私が数週間前に私たちのイマージョンイベントの1つのためにシカゴにいたとき、出席者は統計に関する質問をしました。この問題に関する詳細については詳しく説明しませんが、出席者は、統計がsp_updatestatsを使用して更新されたと述べました。 。これは、私が推奨したことのない統計を更新する方法です。私は常にインデックスの再構築とUPDATE STATISTICSの組み合わせを推奨してきました 統計を最新に保つため。 sp_updatestatsに慣れていない場合 、これはデータベース全体に対して実行されるコマンドであり、統計を更新します。しかし、キンバリーが出席者に指摘したように、sp_updatestats 1つの行が変更されている限り、統計を更新します。うわあ。私はすぐにBooksOnlineを開き、sp_updatestats これが表示されます:
ここで、「…sys.sysindexesカタログビューのrowmodctr情報に基づいて更新する必要がある…」とはどういう意味かを推測しました。更新の決定は、[統計の自動更新]オプションが従うのと同じロジックに従うと想定しました。これは次のとおりです。
- テーブルサイズが0行から>0行になりました(テスト1)。
- 統計が収集されたときのテーブルの行数は500以下であり、それ以降、統計オブジェクトの先頭の列の列が500を超えて変更されています(テスト2)。
- 統計が収集されたときにテーブルに500を超える行があり、統計オブジェクトの先頭の列の列が、統計が収集されたときにテーブルの行数の500 + 20%を超えて変更されました(テスト3)。
sp_updatestatsでは、このロジックには従いません。 。実際、ロジックは非常に単純で、怖いです。1つの行が変更されると、統計が更新されます。 1行。一列。私の懸念は何ですか?本当に更新する必要のない一連の統計の統計を更新するオーバーヘッドが心配です。 sp_updatestatsを詳しく見てみましょう 。
まず、CodeplexからダウンロードできるAdventureWorks2012データベースの新しいコピーから始めます。最初に、3つの異なるテーブルの行を更新します。
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
Production.Productの1行を変更しました 、Person.Personの211行 、およびSales.SalesReasonに10,000行を追加しました 。 sp_updatestatsの場合 手順は、統計の自動更新オプションと同じ更新ロジックに従い、Sales.SalesReasonのみを実行しました。 開始する行が10行あるため更新されます(Person.Personで更新された211行に対して 表の約1パーセントに相当します)。ただし、sp_updatestatsを掘り下げると 、使用されるロジックが異なることがわかります。 sp_updatestats内からのみステートメントを抽出していることに注意してください 更新される統計を決定するために使用されます。
カーソルは、データベース内のすべてのユーザー定義テーブルと内部テーブルを繰り返し処理します。
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
別のカーソルが各テーブルの統計をループし、ヒープと仮想インデックスおよび統計を除外します。 sys.sysindexesに注意してください sp_helpstatsで使用されます 。 Sysindexes はSQLServer2000システムテーブルであり、SQLServerの将来のバージョンで削除される予定です。更新された行を判別する他の方法はsys.dm_db_stats_propertiesであるため、これは興味深いことです。 DMF。SQL2008R2SP2およびSQL2012SP1でのみ使用できます。
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
少し準備と追加のロジックを実行した後、IFに到達します。 そのsp_updatestatsを明らかにするステートメント 行が更新されていない統計を除外します…1行だけが変更された場合でも、統計が更新されることを確認します。 @is_ver_currentのチェックもあります 、組み込みの内部関数によって決定されます。
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
サンプリングと互換性レベルに関連するいくつかのチェック、そしてUPDATE ステートメントは統計に対して実行されます。 sp_updatestatsを実際に実行する前に、sys.sysindexesにクエリを実行できます。 更新される統計を確認するには:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
変更した3つのテーブルに加えて、ユーザーテーブルの別の統計(dbo.DatabaseLog)があります。 )および更新される3つの内部統計:
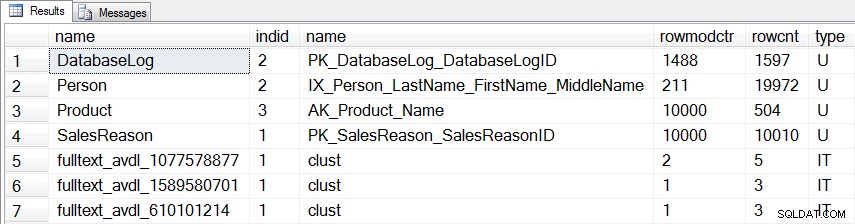
sp_updatestatsを実行した場合 AdventureWorksデータベースの場合、出力にはすべてのテーブルと更新された統計が一覧表示されます。以下の出力は、更新された統計のみを表示するように変更されています。
