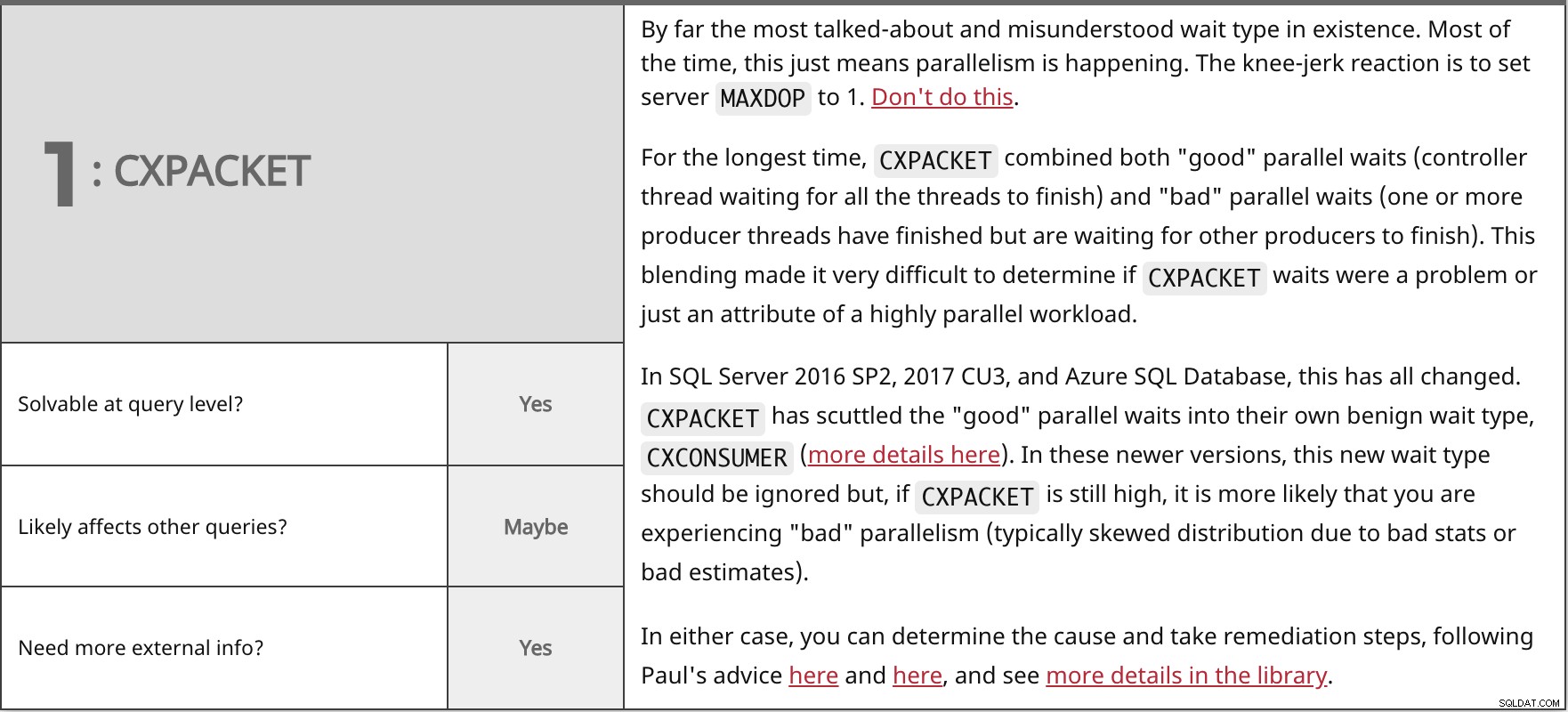
これまでで最も話題になり誤解されていた待機タイプ。ほとんどの場合、これは並列処理が行われていることを意味します。ひざまずく反応は、サーバーMAXDOPを設定することです に1。これをしないでください。
最長の場合、
SQL Server 2016 SP2、2017 CU3、およびAzure SQL Databaseでは、これがすべて変更されています。 いずれの場合も、こことここでPaulのアドバイスに従って、原因を特定して修正手順を実行し、ライブラリで詳細を確認できます。 | |
| クエリレベルで解決可能ですか? | はい | |
| | たぶん | |
| さらに外部情報が必要ですか? | はい | |
概要
これらのほとんどの場合、インスタンスレベルで待機を確認し、待機の種類に関係なくパフォーマンスの問題を示す特定のクエリのトラブルシューティングを行う場合にのみ、クエリレベルの待機に焦点を当てることをお勧めします。これらは、長時間、高いCPU、高いI / Oなど、他の理由で表面化するものであり、単純なもの(シークを期待していたときのクラスター化されたインデックススキャンなど)では説明できません。
インスタンスレベルでも、システムの最上位の待機になるすべての待機を追跡しないでください。常に トップウェイトを持っていれば、それを追いかけるのを止めることはできません。良性の待機を無視し(Paulはリストを保持します)、発生している実際のパフォーマンスの問題に関連付けることができる待機についてのみ心配するようにしてください。 CXPACKETの場合 待ち時間が長いので、何ですか?その数が「高い」か、たまたまリストの一番上にあること以外に、他の症状はありますか?
