ヒットハイライトは、SQLServerの全文検索でネイティブにサポートされることを多くの人が望んでいる機能です。ここで、ドキュメント全体(または抜粋)を返し、そのドキュメントを検索に一致させるのに役立った単語やフレーズを指摘できます。私が直接知ったように、効率的かつ正確な方法でそうすることは簡単な作業ではありません。
ヒットハイライトの例として、GoogleまたはBingで検索を実行すると、タイトルと抜粋の両方でキーワードが太字になります(いずれかの画像をクリックすると拡大します):

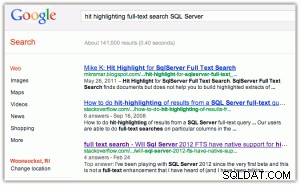
[余談ですが、ここで面白いことが2つあります。(1)BingはGoogleよりもMicrosoftのプロパティをはるかに好んでいること、(2)Bingはわざわざ220万件の結果を返していることですが、その多くはおそらく無関係です。]
>これらの抜粋は、一般に「スニペット」または「クエリバイアスの要約」と呼ばれます。 SQL Serverでこの機能を求めてきましたが、Microsoftからの良いニュースはまだ聞いていません:
- Connect#295100:全文検索の概要(ヒットハイライト)
- 接続#722324:SQL全文検索でスニペット/強調表示のサポートが提供されれば便利です
質問はStackOverflowにも時々表示されます:
- SQLServerフルテキストクエリの結果をヒットハイライト表示する方法
- Sql Server 2012 FTSは、ヒットの強調表示をネイティブでサポートしますか?
いくつかの部分的な解決策があります。たとえば、Mike Kramarのこのスクリプトは、ヒットが強調表示された抽出を生成しますが、ドキュメント自体に同じロジック(言語固有のワードブレーカーなど)を適用しません。また、絶対文字数を使用するため、抜粋は部分的な単語で開始および終了できます(後で説明します)。後者は非常に簡単に修正できますが、別の問題は、あらゆる種類のストリーミングを実行するのではなく、ドキュメント全体をメモリにロードすることです。ドキュメントサイズが大きいフルテキストインデックスでは、これは顕著なパフォーマンスの低下になると思います。今のところ、比較的小さい平均ドキュメントサイズ(35 KB)に焦点を当てます。
簡単な例
したがって、フルテキストインデックスが定義された非常に単純なテーブルがあるとします。
CREATE FULLTEXT CATALOG [FTSDemo]; GO CREATE TABLE [dbo].[Document] ( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL, [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID) ); GO CREATE FULLTEXT INDEX ON [dbo].[Document] ( [Content] LANGUAGE [English], [Title] LANGUAGE [English] ) KEY INDEX [PK_Document] ON ([FTSDemo]);
この表には、独立宣言やネルソンマンデラの「私は死ぬ準備ができている」というスピーチなど、いくつかの文書(具体的には7つ)が含まれています。このテーブルに対する一般的な全文検索は次のようになります。
SELECT d.Title, d.[Content] FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
結果は7行のうち4行を返します:

現在、Mike KramarのようなUDF関数を使用しています:
SELECT d.Title, Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80) FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
結果は、抜粋がどのように機能するかを示しています:<SPAN> タグは最初のキーワードに挿入され、抜粋はその位置からのオフセットに基づいて切り分けられます(完全な単語の使用は考慮されていません):

(繰り返しになりますが、これは修正できるものですが、現在そこにあるものを適切に表現していることを確認したいと思います。)
ThinkHighlight
InteractiveThoughtsのEranMeyuchasは、これらの問題の多くを解決するコンポーネントを開発しました。 ThinkHighlightは、2つのCLRスカラー値関数を使用したCLRアセンブリとして実装されます。
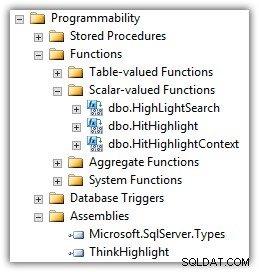
(関数のリストにはMike KramarのUDFも表示されます。)
ここで、システムへのアセンブリのインストールとアクティブ化に関するすべての詳細に立ち入ることなく、上記のクエリがThinkHighlightでどのように表されるかを次に示します。
SELECT d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC; 結果は、最も関連性の高いキーワードがどのように強調表示されているかを示しており、抜粋は、完全な単語と強調表示されている用語からのオフセットに基づいて導き出されています。

