
トランザクションログがハードディスクをどのように乗っ取ったかについて不満を言う人をよく見かけます。多くの場合、1つの大きなトランザクションで、データのパージやアーカイブなどの大規模な削除操作を実行していたことがわかります。
いくつかのテストを実行して、期間とトランザクションログの両方で、単一のトランザクションに対してチャンクで同じデータ操作を実行した場合の影響を示したいと思いました。データベースを作成し、大きなテーブルSalesOrderDetailEnlargedを入力しました) 、
テーブルにデータを入力した後、データベースをバックアップし、ログをバックアップして、DBCC SHRINKFILEを実行しました。 (私を撃たないでください)ログファイルへの影響をベースラインから確立できるようにします(これらの操作によってトランザクションログが大きくなることを十分に理解しています)。
SSDではなく意図的にメカニカルディスクを使用しました。 SSDに移行するというより一般的な傾向が見られるようになるかもしれませんが、それはまだ十分な規模では発生していません。多くの場合、大規模なストレージデバイスでこれを行うのは依然として法外な費用がかかります。
テスト
そこで次に、最大の影響をテストするために何をテストしたいかを決定する必要がありました。昨日、データをチャンクで削除することについて同僚と話し合ったので、削除を選択しました。また、このテーブルのクラスター化されたインデックスはSalesOrderIDにあるため 、私はそれを使いたくありませんでした–それは簡単すぎるでしょう(そして、実際の削除が処理される方法と一致することはめったにありません)。そこで、代わりに一連のProductIDを追跡することにしました。 値。これにより、多数のページにアクセスし、多くのログが必要になります。次のクエリで削除する製品を決定しました:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
これにより、次の結果が得られました。
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
これにより、456,960行(テーブルの約10%)が削除され、多くの注文に分散されます。これは、事前に計算された注文合計を台無しにし、すでに出荷された注文から製品を実際に削除することはできないため、このコンテキストでは現実的な変更ではありません。しかし、私たち全員が知っていて大好きなデータベースを使用することは、たとえば、フォーラムサイトからユーザーを削除し、すべてのメッセージを削除することに似ています。これは、私が実際に見た実際のシナリオです。
したがって、1つのテストは、次のワンショット削除を実行することです。
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
これには大規模なスキャンが必要になり、トランザクションログに多大な損害が発生することを私は知っています。それがポイントです。 :-)
