クエリの調整に非常に役立つ2つの補完的なスキルがあります。 1つは、実行計画を読み取って解釈する機能です。 2つ目は、クエリオプティマイザがSQLテキストを実行プランに変換する方法について少し知っていることです。 2つのことを組み合わせると、期待される最適化が適用されなかった時間を特定するのに役立ち、実行計画が可能な限り効率的ではなくなります。ただし、SQL Serverが適用できる最適化(およびその状況)に関するドキュメントが不足しているということは、その多くが経験に基づいていることを意味します。
例
この記事のサンプルクエリは、SQL ServerMVPのFabianoAmorimが遭遇した実際の問題に基づいて、数か月前に尋ねた質問に基づいています。以下のスキーマとテストクエリは実際の状況を単純化したものですが、すべての重要な機能を保持しています。
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; テスト1– 10,000行、SQL Server 2005+
これらのテストでは、特定のテーブルデータは実際には重要ではありません。次のクエリは、数値テーブルから3つのテストテーブルのそれぞれに10,000行をロードするだけです。
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
データが読み込まれると、テストクエリ用に作成された実行プランは次のようになります。
SELECT MAX(c1) FROM dbo.V1;
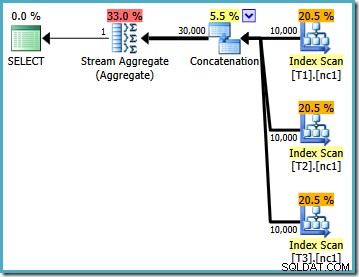
この実行プランは、論理SQLクエリのかなり直接的な実装です(ビュー参照V1が展開された後)。オプティマイザは、クエリが完全に書き出されたかのように、ビューの拡張後にクエリを確認します。
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
拡張されたテキストを実行プランと比較すると、クエリオプティマイザの実装の直接性は明らかです。ベーステーブルの読み取りごとにインデックススキャンがあり、UNION ALLを実装するための連結演算子があります。 、および最終的なMAXのStreamAggregate 集計。
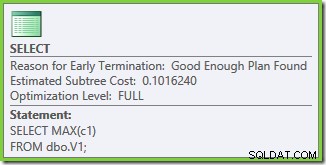
実行プランのプロパティは、コストベースの最適化が開始されたことを示しています(最適化レベルはFULL )が、「十分に良い」計画が見つかったため、早期に終了しました。選択したプランの推定コストは0.1016240 マジックオプティマイザーユニット。
テスト2– 50,000行、SQLServer2008および2008R2
次のスクリプトを実行して、50,000行で実行するようにテスト環境をリセットします。
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
このテストの実行プランは、実行しているSQLServerのバージョンによって異なります。 SQL Server2008および2008R2では、次の計画があります。
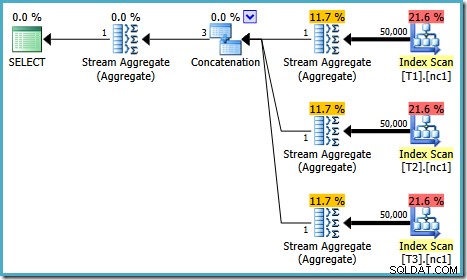
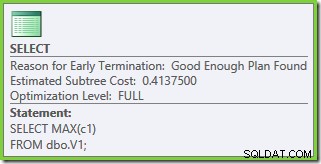
計画のプロパティは、コストベースの最適化が以前と同じ理由でまだ早期に終了したことを示しています。推定コストは以前よりも高くなり、 0.41375 ユニットですが、ベーステーブルのカーディナリティが高いために予想されます。
テスト3– 50,000行、SQLServer2005および2012
2005または2012で同じクエリを実行すると、異なる実行プランが生成されます。
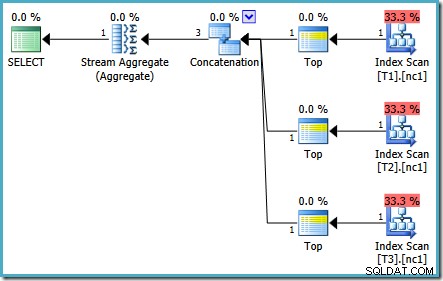
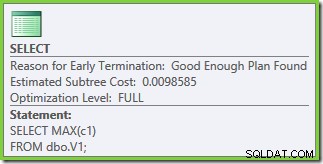
最適化は再び早期に終了しましたが、ベーステーブルあたり50,000行の推定計画コストは 0.0098585に低下しています。 ( 0.41375から SQL Server2008および2008R2の場合)。
説明
ご存知かもしれませんが、SQL Serverクエリオプティマイザーは、最適化の作業を複数の段階に分割し、後の段階でより多くの最適化手法を追加して、より多くの時間を許可します。最適化の段階は次のとおりです。
- 重要な計画
- コストベースの最適化
- トランザクション処理(検索0)
- クイックプラン(検索1)
- 並列処理を有効にしたクイックプラン
- 完全最適化(検索2)
アグリゲートとユニオンには複数の実装の可能性があり、コストベースの決定が必要なため、ここで実行されるテストはどれも簡単な計画の対象にはなりません。
トランザクション処理
トランザクション処理(TP)ステージでは、クエリに少なくとも3つのテーブル参照が含まれている必要があります。含まれていない場合、コストベースの最適化はこのステージをスキップして、クイックプランに直接進みます。 TPステージは、OLTPワークロードに典型的な低コストのナビゲーションクエリを対象としています。限られた数の最適化手法を試し、ネストされたループ結合を使用した計画の検索に限定されます(有効な計画を生成するためにハッシュ結合が必要な場合を除く)。
いくつかの点で、テストクエリがOLTPプランを見つけることを目的としたステージに適格であることは驚くべきことです。クエリには必要な3つのテーブル参照が含まれていますが、結合は含まれていません。 3つのテーブルの要件は単なるヒューリスティックであるため、要点を説明しません。
どのオプティマイザーステージが実行されましたか?
いくつかの方法がありますが、文書化されている方法は、コンパイルの前後でsys.dm_exec_query_optimizer_infoの内容を比較することです。これは問題ありませんが、インスタンス全体の情報が記録されるため、スナップショット間で発生するクエリのコンパイルは自分のものだけであることに注意する必要があります。
現在サポートされているすべてのバージョンのSQLServerで機能する、文書化されていない(ただし、かなりよく知られている)代替手段は、クエリのコンパイル中にトレースフラグ8675および3604を有効にすることです。
テスト1
このテストでは、次のようなトレースフラグ8675出力が生成されます。

