SQL Serverは従来、中央値の計算など、より一般的な統計の質問のいくつかにネイティブソリューションを提供することを避けてきました。 WikiPediaによると、「中央値は、サンプル、母集団、または確率分布の上半分を下半分から分離する数値として記述されます。有限リストの数値の中央値は、すべての観測値を最小値から最大値へと中間値を選択します。観測値が偶数の場合、単一の中間値はありません。中央値は通常、2つの中間値の平均として定義されます。 "
SQL Serverクエリに関して、それから取り除く重要なことは、すべての値を「配置」(並べ替え)する必要があるということです。 SQL Serverでの並べ替えは、サポートするインデックスがない場合、通常はかなりコストのかかる操作であり、おそらく要求されない操作をサポートするためにインデックスを追加することは、多くの場合価値がない可能性があります。
以前のバージョンのSQLServerでこの問題を通常どのように解決したかを調べてみましょう。まず、非常に単純なテーブルを作成して、ロジックが正しいことを確認し、正確な中央値を導き出すことができるようにします。次の2つのテーブルをテストできます。1つは偶数の行で、もう1つは奇数の行です。
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); カジュアルな観察から、奇数行のテーブルの中央値は6であり、偶数テーブルの中央値は7.5((6 + 9)/ 2)であることがわかります。それでは、何年にもわたって使用されてきたいくつかのソリューションを見てみましょう:
SQL Server 2000
SQL Server 2000では、非常に限られたT-SQLダイアレクトに制限されていました。比較のためにこれらのオプションを調査しています。SQLServer2000をまだ実行している人もいれば、アップグレードした人もいるためですが、計算の中央値は「当時」に書かれていたため、コードは今日でも次のようになっている可能性があります。
2000_A –最大で半分、最小で他の半分
このアプローチでは、最初の50パーセントから最高値を取得し、最後の50パーセントから最低値を取得して、それらを2で除算します。これは、偶数行または奇数行で機能します。これは、偶数の場合、2つの値が2つの中央の行であり、奇数の場合、2つの値が実際には同じ行からのものであるためです。
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B –#tempテーブル
この例では、最初に#tempテーブルを作成し、上記と同じタイプの計算を使用して、隣接するIDENTITYの支援を受けて2つの「中央」行を決定します。 val列順に並べられた列。 (IDENTITYの割り当ての順序 MAXDOPがあるため、値のみが信頼できます。 設定。)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
); SQL Server 2005、2008、2008 R2
SQL Server 2005では、ROW_NUMBER()などの興味深い新しいウィンドウ関数がいくつか導入されました。 、これは、SQL Server 2000よりも中央値などの統計上の問題を少し簡単に解決するのに役立ちます。これらのアプローチはすべて、SQLServer2005以降で機能します。
2005_A –決闘行番号
この例では、ROW_NUMBER()を使用しています 値を各方向に1回上下に移動し、その計算に基づいて「中央」の1行または2行を見つけます。これは上記の最初の例と非常によく似ていますが、構文が簡単です。
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B –行番号+カウント
これは上記と非常によく似ており、ROW_NUMBER()を1回計算します。 次に、合計COUNT()を使用します 「中央」の1行または2行を見つけるには:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C –行番号+カウントのバリエーション
仲間のMVPItzikBen-Ganがこの方法を教えてくれました。これは、上記の2つの方法と同じ答えを実現しますが、方法が少し異なります。
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); SQL Server 2012
SQL Server 2012では、T-SQLに新しいウィンドウ機能があり、中央値などの統計計算をより直接的に表現できます。一連の値の中央値を計算するには、PERCENTILE_CONT()を使用できます。 。 ORDER BYの新しい「ページング」拡張機能を使用することもできます 句(OFFSET / FETCH 。
2012_A –新しい配布機能
このソリューションでは、分布を使用した非常に単純な計算を使用します(行数が偶数の場合に、2つの中間値の平均が必要ない場合)。
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B –ページングトリック
この例では、OFFSET / FETCHの巧妙な使用法を実装しています。 (正確には意図されたものではありません)–カウントの半分の前の行に移動し、カウントが奇数か偶数かに応じて次の1行または2行を取得します。このアプローチを指摘してくれたItzikBen-Ganに感謝します。
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x; しかし、どちらがパフォーマンスが優れていますか?
