SQL Serverで作成された新しいデータベースの場合、[統計の自動更新]オプションのデフォルト値は有効です。 。オプティマイザが統計を無効にしたときに自動的に更新できるため、ほとんどのDBAはこのオプションを有効のままにしておくと思われます。通常は、有効のままにしておくことをお勧めします。統計は、インデックスが再構築されたときにも更新されます。統計の自動更新オプションやインデックスの再構築によって統計が適切に管理されることは珍しくありませんが、DBAは、定期的なジョブを設定して更新する必要がある場合があります。統計、または一連の統計。
統計のカスタム管理には、多くの場合、UPDATESTATISTICSコマンドが含まれます。これはかなり害がないようです。テーブルまたはインデックス付きビューのすべての統計、または特定の統計に対して実行できます。デフォルトのサンプルを使用することも、特定のサンプルレートまたはサンプリングする行数を指定することも、以前に使用したものと同じサンプル値を使用することもできます。テーブルまたはインデックス付きビューの統計を更新する場合は、すべての統計を更新するか、インデックス統計のみを更新するか、列統計のみを更新するかを選択できます。そして最後に、統計の自動更新統計オプションを無効にすることができます。
ほとんどのDBAにとって、最大の考慮事項はいつである可能性があります UPDATESTATISTICSステートメントを実行します。しかし、DBAは、意識的にかどうかにかかわらず、更新のサンプルサイズも決定します。選択したサンプルサイズは、実際の更新のパフォーマンスだけでなく、クエリのパフォーマンスにも影響を与える可能性があります。
サンプルサイズの影響を理解する
UPDATE STATISTICSのデフォルトのサンプルサイズは非線形アルゴリズムから取得され、JoeSackが彼の投稿「Auto-UpdateStatsDefaultSampling Test」で示したように、テーブルサイズが大きくなるにつれてサンプルサイズは減少します。場合によっては、サンプルサイズが十分な興味深い情報を取得するのに十分な大きさではないか、正しい ConorCunninghamがStatisticsSampleRateの投稿で指摘したように、統計ヒストグラムの情報。デフォルトのサンプルで適切なヒストグラムが作成されない場合、DBAは、フルスキャン(テーブルまたはインデックス付きビューのすべての行をスキャンする)まで、より高いサンプリングレートで統計を更新することを選択できます。しかし、Conorが彼の投稿で述べたように、より多くの行をスキャンするにはコストがかかり、DBAは、FULLSCANを実行して可能な限り「最良の」ヒストグラムを作成するか、より少ないパーセンテージをサンプリングしてパフォーマンスへの影響を最小限に抑えるかを決定する必要があります。アップデート。
サンプルがFULLSCANよりも長くかかる時点を理解するために、JonathanKehayiasのスクリプトを使用して拡大されたSalesOrderDetailテーブルのコピーに対して次のステートメントを実行しました。
| ステートメントID | UPDATESTATISTICSステートメント |
|---|---|
| 1 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]WITHFULLSCAN; |
| 2 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]; |
| 3 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]WITHSAMPLE 10 PERCENT; |