ここで示していない追加の利点には、さまざまな要約戦略を選択できること、一意のCSSを使用して(すべてではなく)各キーワードの表示を制御できること、複数の言語、さらにはバイナリ形式のドキュメント(ほとんどのIFilters)のサポートがあります。サポートされています。
パフォーマンス結果
最初に、SQL Sentry Plan Explorerを使用して、7行のテーブルに対して3つのクエリのランタイムメトリックをテストしました。結果は次のとおりです。

次に、はるかに大きなデータサイズでそれらがどのように比較されるかを確認したいと思いました。 4,000行になるまでテーブルを挿入してから、次のクエリを実行しました。
SET STATISTICS TIME ON;
GO
SELECT /* FTS */ d.Title, d.[Content]
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* UDF */ d.Title,
Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* ThinkHighlight */ d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC;
GO
SET STATISTICS TIME OFF;
GO また、クエリの実行中にsys.dm_exec_memory_grantsを監視して、メモリ付与の不一致を検出しました。 10回の実行で平均した結果:
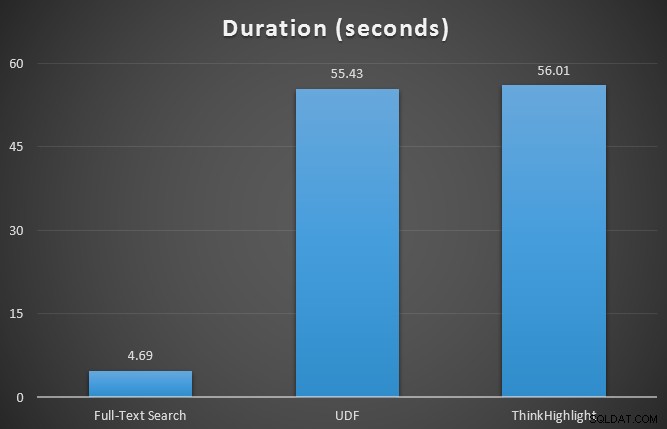
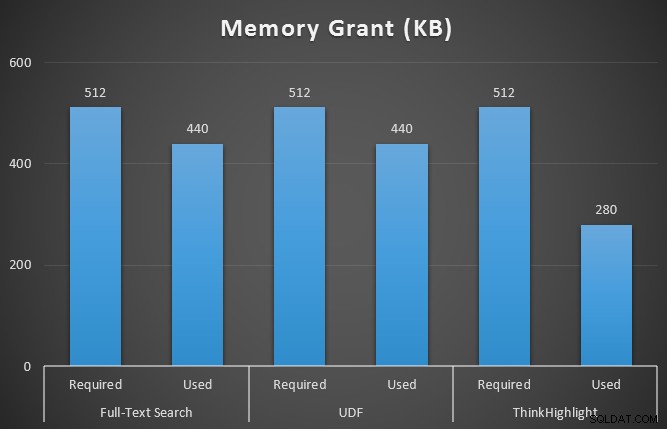
どちらのヒットハイライトオプションも、まったくハイライトしない場合に大きなペナルティが発生しますが、ThinkHighlightソリューションは、より柔軟なオプションを使用して、継続時間(〜1%)の点で非常にわずかな増分コストを表し、メモリの使用量は大幅に少なくなります(36%)。 UDFバリアントよりも。
結論
ヒットハイライトが高価な操作であり、サポートする必要があるものの複雑さに基づいて(複数の言語を考えてください)、そこに存在するソリューションが非常に少ないことは驚くべきことではありません。 Mike Kramarは、問題を解決するための良い方法を提供するベースラインUDFを作成する優れた仕事をしたと思いますが、より堅牢な商用製品を見つけて嬉しい驚きを感じました。ベータ版でも非常に安定していることがわかりました。より広範囲のドキュメントサイズとタイプを使用して、より徹底的なテストを実行する予定です。それまでの間、ヒットハイライトがアプリケーション要件の一部である場合は、Mike KramarのUDFを試して、ThinkHighlightを試乗することを検討してください。