SQLServerで値のシーケンスを生成するための多くのユースケースがあります。永続的なIDENTITYについて話しているのではありません 列(または新しいSEQUENCE SQL Server 2012)ではなく、クエリの存続期間中にのみ使用される一時的なセットです。または、結果セットの各行に行番号を追加するなどの最も単純な場合でも、ROW_NUMBER()を追加する必要があります。 クエリに対して機能します(または、プレゼンテーション層では、とにかく結果を行ごとにループする必要があります)。
もう少し複雑なケースについて話しています。たとえば、日付ごとの売上を示すレポートがあるとします。一般的なクエリは次のとおりです。
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
このクエリの問題は、特定の日に注文がない場合、その日の行がないことです。これは、混乱、誤解を招くデータ、またはデータのダウンストリームコンシューマーの誤った計算(1日の平均を考えてください)につながる可能性があります。
したがって、これらのギャップをデータに存在しない日付で埋める必要があります。また、データを#tempテーブルに詰め込んで、WHILEを使用することもあります。 ループまたはカーソルを使用して、欠落している日付を1つずつ入力します。その使用を推奨したくないので、ここではそのコードを示しませんが、あちこちで見ました。
ただし、日付について深く掘り下げる前に、まず数字について説明しましょう。数字のシーケンスを使用して、日付のシーケンスを導き出すことができるからです。
数値表
私は長い間、補助的な「数値テーブル」をディスクに保存することを提唱してきました(さらに言えば、カレンダーテーブルも)。
1,000,000個の値を持つ単純な数値テーブルを生成する1つの方法は次のとおりです。
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
なぜMAXDOP1なのか?行の目標に関連するPaulWhiteのブログ投稿と彼のConnectアイテムを参照してください。
ただし、多くの人が補助テーブルアプローチに反対しています。彼らの主張:データをオンザフライで生成できるのに、なぜすべてのデータをディスク(およびメモリ)に保存するのですか?私のカウンターは現実的であり、あなたが最適化しているものについて考えることです。計算にはコストがかかる可能性があり、その場で数値の範囲を計算する方が常に安くなると確信していますか?スペースに関しては、Numbersテーブルは約11 MBの圧縮、および17MBの非圧縮のみを使用します。また、テーブルが頻繁に参照される場合は、常にメモリ内にある必要があり、アクセスが高速になります。
いくつかの例と、それらを満たすために使用されるより一般的なアプローチのいくつかを見てみましょう。 1,000の値であっても、ループやカーソルを使用してこれらの問題を解決したくないということに、私たち全員が同意できることを願っています。
1,000個の数字のシーケンスを生成する
簡単に始めて、1から1,000までの数字のセットを生成しましょう。
数値表
もちろん、数値テーブルを使用すると、このタスクは非常に簡単です。
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
計画:
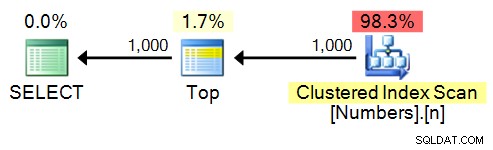
spt_values
これは、さまざまな目的で内部ストアドプロシージャによって使用されるテーブルです。オンラインでの使用は、文書化されておらず、サポートされていなくても、いつか消えてしまう可能性があり、有限で、一意ではなく、連続していない値のセットしか含まれていないため、かなり普及しているようです。 SQL Server 2008 R2には、2,164の一意の値と2,508の合計値があります。 2012年には2,167のユニークで、合計2,515があります。これには、重複、負の値、およびDISTINCTを使用している場合でも含まれます 、2,048の数を超えると、多くのギャップが生じます。したがって、回避策はROW_NUMBER()を使用することです。 表の値に基づいて、1から始まる連続したシーケンスを生成します。