| 4 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]WITHSAMPLE 25 PERCENT; |
| 5 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]WITHSAMPLE 50 PERCENT; |
| 6 | UPDATESTATISTICS[Sales]。[SalesOrderDetailEnlarged]WITHSAMPLE 75 PERCENT; |
SalesOrderDetailEnlargedテーブルのコピーが3つあり、次の特性があります*:
| 行数 | ページ数 | MAXDOP | 最大メモリ | ストレージ | マシン |
|---|---|---|---|---|---|
| 23,899,449 | 363,284 | 4 | 8GB | SSD_1 | ラップトップ |
| 607,312,902 | 7,757,200 | 16 | 54GB | SSD_2 | テストサーバー |
| 607,312,902 | 7,757,200 | 16 | 54GB | 15K | テストサーバー |
*ハードウェアに関する追加の詳細はこの投稿の最後にあります。
テーブルのすべてのコピーには次の統計があり、3つのインデックス統計のいずれにも列が含まれていませんでした:
| 統計 | タイプ | キーの列 |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | SalesOrderID、SalesOrderDetailID | |
| AK_SalesOrderDetailEnlarged_rowguid | インデックス | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | インデックス | ProductId |
| user_CarrierTrackingNumber | 列 | CarrierTrackingNumber |
上記のUPDATESTATISTICSステートメントをラップトップのSalesOrderDetailEnlargedテーブルに対してそれぞれ4回実行し、TestServerのSalesOrderDetailEnlargedテーブルに対してそれぞれ2回実行しました。ステートメントは毎回ランダムな順序で実行され、プロシージャキャッシュとバッファキャッシュは各更新ステートメントの前にクリアされました。ステートメントの各セットの期間とtempdbの使用量(平均)は、以下のグラフにあります。
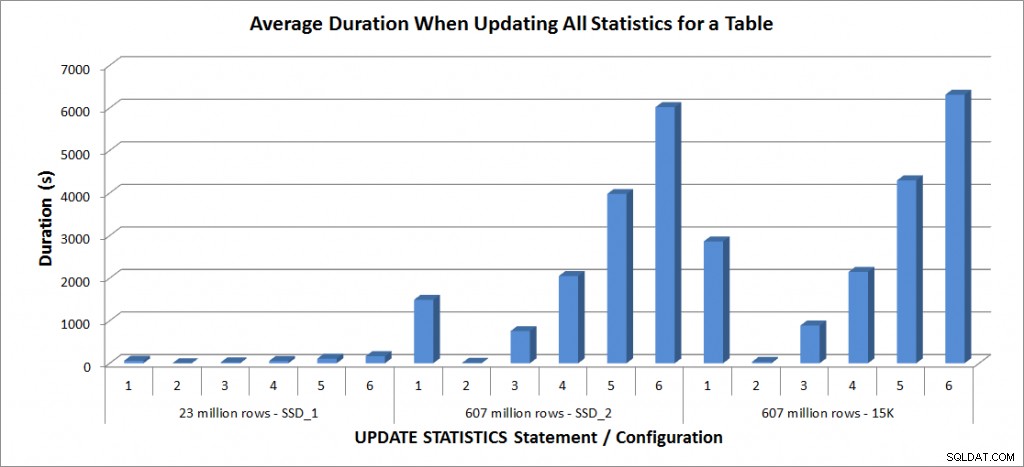
平均期間–SalesOrderDetailEnlargedのすべての統計を更新
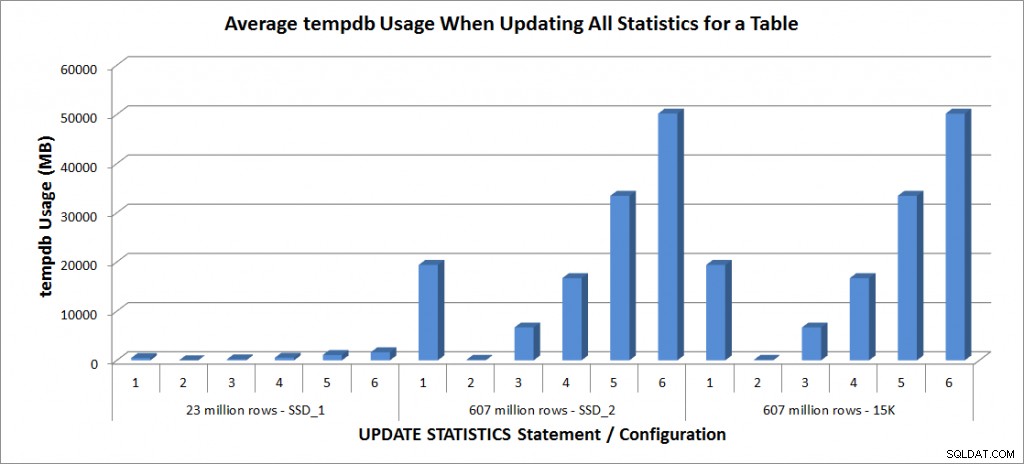
tempdb使用法–SalesOrderDetailEnlargedのすべての統計を更新
2,300万行のテーブルの所要時間はすべて3分未満であり、次のセクションで詳しく説明します。 SSD_2ディスク上のテーブルの場合、FULLSCANステートメントは1492秒(ほぼ25分)かかり、25%サンプルでの更新には2051秒(34分以上)かかりました。対照的に、15Kディスクでは、FULLSCANステートメントに2864秒(47分以上)かかり、25%サンプルでの更新に2147秒(ほぼ36分)かかりました。これは、FULLSCANの時間よりも短い時間です。ただし、50%のサンプルを使用した更新には4296秒(71分以上)かかりました。
