Books Onlineで言及されているフィルタリングされたインデックスのユースケースの1つは、主に NULLを含む列に関するものです。 値。アイデアは、 NULLsを除外するフィルター処理されたインデックスを作成することです 、結果として、同等のフィルタリングされていないインデックスよりもメンテナンスが少なくて済む、クラスター化されていないインデックスが小さくなります。 フィルター処理されたインデックスのもう1つの一般的な使用法は、 NULLをフィルター処理することです。 UNIQUEから インデックス。他のデータベースエンジンのユーザーがデフォルトのUNIQUEに期待する動作を提供します。 インデックスまたは制約: NULL以外の場合にのみ強制される一意性 値。
残念ながら、クエリオプティマイザには、フィルタリングされたインデックスに関する制限があります。この投稿では、あまり知られていない例をいくつか見ていきます。
サンプルテーブル
同じ構造の2つのテーブル(AとB)を使用します。代理のクラスター化された主キー、ほとんどが NULL 一意の列( NULLs を無視) )、および実際のテーブルにある可能性のある他の列を表すパディング列。
対象の列は主に-NULL 1つは、 SPARSEとして宣言しました 。スパースオプションは必須ではありません。使用する機会があまりないため、スパースオプションを含めるだけです。いずれにせよ、 SPARSE おそらく、列データの大部分が NULLであると予想される多くのシナリオで意味があります。 。必要に応じて、例からスパース属性を自由に削除してください。
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
各テーブルには、データ列に1から2,000までの数字が含まれ、データ列が NULLである場合はさらに40,000行が含まれます。 :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
両方のテーブルがUNIQUEを取得します 2,000個の非NULLのフィルタリングされたインデックス データ値:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
DBCC SHOW_STATISTICSの出力 状況を要約します:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

サンプルクエリ
以下のクエリは、2つのテーブルの単純な結合を実行します。テーブルが何らかの親子関係にあり、外部キーの多くがNULLであると想像してください。とにかくそれらの線に沿った何か。
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; デフォルトの実行プラン
SQL Serverがデフォルト構成の場合、オプティマイザーは並列ネストループ結合を特徴とする実行プランを選択します。
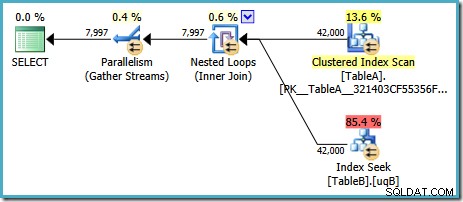
このプランの推定費用は7.7768 マジックオプティマイザーユニット™。
ただし、この計画には奇妙なことがいくつかあります。インデックスシークはテーブルBでフィルタリングされたインデックスを使用しますが、クエリはテーブルAのクラスター化インデックススキャンによって駆動されます。結合述語はデータ列の同等性テストであり、 NULLs> ( ANSI_NULLSに関係なく 設定)。オプティマイザーがその観察に基づいて高度な推論を実行することを期待したかもしれませんが、そうではありません。 このプランは、テーブルAからすべての行を読み取ります(40,000個の NULL を含む) )、 NULL という事実に基づいて、テーブルBのフィルタリングされたインデックスをそれぞれについてシークします。 NULLとは一致しません そのシークで。これは多大な労力の無駄です。
奇妙なことに、オプティマイザーは結合が NULLsを拒否することを認識している必要があります。 テーブルBのフィルター処理されたインデックスを選択するためにシークしますが、 NULLsをフィルター処理することは考えていませんでした。 最初にテーブルAから、またはさらに良いことに、 NULLをスキャンするだけです。 -テーブルAのフィルターされたインデックスを解放します。これがコストベースの決定であるかどうか疑問に思うかもしれません。統計があまり良くないのではないでしょうか。おそらく、ヒントを使用してフィルター処理されたインデックスの使用を強制する必要がありますか?テーブルAでフィルタリングされたインデックスをヒントにすると、同じプランになり、ロールが逆になります。テーブルBをスキャンし、テーブルAをシークします。両方のテーブルにフィルタリングされたインデックスを強制すると、エラー8622が発生します。 :クエリプロセッサはクエリプランを作成できませんでした。
NOTNULL述語の追加