TPステージ後の推定コスト0.101624は十分に低いため、オプティマイザーはより安価なプランを探し続けません。真に最適ではない場合でも、ベーステーブルのカーディナリティが比較的低いことを考えると、最終的に得られる単純な計画は非常に合理的です。
テスト2
各ベーステーブルに50,000行あるため、トレースフラグはさまざまな情報を示します。

今回は、TPステージ後の推定コストは 0.428735 (より多くの行=より高いコスト)。これは、オプティマイザをクイックプランの段階に進めるのに十分です。より多くの最適化手法が利用可能であるため、この段階では、コストが 0.41375の計画を見つけます。 。これは、テスト1の計画に比べて大幅な改善を表すものではありませんが、並列処理のデフォルトのコストしきい値よりも低く、完全最適化に入るには不十分であるため、最適化は早期に終了します。
テスト3
SQL Server 2005および2012の実行の場合、トレースフラグの出力は次のとおりです。

バージョン間で実行されるタスクの数にはわずかな違いがありますが、重要な違いは、SQL Server 2005と2012では、クイックプランステージでコストが 0.0098543のプランしか検出されないことです。 ユニット。これは、SQLServer2008および2008R2プランで見られる連結演算子の下の3つのストリーム集約の代わりにトップ演算子を含むプランです。
バグと文書化されていない修正
SQL Server2008および2008R2には、トレースフラグ4199で修正された(2005と比較した)リグレッションバグが含まれていますが、私が知る限り、文書化されていません。 TF 4199のドキュメントには、4199でカバーされる前に個別のトレースフラグで利用可能になった修正がリストされていますが、ナレッジベースの記事にあるように:
この1つのトレースフラグを使用して、多くのトレースフラグの下でクエリプロセッサに対して以前に行われたすべての修正を有効にすることができます。 さらに、今後のクエリプロセッサの修正はすべて、このトレースフラグを使用して制御されます。
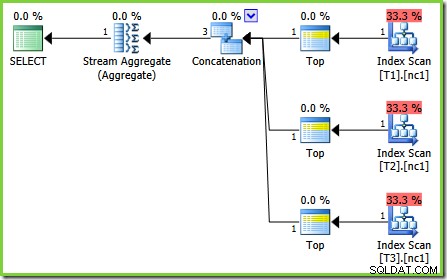
この場合のバグは、「将来のクエリプロセッサの修正」の1つです。特定の最適化ルール、 ScalarGbAggToTop 、は、テスト2プランで見られる新しい集計には適用されません。 SQL Server2008および2008R2の適切なビルドでトレースフラグ4199を有効にすると、バグが修正され、テスト3から最適な計画が取得されます。
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
結論
オプティマイザーがスカラーMINを変換できることがわかったら またはMAX TOP (1)に集約 順序付けられたストリームでは、テスト2に示されている計画は奇妙に見えます。インデックススキャンの上のスカラー集計(要求された場合に順序を提供できます)は、通常適用される最適化の失敗として際立っています。
これが私がイントロダクションで述べたポイントです。オプティマイザが実行できることの種類を理解すると、何かがうまくいかなかったケースを認識するのに役立ちます。
まだ修正されていない問題に遭遇する可能性があるため、答えは必ずしもトレースフラグ4199を有効にすることではありません。また、特定の場合に、トレースフラグでカバーされる他のQP修正を適用したくない場合もあります。オプティマイザー修正は、必ずしも状況を改善するとは限りません。もしそうなら、このフラグを使用して不幸な計画の後退から保護する必要はありません。
他の場合の解決策は、異なる構文を使用してSQLクエリを定式化するか、クエリをよりオプティマイザに適したチャンクに分割するか、またはまったく別のものにすることです。答えが何であれ、オプティマイザーの内部について少し知っておくと、そもそも問題があったことを認識できます:)