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
計画:

とはいえ、1,000個の値については、少し単純なクエリを記述して同じシーケンスを生成できます。
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
もちろん、これはより単純な計画につながりますが、非常に迅速に崩壊します(シーケンスが2,048行を超える必要がある場合):
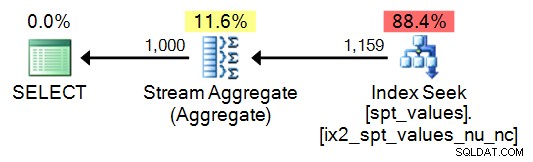
いずれにせよ、このテーブルの使用はお勧めしません。比較のために含めていますが、これは、これがどれだけあるか、そして出くわしたコードを再利用することがどれほど魅力的かを知っているからです。
sys.all_objects
長年にわたって私のお気に入りの1つである別のアプローチは、sys.all_objectsを使用することです。 。 spt_valuesのように 、連続したシーケンスを直接生成する信頼できる方法はありません。有限セット(SQL Server 2008 R2では2,000行弱、SQL Server 2012では2,000行強)を処理する場合も同じ問題がありますが、1,000行の場合です。同じROW_NUMBER()を使用できます 騙す。このアプローチが好きな理由は、(a)このビューがすぐに消える心配が少なく、(b)ビュー自体が文書化されてサポートされており、(c)SQLServer以降の任意のバージョンの任意のデータベースで実行されるためです。 2005年、データベースの境界を越える必要はありません(含まれているデータベースを含む)。
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
計画:

スタックCTE
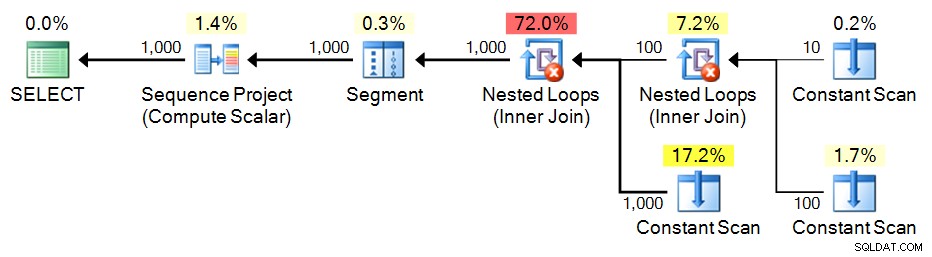
Itzik Ben-Ganは、このアプローチの究極の功績に値すると思います。基本的に、小さな値のセットを使用してCTEを構築し、次に、必要な行数を生成するために、それ自体に対してデカルト積を作成します。また、基になるクエリの一部として連続したセットを生成しようとする代わりに、ROW_NUMBER()を適用するだけで済みます。 最終結果に。
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; 計画:
再帰CTE
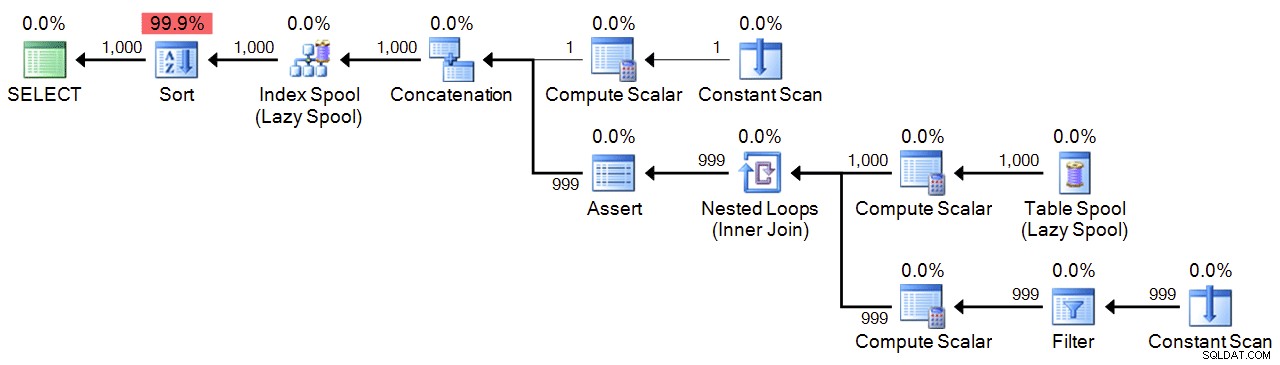
最後に、再帰CTEがあります。これは、アンカーとして1を使用し、最大値に達するまで1を追加します。安全のため、両方のWHEREで最大値を指定します 再帰部分の句、およびMAXRECURSION 設定。必要な数によっては、MAXRECURSIONを設定する必要がある場合があります 0へ 。
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); 計画:
パフォーマンス
もちろん、1,000の値を使用すると、パフォーマンスの違いはごくわずかですが、これらのさまざまなオプションがどのように機能するかを確認すると便利です。
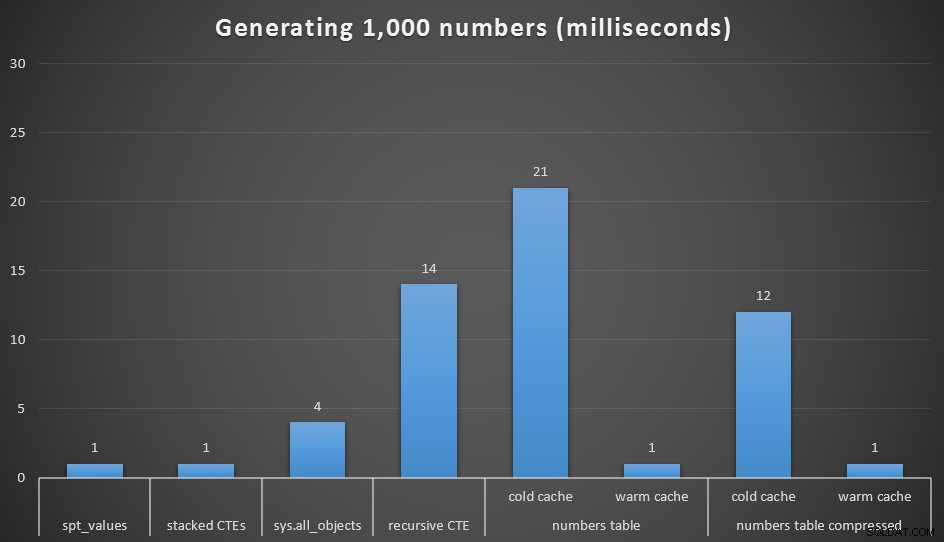
ミリ秒単位の実行時間(1,000個の連続した数値を生成するため)>
各クエリを20回実行し、平均実行時間を要しました。 dbo.Numbersもテストしました 圧縮形式と非圧縮形式の両方で、コールドキャッシュとウォームキャッシュの両方を備えたテーブル。ウォームキャッシュを使用すると、他の最速のオプション(spt_values)に非常によく匹敵します。 、推奨されません、スタックされたCTE)が、最初のヒットは比較的高価です(私はそれをそれと呼んでほとんど笑っていますが)。
続く…
これが典型的なユースケースであり、1,000行をはるかに超えて冒険しないのであれば、これらの数値を生成するための最速の方法を示したことを願っています。ユースケースの数が多い場合、または一連の日付を生成するソリューションを探している場合は、しばらくお待ちください。このシリーズの後半では、50,000と1,000,000の数値のシーケンスを生成し、日付範囲を1週間から1年にする方法について説明します。
[パート1|パート2|パート3]