原因が暗黙のNULLに関係していると思われる -結合述語の拒否、明示的な NOT NULLを追加します ONの述語 句(または WHERE 必要に応じて、ここでも同じことが言えます):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
NOT NULLを追加しました 元のプランでは、フィルター処理されたインデックスを使用するのではなく、そのテーブルのクラスター化インデックスをスキャンしたため、テーブルAの列を確認してください(テーブルBへのシークは問題ありませんでした。フィルター処理されたインデックスを使用しました)。新しいクエリは、意味的には前のクエリとまったく同じですが、実行プランが異なります。
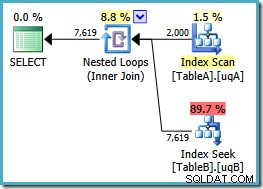
これで、テーブルAのフィルター処理されたインデックスのスキャンが期待され、 NULL以外の2,000が生成されました。 ネストされたループを駆動する行は、テーブルBをシークします。両方のテーブルは、フィルター処理されたインデックスを明らかに最適に使用しています。新しいプランのコストは 0.362835です。 ユニット(7.7768から減少)。ただし、もっとうまくやることができます。
2つのNOTNULL述語を追加する
冗長なNOTNULL テーブルAの述語は驚異的に機能しました。テーブルBにも1つ追加するとどうなりますか?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; このクエリは、以前の2つの取り組みと論理的に同じですが、実行プランはまた異なります:
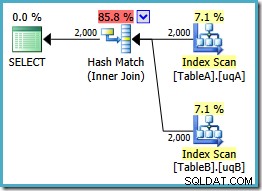
このプランは、テーブルAから2,000行のハッシュテーブルを作成し、テーブルBから2,000行を使用して一致をプローブします。返される推定行数は、以前の計画(そこで7,619の見積もりに気づきましたか?)および見積もりの実行コストは、0.362835から 0.0772056に再び低下しました。 。
オリジナルまたはシングルのヒントを使用してハッシュ結合を強制することができます-NOTNULL クエリを実行しますが、上記の低コストのプランは取得できません。オプティマイザーには、 NULLについて完全に推論する機能がありません。 -両方の冗長な述語なしでフィルタリングされたインデックスに適用されるため、結合の動作を拒否します。
これには驚かされることがあります。たとえ、1つの冗長な述語では不十分であるという考えだけであっても( ta.data の場合は確かです)。 NOT NULLです およびta.data=tb.data 、次のようになります tb.data NOT NULLでもあります 、そうですか?)
まだ完璧ではありません
ハッシュがそこに参加しているのを見るのは少し驚きです。 3つの物理結合演算子の主な違いに精通している場合は、ハッシュ結合が次の場合の最有力候補であることをおそらくご存知でしょう。
- 事前に並べ替えられた入力は利用できません
- ハッシュビルド入力がプローブ入力よりも小さい
- プローブ入力が非常に大きい
ここではこれらのことはどれも当てはまりません。このクエリとデータセットの最適な計画は、2つのフィルター処理されたインデックスから利用可能な順序付けされた入力を利用するマージ結合であると予想されます。 2つの余分なONを保持したまま、マージ結合のヒントを試すことができます 節の述語:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); 計画の形は私たちが望んでいた通りです:
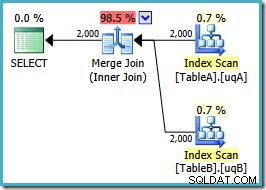
両方のフィルター処理されたインデックスの順序付けられたスキャン、優れたカーディナリティ推定、素晴らしい。小さな問題が1つだけあります。この実行計画ははるかに悪い;推定コストは0.0772056から0.741527に跳ね上がりました 。推定コストが急上昇した理由は、マージ結合演算子のプロパティを確認することで明らかになります。
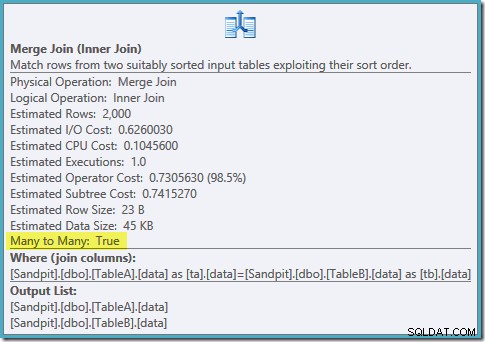
これは高価な多対多の結合であり、実行エンジンはワークテーブルの外部入力からの重複を追跡し、必要に応じて巻き戻す必要があります。重複しますか?ユニークなインデックスをスキャンしています! オプティマイザは、フィルタリングされた一意のインデックスが一意の値を生成することを認識していません。 (ここでアイテムを接続します)。実際、これは1対1の結合ですが、オプティマイザーは多対多のようにコストをかけ、ハッシュ結合プランを好む理由を説明しています。
代替戦略
ここでフィルター処理されたインデックスを使用すると、オプティマイザーの制限に直面し続けるようです(Books Onlineで強調表示されているユースケースにもかかわらず)。代わりにビューを使用しようとするとどうなりますか?