Tempdbの使用ははるかに一貫しており、サンプルサイズが増加するにつれて着実に増加し、25%から50%の間のどこかでFULLSCANよりも多くのtempdbスペースを使用します。ここで注目すべきは、UPDATESTATISTICSが行うということです。 使用 tempdb。これは、SQLServer環境用にtempdbのサイズを設定するときに覚えておくことが重要です。 Tempdbの使用法は、UPDATESTATISTICSBOLエントリに記載されています。
UPDATE STATISTICSは、tempdbを使用して、統計を作成するために行のサンプルを並べ替えることができます。」
また、その効果は、Linchi Sheaの投稿「パフォーマンスへの影響:tempdbと更新の統計」に記載されています。ただし、tempdbのサイジングの議論で常に言及されるわけではありません。テーブルが大きく、FULLSCANまたは高いサンプル値で更新を実行する場合は、tempdbの使用法に注意してください。
選択的更新のパフォーマンス
次に、テーブルの他の統計についてUPDATE STATISTICSステートメントをテストすることにしましたが、テストは2,300万行のテーブルのコピーに限定しました。 UPDATE STATISTICSステートメントの上記の6つのバリエーションは、次の個々の統計に対してそれぞれ4回繰り返され、テーブル全体の更新と比較されました。
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
すべてのテストは私のラップトップで前述の構成で実行され、結果は下のグラフにあります:
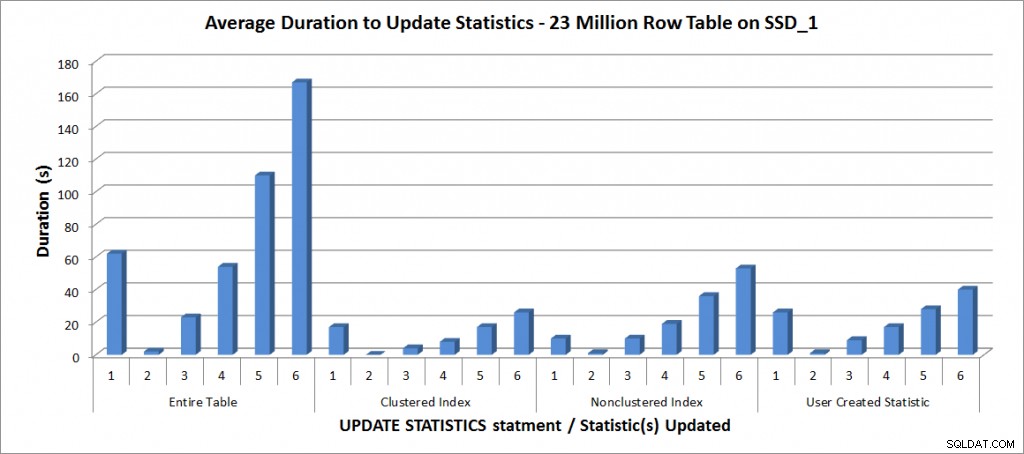
更新統計の平均期間–すべての統計と選択済み
予想どおり、個々の統計の更新には、テーブルのすべての統計を更新する場合よりも時間がかかりませんでした。サンプリングされた更新にかかった値は、FULLSCANが変化するよりも長くかかりました:
| テーブル全体 | 62 | 50%–110秒 |
| クラスター化されたインデックス | 17 | 75%–26秒 |
| 非クラスター化インデックス | 10 | 25%–19秒 |
| ユーザーが作成した統計 | 26 | 50%–28秒 |
結論
このデータと、6億700万行のテーブルのFULLSCANデータに基づくと、特定のはありません。 サンプリングされた更新がFULLSCANよりも長くかかる転換点。そのポイントは、テーブルのサイズと使用可能なリソースによって異なります。しかし、データはあることを示しているのでまだ価値があります サンプリングされた値がFULLSCANよりもキャプチャに時間がかかる可能性があるポイント。それはまたあなたのデータを知ることに帰着します。これは、テーブルに統計のカスタム管理が必要かどうかを理解するだけでなく、有用なヒストグラムを作成し、リソースの使用を最適化するための理想的なサンプルサイズを理解するためにも重要です。
仕様
ラップトップの仕様:Dell M6500、1つのIntel i7(2.13GHz 4コアおよびHTが有効になっているため8つの論理コア)、32 GBメモリ、Windows 7、SQL Server 2012 SP1(11.0.3128.0 x64)、265GBSamsungSSDに保存されたデータベースファイルPM810テストサーバーの仕様:Dell R720、2つのIntel E5-2670(2.6GHz 8コアおよびHTが有効になっているため、ソケットあたり16論理コア)、64 GBメモリ、Windows 2012、SQL Server 2012 SP1(11.0.3339.0 x64)、データベースファイル1つのテーブルは2つの640GBFusion-ioDuo MLCカードにあり、もう1つのテーブルのデータベースファイルはRAID5アレイの9つの15KRPMディスクにあります