それが実行されている間、私はこの削除をチャンクで実行する別のスクリプトをまとめました:一度に25,000、50,000、75,000、および100,000行。各チャンクは独自のトランザクションでコミットされ(スクリプトを停止する必要がある場合は、最初からやり直すのではなく、以前のすべてのチャンクがすでにコミットされているため)、リカバリモデルに応じてフォローされます。 CHECKPOINTのいずれかによって またはBACKUP LOG トランザクションログへの継続的な影響を最小限に抑えるため。 (これらの操作なしでもテストします。)これは次のようになります(このテストではエラー処理やその他の優れた機能に煩わされることはありませんが、それほど大げさなことはしないでください):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
もちろん、各テストの後で、データベースの元のバックアップをWITH REPLACE, RECOVERYで復元します。 、それに応じてリカバリモデルを設定し、次のテストを実行します。
結果
最初のテストの結果はまったく驚くべきものではありませんでした。 1つのステートメントで削除を実行するには、完全に42秒、単純に43秒かかりました。どちらの場合も、これによりログが579MBに増加しました。
次の一連のテストには、いくつかの驚きがありました。 1つは、これらのチャンク化方法はログファイルへの影響を大幅に削減しましたが、期間が近づいたのは2、3の組み合わせのみであり、実際に高速な組み合わせはありませんでした。もう1つは、一般に、完全リカバリでのチャンク化(ステップ間でログバックアップを実行しない)は、単純リカバリでの同等の操作よりもパフォーマンスが優れていることです。期間とログへの影響の結果は次のとおりです。
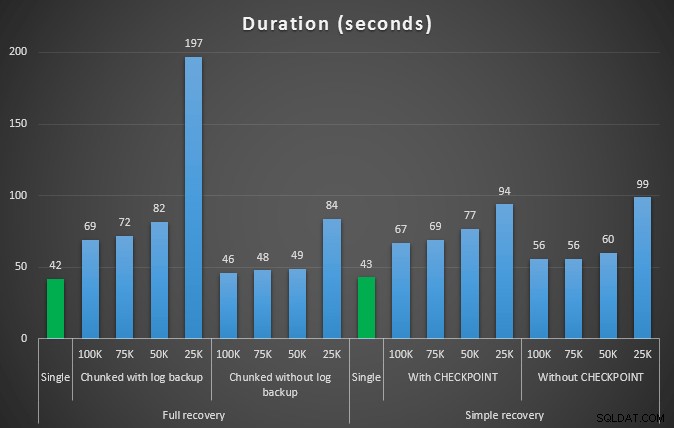
457K行を削除するさまざまな削除操作の期間(秒単位)
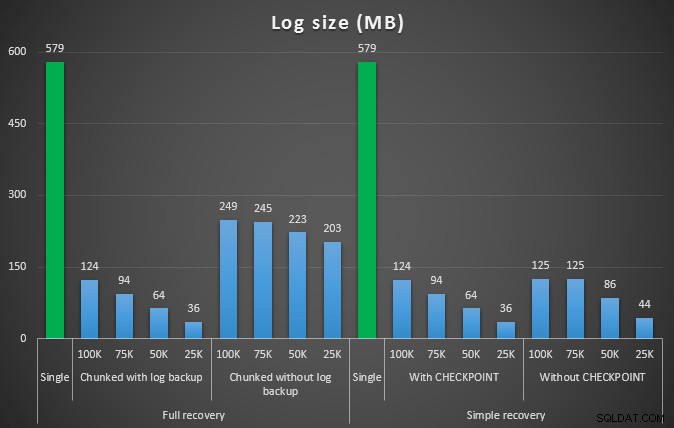
さまざまな削除操作で457K行を削除した後のログサイズ(MB単位)
この場合も、一般に、ログサイズは大幅に削減されますが、期間は長くなります。このタイプのスケールを使用して、ディスクスペースへの影響を減らすことがより重要であるか、または費やされる時間を最小限に抑えることがより重要であるかを判断できます。期間がわずかにヒットした場合(そして結局のところ、これらのプロセスのほとんどはバックグラウンドで実行されます)、ログスペースの使用量を大幅に節約できます(これらのテストでは最大94%)。
圧縮を有効にしてこれらのテストを試しなかったことに注意してください(おそらく将来のテストです!)。ログの自動拡張設定をひどいデフォルト(10%)のままにしました。一部は怠惰であり、一部はそこにある多くの環境が保持されているためです。このひどい設定。
しかし、もっとデータがある場合はどうなりますか?
