日時の値から時間を取り除く最も一般的な必要性は、特定の日に発生した注文(または訪問、事故)を表すすべての行を取得することです。ただし、そのために使用されるすべての手法が効率的または安全であるとは限りません。
TL;DRバージョン
良好に機能する安全範囲クエリが必要な場合は、制限のない範囲を使用するか、SQL Server 2008以降での1日のクエリの場合は、CONVERT(DATE)を使用します。 :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
いくつかの注意事項:
-
DATEDIFFに注意してください 発生する可能性のあるカーディナリティ推定の異常があるため、アプローチします(詳細については、このブログ投稿と、それに拍車をかけたスタックオーバーフローの質問を参照してください)。 - 最後のものはまだインデックスシークを使用する可能性がありますが(これまでに出くわした他のすべての非引数式とは異なり)、比較する前に列を日付に変換することに注意する必要があります。このアプローチも、根本的に間違ったカーディナリティ推定をもたらす可能性があります。詳細については、MartinSmithによるこの回答を参照してください。
いずれにせよ、私がこれまでに推奨した2つのアプローチがこれらだけである理由を理解するために読んでください。
すべてのアプローチが安全というわけではありません
安全でない例として、これはよく使われているようです:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);の間のOrderDate
このアプローチにはいくつかの問題がありますが、最も注目すべき問題は、基になるデータ型がSMALLDATETIMEの場合、今日の「終了」の計算です。 、その終了範囲は切り上げられます。 DATETIME2の場合 、理論的には1日の終わりにデータを見逃す可能性があります。現在のデータ型に対応するために分またはナノ秒またはその他のギャップを選択した場合、データ型が後で変更された場合、クエリは奇妙な動作を開始します(正直なところ、誰かがその列の型を多かれ少なかれ細かく変更した場合、それらは、それにアクセスするすべてのクエリをチェックすることを実行していません)。基になる列の日付/時刻データのタイプに応じてこのようにコーディングする必要があると、断片化され、エラーが発生しやすくなります。これには、制限のない日付範囲を使用することをお勧めします:
これについては、いくつかの古いブログ投稿で詳しく説明しています:
- 悪魔と悪魔の共通点は何ですか?
- キックする悪い習慣:日付/範囲クエリの誤った処理
しかし、私はそこにあるより一般的なアプローチのいくつかのパフォーマンスを比較したかったのです。私は常に制限のない範囲を使用してきましたが、SQL Server 2008以降、CONVERT(DATE)を使用できるようになりました。 それでも、その列のインデックスを利用します。これは非常に強力です。