そもそもトラブルシューティングをしている理由がすべてです。単一のユーザーが不正なクエリの単一のインスタンスについて不平を言っていますか?サーバーはひざまずいていますか?間に何か?最初のケースでは、確かに、クエリが遅い理由を知ることは有用ですが、すべてのクエリに関連するすべての待機を、1日中、毎日、奇妙な機会に追跡するのは非常にコストがかかります。戻ってきて後で確認したい。それがそのクエリに限定された広範な問題である場合は、クエリを再度実行し、実行プラン、コンパイル時間、およびその他の実行時メトリックを収集することで、そのクエリを遅くしている原因を特定できるはずです。先週の火曜日に1回だけ発生した場合は、クエリのその単一のインスタンスを待機しているかどうかに関係なく、コンテキストがないと問題を解決できない可能性があります。ブロッキングがあったかもしれませんが、何が原因かわからないか、I / Oスパイクがあったかもしれませんが、その問題を個別に追跡する必要があります。待機タイプ自体は通常、せいぜい他の何かへのポインタを除いて、十分な情報を提供しません。
もちろん、ここでもキープを稼ぐ必要があります。当社の主力製品であるSQLSentryは、監視に全体的なアプローチを採用しています。インスタンス全体の待機統計を収集し、分類して、ダッシュボードにグラフ化します。
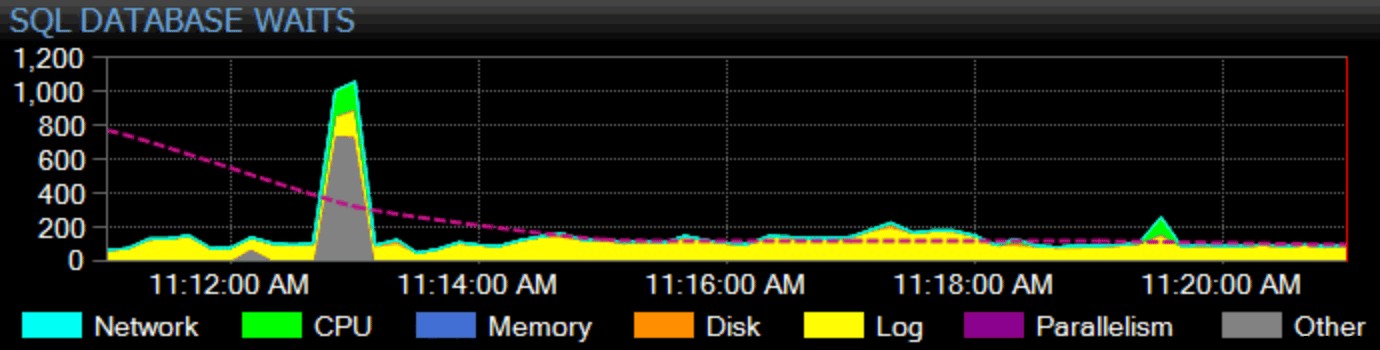
個々の待機の分類方法と、そのカテゴリがダッシュボードに表示されるかどうかをカスタマイズできます。現在の待機統計を組み込みまたはカスタムのベースラインと比較でき、ベースラインからの定義された偏差を超えたときにアラートまたはアクションを設定することもできます。そして、おそらく最も重要なのは、過去のデータポイントを確認し、ダッシュボード全体をその時点に同期できるため、周囲のすべてのコンテキストや、問題に影響を与えた可能性のあるその他の状況をキャプチャできることです。ブロッキング、ディスクレイテンシの高さ、I / Oが高い、または継続時間が長いクエリなど、焦点を当てるべきより詳細なものを見つけた場合、それらのメトリックにドリルダウンして、問題の根本にかなり早く到達できます。
一般的な待機統計アプローチと具体的なソリューションの両方の詳細については、KevinKlineのホワイトペーパー「SQLServer待機統計のトラブルシューティング」を参照してください。PaulRandal、Andy Yun(@SQLBek)が提供する2部構成のウェビナーをダウンロードできます。 Andy Mallon(@AMtwo):
- パート1:待機統計を使用したパフォーマンスのトラブルシューティング
- パート2:SentryOneを使用した待機統計の迅速な分析
また、SentryOneプラットフォームを試してみたい場合は、期間限定のオファーでここから始めることができます:
15日間の無料トライアルをダウンロードする