次に、少し大きいデータベースでこれをテストする必要があると思いました。そこで、別のデータベースを作成し、dbo.SalesOrderDetailEnlargedの新しい大きなコピーを作成しました。 。実際、約10倍の大きさです。今回は、SalesOrderID, SalesorderDetailIDの主キーの代わりに 、(重複を許可するために)クラスター化されたインデックスを作成し、次のように入力しました:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); ディスクスペースの制限のため、このテストではラップトップのVMから移動する必要がありました(そして、128 GBのRAMを搭載した40コアのボックスを選択しましたが、たまたま準アイドル状態でした:-))、それでもそれは決して迅速なプロセスではありませんでした。テーブルの作成とインデックスの作成には最大24分かかりました。
このテーブルには4,850万行あり、ディスクで7.9 GBを占めます(データで4.9 GB、インデックスで2.9 GB)。
今回は、候補のProductIDの適切なセットを決定するためのクエリ 削除する値:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
次の結果が得られました:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
したがって、テーブルの10%弱の4,455,360行を削除します。上記のテストと同様のパターンに従って、すべてを1回のショットで削除し、次に500,000、250,000、および100,000行のチャンクで削除します。
結果:
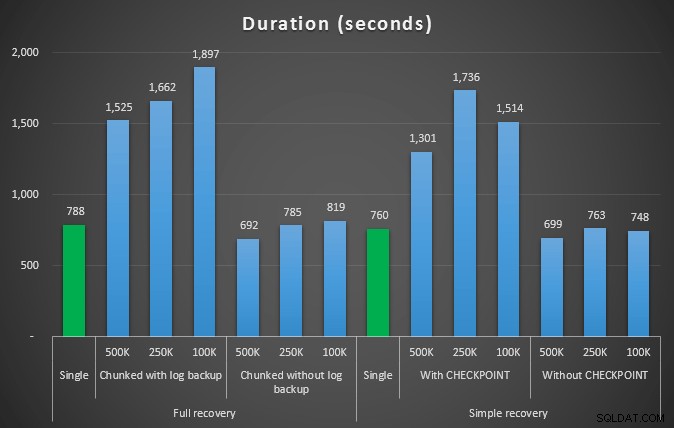 4.5MM行を削除するさまざまな削除操作の時間(秒単位)
4.5MM行を削除するさまざまな削除操作の時間(秒単位)
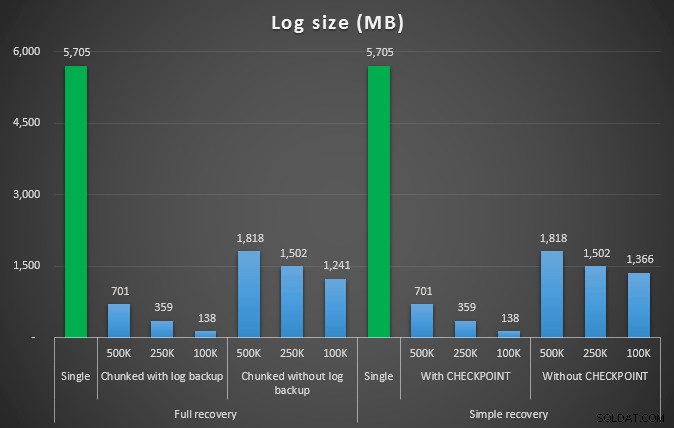 4.5MM行を削除するさまざまな削除操作後のログサイズ(MB単位)>
4.5MM行を削除するさまざまな削除操作後のログサイズ(MB単位)>
繰り返しになりますが、ログファイルサイズが大幅に削減されています(最小チャンクサイズが100Kの場合は97%以上)。ただし、この規模では、発生したはずのすべての自動拡張イベントを使用しても、より短い時間で削除を実行できる場合がいくつかあります。それは私にはwin-winのようにひどく聞こえます!