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
簡単なパフォーマンステスト
非常に簡単な初期パフォーマンステストを実行するために、上記の各ステートメントに対して次のことを行い、計算の出力に変数を100,000回設定しました。
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
これをメソッドごとに3回実行しましたが、すべて34〜38秒の範囲で実行されました。厳密に言えば、メモリ内で操作を実行する場合、これらの方法にはごくわずかな違いがあります。
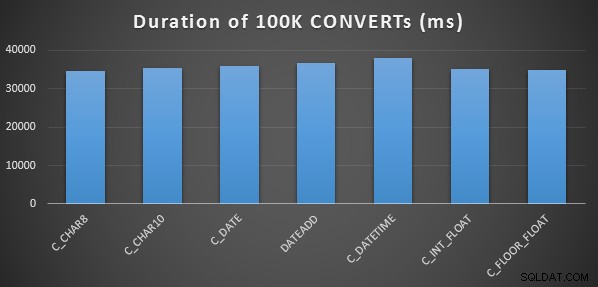
より複雑なパフォーマンステスト
また、これらのメソッドをさまざまなデータ型(DATETIME)と比較したいと思いました。 、SMALLDATETIME 、およびDATETIME2 )、クラスター化されたインデックスとヒープの両方に対して、データ圧縮の有無にかかわらず。そこで、最初に簡単なデータベースを作成しました。実験を通じて、1億2000万行を処理し、発生する可能性のあるすべてのログアクティビティを処理する(および自動拡張イベントがテストに干渉しないようにする)のに最適なサイズは、20GBのデータファイルと3GBのログであると判断しました。
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
次に、12個のテーブルを作成しました:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[その後、DATETIMEとDATETIME2についてもう一度繰り返します。]
次に、各テーブルに10,000,000行を挿入しました。これを行うには、毎回同じ10,000,000の日付を生成するビューを作成しました。
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
これにより、次のようにテーブルにデータを入力できました:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[次に、ヒープと非圧縮クラスター化インデックスについて再度繰り返します。 CHECKPOINTを入れました ログの再利用を確実にするために、各挿入の間に(リカバリモデルは単純です)。]
INSERTのタイミングと使用スペース
各挿入のタイミングは次のとおりです(プランエクスプローラーでキャプチャ):
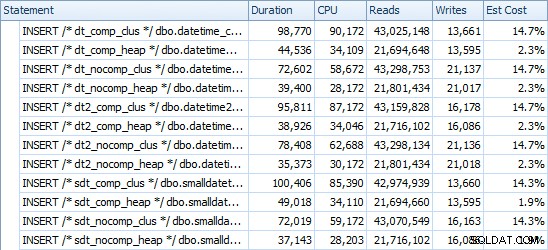
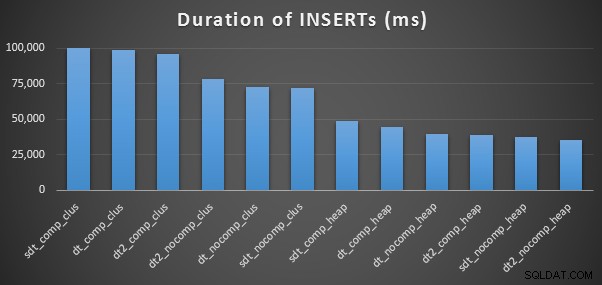
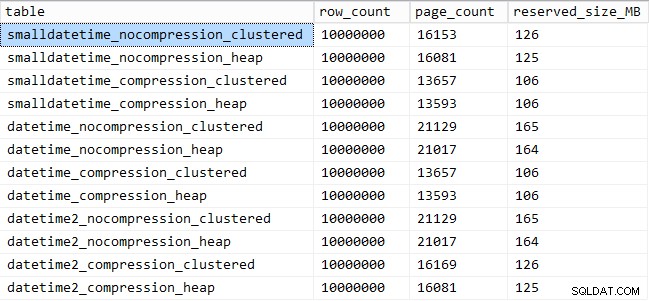
そして、これが各テーブルが占めるスペースの量です:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