[sys]を更新しています。[fulltext_avdl_1589580701]
[clust]が更新されました…
1つのインデックス/統計が更新されました。0は更新の必要がありませんでした。
…
[dbo]。[DatabaseLog]を更新しています
[PK_DatabaseLog_DatabaseLogID]が更新されました…
1つのインデックス/統計が更新されました。0は更新の必要がありませんでした。
…
[sys]を更新しています。[fulltext_avdl_1077578877]
[clust]が更新されました…
1つのインデックス/統計が更新されました。0は更新の必要がありませんでした。
…
[Person]を更新しています。[Person]
[PK_Person_BusinessEntityID]、更新は必要ありません…
[IX_Person_LastName_FirstName_MiddleName]が更新されました…
[AK_Person_rowguid]、更新は必要ありません…
1インデックス/統計が更新されました。2つは更新の必要がありませんでした。
…
[Sales]を更新しています。[SalesReason]
[PK_SalesReason_SalesReasonID]が更新されました…
1つのインデックス/統計が更新されました。0は更新の必要がありませんでした。
…
[Production]。[Product]
[PK_Product_ProductID]を更新しています、更新は必要ありません…
[AK_Product_ProductNumber]、更新は必要ありません…
[AK_Product_Name]が更新されました…
[ AK_Product_rowguid]、更新は必要ありません…
[_WA_Sys_00000013_75A278F5]、更新は必要ありません…
[_WA_Sys_00000014_75A278F5]、更新は必要ありません…
[_WA_Sys_0000000D_75A278F5]、更新は必要ありません…
[_ WA_Sys_0000000C_75A278F5]、更新は必要ありません…
1つのインデックス/統計が更新されました。7つは更新する必要がありませんでした。
…
すべてのテーブルの統計が更新されました。
出力の最後の行は少し誤解を招く可能性があります。すべてのテーブルの統計は更新されておらず、1行以上変更された統計のみが更新されています。繰り返しになりますが、その欠点は、必要のないリソースが使用された可能性があることです。統計で変更された行が1つだけの場合、更新する必要がありますか?いいえ。10,000行が更新されている場合、更新する必要がありますか?まあ、それは異なります。テーブルに5,000行しかない場合は、絶対に。テーブルに100万行ある場合は、テーブルの1%しか変更されていないため、いいえ。
ここでのポイントは、sp_updatestatsを使用している場合です。 統計を更新するには、CPU、I / O、tempdbなどのリソースを浪費している可能性があります。さらに、各統計の更新には時間がかかります。メンテナンスウィンドウが狭い場合は、不要な更新ではなく、その時間内に実行できる他のメンテナンスタスクがある可能性があります。最後に、変更された行が非常に少ない場合に統計を更新しても、パフォーマンス上のメリットはおそらく得られません。変更された行の割合が少ない場合、分布の変化は重要ではない可能性が高いため、ヒストグラムと密度の値はそれほど変化しません。さらに、統計を更新すると、それらの統計を使用するクエリプランが無効になることに注意してください。これらのクエリが実行されると、計画が再生成されます。ヒストグラムに大きな変化がなかったため、計画は以前とまったく同じになる可能性があります。クエリプランを再コンパイルするにはコストがかかります。測定は必ずしも簡単ではありませんが、無視してはなりません。
統計を管理するためのより良い方法は、統計を管理する必要があるため、変更された行のパーセンテージに基づいて更新されるスケジュールされたジョブを実装することです。 sys.sysindexesに問い合わせる前述のクエリを使用できます 、またはSQL Server 2008R2SP2およびSQLServer2012 SP1で追加された新しいDMFを利用する以下のクエリを使用できます:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
テーブルが異なればしきい値も異なる可能性があり、データベースに対して上記のクエリを微調整する必要があることに注意してください。一部のテーブルでは、行の15%または20%が変更されるまで待機しても問題ない場合があります。ただし、実際の値とそのスキューに応じて、10%または5%で更新する必要がある場合もあります。特効薬はありません。絶対値が大好きなのと同じように、絶対値がSQL Serverに存在することはめったになく、統計も例外ではありません。それでも、自動更新統計を有効のままにしておきたい場合は、データベースファイルの自動拡張のように、何かを見逃した場合に安全に機能します。ただし、最善の策は、データを把握し、変更された行の割合に基づいて統計を更新できる方法を実装することです。