上記のすべての方法で小さなテーブルに期待どおりの結果が得られることを確認しました。また、SQLServer2012バージョンの構文が最もクリーンで論理的であることがわかりました。しかし、忙しい本番環境ではどちらを使用する必要がありますか?システムメタデータからはるかに大きなテーブルを作成して、重複する値がたくさんあることを確認できます。このスクリプトは、10,000,000個の一意でない整数を含むテーブルを生成します:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
私のシステムでは、このテーブルの中央値は146,099,561である必要があります。次のクエリを使用すると、10,000,000行を手動でスポットチェックしなくても、これを非常にすばやく計算できます。
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); 結果:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
これで、メソッドごとにストアドプロシージャを作成し、各メソッドが正しい出力を生成することを確認してから、期間、CPU、読み取りなどのパフォーマンスメトリックを測定できます。これらの手順はすべて、既存のテーブルと、クラスター化インデックスの恩恵を受けていないテーブルのコピーを使用して実行します(ドロップして、テーブルをヒープとして再作成します)。
上記のクエリメソッドを実装する7つのプロシージャを作成しました。簡潔にするために、ここではリストしませんが、それぞれにdbo.Median_<version>という名前を付けます。 、例: dbo.Median_2000_A 、dbo.Median_2000_B 上記のアプローチに対応するなど。無料のSQLSentryPlan Explorerを使用してこれらの7つのプロシージャを実行すると、期間、CPU、および読み取りに関して次のようになります(実行の間にDBCCFREEPROCCACHEとDBCCDROPCLEANBUFFERSを実行することに注意してください):
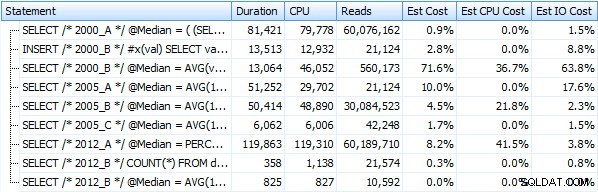
そして、代わりにヒープに対して操作する場合、これらのメトリックはほとんど変化しません。最大の変化率は、それでも最速であることになった方法でした。OFFSET/ FETCHを使用したページングトリック:
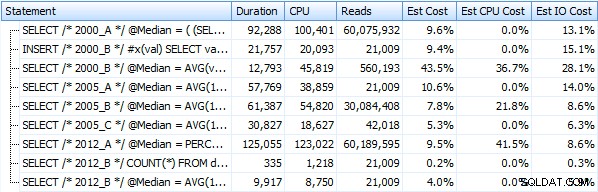
これが結果のグラフ表示です。より明確にするために、最も遅いパフォーマーを赤で、最も速いアプローチを緑で強調しました。
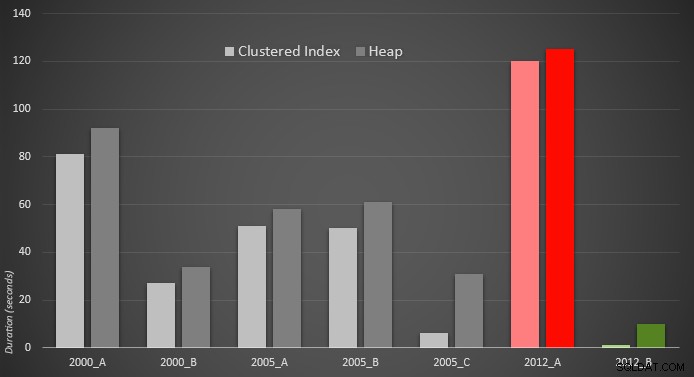
どちらの場合も、PERCENTILE_CONT()であることに驚きました。 このタイプの計算用に設計されたものは、実際には他のすべての以前のソリューションよりも劣っています。新しい構文を使用するとコーディングが簡単になる場合もありますが、必ずしもパフォーマンスが向上するとは限りません。 OFFSET / FETCHも見てびっくりしました 通常は目的に合わないように思われるシナリオ、つまりページネーションで非常に役立つことがわかります。
いずれにせよ、SQL Serverのバージョンに応じて、どのアプローチを使用する必要があるかを示したことを願っています(そして、計算をサポートするインデックスがあるかどうかにかかわらず、選択は同じである必要があります)。