今回はログが大きくなります
さて、私はこれらの異なる削除が、そのような大規模な操作に対応するために事前にサイズ設定されたログファイルとどのように比較されるのか興味がありました。大規模なデータベースを使用して、ログファイルを6 GBに事前拡張し、バックアップしてから、テストを再実行しました。
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
結果、固定ログファイルを使用した期間と、ファイルを継続的に自動拡張する必要がある場合との比較:
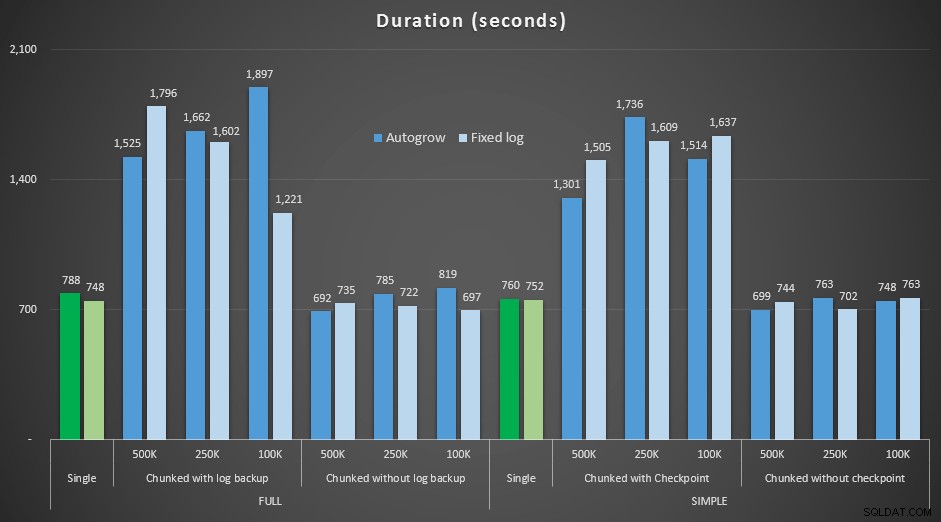
4.5MM行を削除するさまざまな削除操作の期間(秒単位) 、固定ログサイズと自動拡張の比較
ここでも、チャンクがバッチに削除し、各ステップの後にログバックアップまたはチェックポイントを実行しない*メソッドは、期間の点で同等の単一操作に匹敵することがわかります。実際、ほとんどの場合、全体的な時間は短く、他のトランザクションがステップ間で出入りできるというボーナスが追加されていることを確認してください。この削除操作で関連のないすべてのトランザクションをブロックする必要がない限り、これは良いことです。
結論
この問題に対する単一の正しい答えがないことは明らかです–固有の「依存する」変数がたくさんあります。ログのバックアップにかかるオーバーヘッドと、さまざまなチャンクサイズで節約できる作業と時間のバランスが取れているため、マジックナンバーを見つけるには多少の実験が必要になる場合があります。ただし、多数の行を削除またはアーカイブすることを計画している場合は、全体として、1つの大規模なトランザクションではなく、チャンクで変更を実行する方が適切である可能性が高くなります。そのあまり魅力的な操作。期間だけではありません。十分に事前に割り当てられたログファイルがなく、そのような大規模なトランザクションに対応するスペースがない場合は、期間を犠牲にしてログファイルの増加を最小限に抑える方がはるかに優れています。この場合、上記の期間グラフを無視して、ログサイズグラフに注意を払う必要があります。
スペースに余裕がある場合でも、それに応じてトランザクションログのサイズを事前に設定することをお勧めします。シナリオによっては、デフォルトの自動拡張設定を使用すると、十分なスペースのある固定ログファイルを使用するよりもテストでわずかに速くなることがありました。さらに、まだ実行していない大規模なトランザクションに対応するために必要な金額を正確に推測するのは難しい場合があります。現実的なシナリオをテストできない場合は、最悪のシナリオを描くために最善を尽くしてください。次に、安全のために、それを2倍にします。 Kimberly Tripp(ブログ| @KimberlyLTripp)は、この投稿でいくつかの優れたアドバイスを提供しています。トランザクションログのスループットを向上させるための8つのステップ–このコンテキストでは、具体的には、ポイント#6を見てください。ログスペース要件の計算方法に関係なく、とにかくスペースが必要になる場合は、自動成長を待つ間にビジネスプロセスを停止するよりも、事前に制御された方法でスペースを取得することをお勧めします(複数を気にしないでください!)
私が明示的に測定しなかったこれのもう1つの非常に重要な側面は、並行性への影響です。理論的には、多数の短いトランザクションは並行操作への影響が少なくなります。 1回の削除にかかる時間は、より長いバッチ操作よりもわずかに短くなりますが、その期間全体にわたってすべてのロックが保持され、チャンク操作では、キューに入れられた他のトランザクションが各トランザクションの間に忍び込むことができます。将来の投稿では、この影響を詳しく調べてみます(そして、他のより深い分析も計画しています)。