ビューの使用
次の2つのビューは、ベーステーブルをフィルタリングして、データ列が NOT NULLである行を表示します。 :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; ビューを使用するように元のクエリを書き直すのは簡単です:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; このクエリは元々、 7.7768の並列ネストループプランを作成したことを思い出してください。 ユニット。ビュー参照を使用して、次の実行プランを取得します。
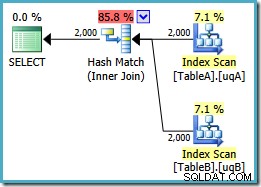
これは、冗長な NOT NULLを追加する必要があったハッシュ結合プランとまったく同じです。 フィルタリングされたインデックスを取得するための述語(コストは 0.0772056 以前のようにユニット)。ここで基本的に行ったのは、余分な NOT NULL をプッシュすることだけなので、これは予想されることです。 クエリからビューへの述語。
ビューのインデックス作成
pk列に一意のクラスター化されたインデックスを作成して、ビューを具体化することもできます。
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
これで、インデックス付きビューのフィルター処理されたデータ列に一意の非クラスター化インデックスを追加できます。
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
ビューでフィルタリングが実行されることに注意してください。これらの非クラスター化インデックス自体はフィルタリングされません。
完璧な計画
これで、 NOEXPAND を使用して、ビューに対してクエリを実行する準備が整いました。 表のヒント:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; 実行計画は次のとおりです。
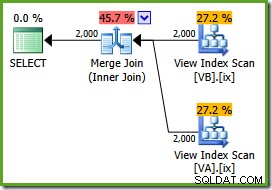
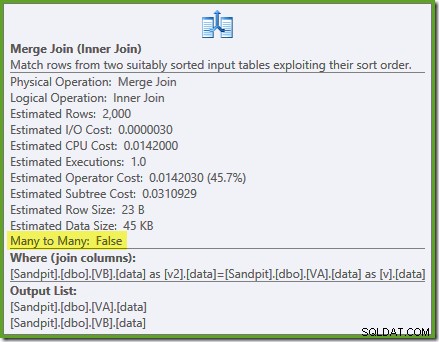
オプティマイザーはフィルタリングされていないを見ることができます 非クラスター化ビューインデックスは一意であるため、多対多のマージ結合は必要ありません。この最終的な実行計画の推定コストは0.0310929です。 ユニット–ハッシュ結合プラン(0.0772056ユニット)よりもさらに低くなります。これは、マージ結合がこのクエリとサンプルデータセットの推定コストを最小にする必要があるという私たちの期待を検証します。
NOEXPAND Enterprise Editionでも、ビューインデックスによって提供される一意性の保証がオプティマイザによって使用されるようにするためのヒントが必要です。
概要
この投稿では、フィルター処理されたインデックスに関する2つの重要なオプティマイザーの制限に焦点を当てています。
- フィルタリングされたインデックスと一致させるには、冗長な結合述語が必要になる場合があります
- フィルター処理された一意のインデックスは、オプティマイザーに一意性情報を提供しません
場合によっては、すべてのクエリに冗長な述語を追加するだけでよい場合があります。別の方法は、インデックス付けされていないビューで目的の暗黙の述語をカプセル化することです。この投稿のハッシュマッチプランは、オプティマイザーがわずかに優れたマージ結合プランを見つけることができるはずですが、デフォルトプランよりもはるかに優れていました。場合によっては、ビューにインデックスを付けて NOEXPANDを使用する必要があります。 ヒント(Standard Editionインスタンスにはとにかく必要です)。さらに他の状況では、これらのアプローチはどれも適切ではありません。申し訳ありません:)