クエリパターンのパフォーマンス
次に、パフォーマンスについて2つの異なるクエリパターンをテストすることに着手しました。
- 上記の7つのアプローチと、制限のない日付範囲を使用して、特定の日の行をカウントします
- 上記の7つのアプローチを使用して、すべての10,000,000行を変換し、生データを返すだけです(クライアント側でのフォーマットの方が良い場合があるため)
[FLOATを除く メソッドとDATETIME2 この変換は合法ではないため、列。]
最初の質問では、クエリは次のようになります(テーブルタイプごとに繰り返されます):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; クラスタ化されたインデックスに対する結果は次のようになります(クリックして拡大):
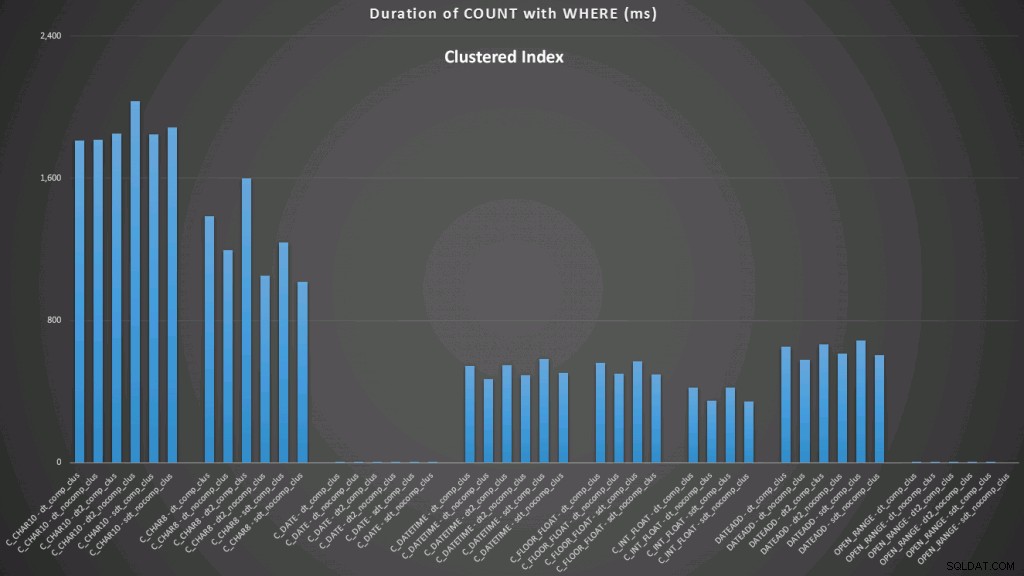
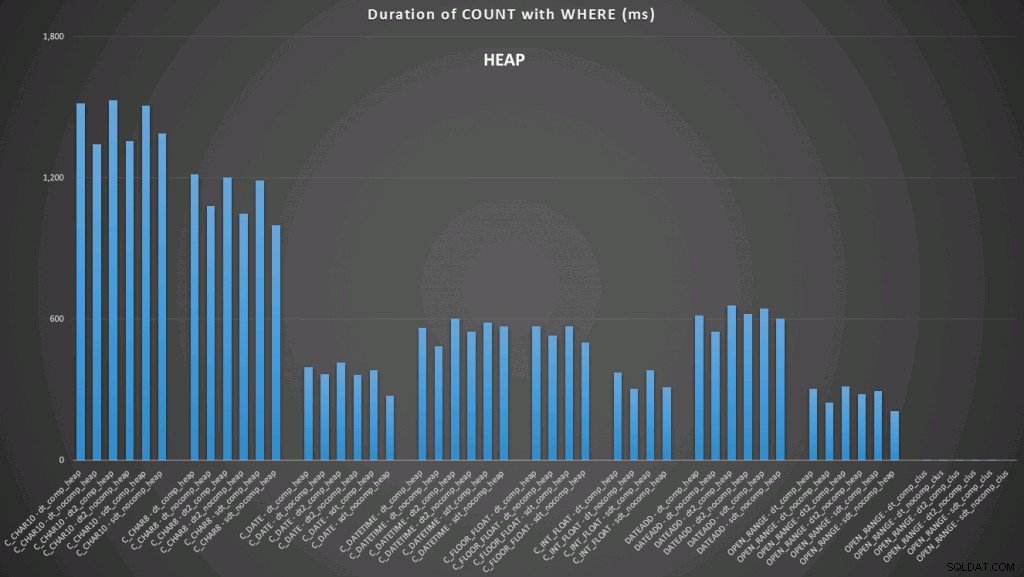
ここでは、日付への変換とインデックスを使用した制限のない範囲が最高のパフォーマンスを示していることがわかります。ただし、ヒープに対しては、日付への変換には実際には時間がかかるため、制限のない範囲が最適な選択になります(クリックして拡大):
そして、これが2番目のクエリセットです(ここでも、テーブルタイプごとに繰り返します):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; クラスター化されたインデックスを持つテーブルの結果に注目すると、日付への変換は、生データを選択するだけのパフォーマンスに非常に近いことは明らかです(クリックして拡大):
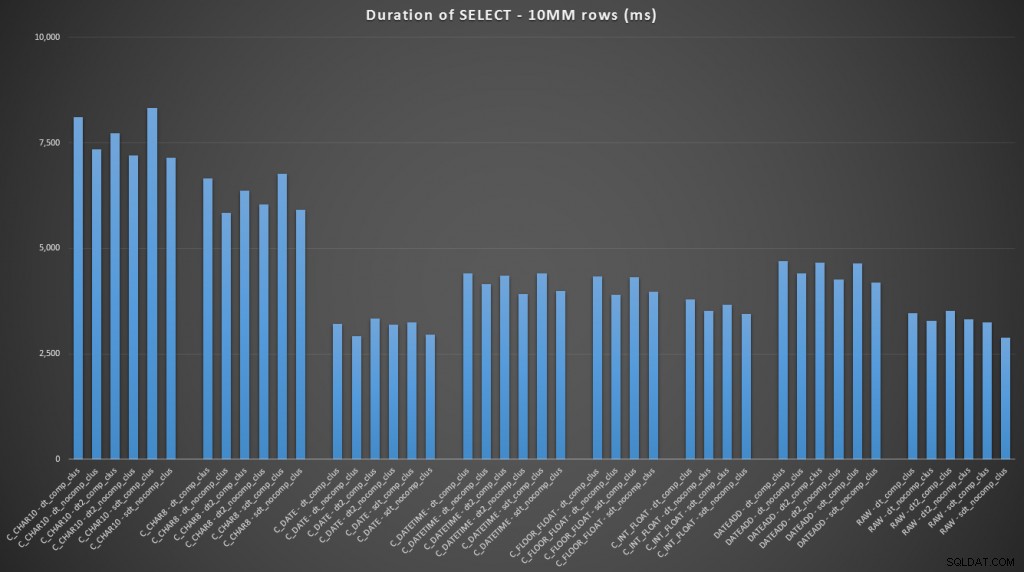
(この一連のクエリでは、ヒープは非常に類似した結果を示しました。実質的に区別できません。)
結論
パンチラインにスキップしたい場合、これらの結果は、メモリ内の変換は重要ではないことを示していますが、テーブルから出る途中で(または検索述語の一部として)データを変換する場合は、選択した方法でパフォーマンスへの劇的な影響。 DATEへの変換 (1日)またはいずれの場合も無制限の日付範囲を使用すると、最高のパフォーマンスが得られますが、文字列に変換する最も一般的な方法は絶対にひどいものです。
また、圧縮はストレージスペースに適切な影響を与える可能性があり、クエリのパフォーマンスにはごくわずかな影響しか与えないことがわかります。挿入パフォーマンスへの影響は、圧縮が有効になっているかどうかではなく、テーブルにクラスター化されたインデックスがあるかどうかに依存しているようです。ただし、クラスター化インデックスを配置すると、1,000万行を挿入するのにかかる時間に顕著な増加が見られました。覚えておいて、ディスクスペースの節約とバランスを取るための何か。
明らかに、より多くのテストが含まれる可能性があり、より実質的で多様なワークロードがあり、将来の投稿でさらに調査する可能性があります。