背景
パフォーマンスの問題のトラブルシューティングを行うときに最初に確認することの1つは、sys.dm_os_wait_statsDMVを介した待機統計です。 SQL Serverが待機しているものを確認するには、GlennBerryの現在のSQLServer診断クエリセットからのクエリを使用します。出力に応じて、SQLServer内の特定の領域を掘り下げ始めます。
例として、CXPACKETの待機時間が長い場合は、サーバー上のコアの数、NUMAノードの数、および並列処理の最大度と並列処理のコストしきい値の値を確認します。これは、構成を理解するために使用する背景情報です。変更を加えることを検討する前に、もっとを収集します CXPACKET待機を備えたシステムでは、最大並列度の設定が必ずしも正しくないため、定量的データ。
同様に、PAGEIOLATCH_XX、WRITELOG、IO_COMPLETIONなどのI / O関連の待機タイプの待機が多いシステムは、必ずしも劣ったストレージサブシステムを備えているとは限りません。最上位の待機としてI/O関連の待機タイプが表示されたら、すぐに基盤となるストレージについて詳しく知りたいと思います。直接接続ストレージですか、それともSANですか? RAIDレベル、アレイに存在するディスクの数、およびディスクの速度はどれくらいですか?他のファイルやデータベースがストレージを共有しているかどうかも知りたいです。構成を理解することは重要ですが、論理的な次のステップは、sys.dm_io_virtual_file_statsDMVを介して仮想ファイルの統計を確認することです。
SQL Server 2005で導入されたこのDMVは、SQLServer2000以前で実行したことがある人がおそらく知っていて気に入っているfn_virtualfilestats関数の代わりになります。 DMVには、各データベースファイルの累積I / O情報が含まれていますが、データベースが閉じられたり、オフラインになったり、切り離されたり、再接続されたりすると、インスタンスの再起動時にデータがリセットされます。仮想ファイルの統計データは現在のデータを表していないことを理解することが重要です。パフォーマンス–前述のイベントの1つによる最後のクリア以降のI/Oデータの集約であるスナップショットです。データは特定の時点ではありませんが、それでも有用な場合があります。インスタンスの最大待機時間がI/O関連であるが、平均待機時間が10ミリ秒未満の場合、ストレージはおそらく問題ではありませんが、出力をsys.dm_io_virtual_statsに表示されるものと相関させることは、低いことを確認する価値があります。レイテンシー。さらに、sys.dm_io_virtual_statsに高い遅延が見られる場合でも、ストレージが問題であることを証明していません。
セットアップ
仮想ファイルの統計を確認するために、AdventureWorks2012データベースの2つのコピーを設定しました。これは、Codeplexからダウンロードできます。最初のコピー(以降EX_AdventureWorks2012と呼びます)では、Jonathan Kehayiasのスクリプトを実行して、Sales.SalesOrderHeaderテーブルとSales.SalesOrderDetailテーブルをそれぞれ120万行と490万行に拡張しました。 2番目のデータベースであるBIG_AdventureWorks2012では、以前のパーティショニング投稿のスクリプトを使用して、1億2300万行のSales.SalesOrderHeaderテーブルのコピーを作成しました。両方のデータベースは外部USBドライブ(Seagate Slim 500GB)に保存され、tempdbはローカルディスク(SSD)に保存されていました。
テストする前に、各データベース(Create_Custom_SPs.zip)に4つのカスタムストアドプロシージャを作成しました。これは、「通常の」ワークロードとして機能します。私のテストプロセスは、データベースごとに次のとおりでした。
- インスタンスを再起動します。
- 仮想ファイルの統計情報を取得します。
- 「通常の」ワークロードを2分間実行します(PowerShellスクリプトを介して繰り返し呼び出される手順)。
- 仮想ファイルの統計情報を取得します。
- 適切なSalesOrderテーブルのすべてのインデックスを再構築します。
- 仮想ファイルの統計情報を取得します。
データ
仮想ファイルの統計を取得するために、履歴情報を保持するテーブルを作成し、スナップショットにDMVAll-StarsスクリプトからのJimmyMayのクエリのバリエーションを使用しました。
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; インスタンスを再起動し、すぐにファイル統計をキャプチャしました。 EX_AdventureWorks2012およびtempdbデータベースファイルのみを表示するように出力をフィルタリングすると、EX_AdventureWorks2012データベースからデータが要求されていないため、tempdbデータのみがキャプチャされました。

sys.dm_os_virtual_file_statsの初期キャプチャからの出力
次に、「通常の」ワークロードを2分間実行し(各ストアドプロシージャの実行回数はわずかに異なります)、キャプチャされたファイルの統計を再度完了した後:

通常のワークロード後のsys.dm_os_virtual_file_statsからの出力
EX_AdventureWorks2012データファイルの遅延は57ミリ秒です。理想的ではありませんが、私の通常のワークロードでは、時間の経過とともに、これはおそらく均等になるでしょう。 tempdbのレイテンシは最小限です。これは、実行したワークロードがtempdbアクティビティをあまり生成しないために予想されます。次に、Sales.SalesOrderHeaderEnlargedテーブルとSales.SalesOrderDetailEnlargedテーブルのすべてのインデックスを再構築しました:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
再構築には1分もかからず、EX_AdventureWorks2012データファイルの読み取りレイテンシーの急上昇と、EX_AdventureWorks2012データおよびの書き込みレイテンシーの急上昇に気づきました。 ログファイル:

ファイル統計のスナップショットによると、待ち時間はひどいものです。書き込みに600ms以上!実動システムでこの値を見た場合、ストレージの問題をすぐに疑うのは簡単です。ただし、AvgBPerWriteも増加し、ブロック書き込みが大きくなると完了までに時間がかかることにも注意してください。インデックス再構築タスクでは、AvgBPerWriteの増加が見込まれます。
このデータを見ると、完全な全体像が得られていないことを理解してください。仮想ファイルの統計を使用して待機時間を確認するためのより良い方法は、スナップショットを作成してから、経過時間の待機時間を計算することです。たとえば、以下のスクリプトは2つのスナップショット(現在と前)を使用して、その期間の読み取りと書き込みの数、io_stall_read_ms値とio_stall_write_ms値の差を計算し、io_stall_read_msデルタを読み取り数で除算し、io_stall_write_msデルタを次のように除算します。書き込みの数。この方法では、SQLServerが読み取りまたは書き込みのI/ Oを待機していた時間を計算し、それを読み取りまたは書き込みの数で割って待機時間を決定します。
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
これを実行してインデックスの再構築中のレイテンシを計算すると、次のようになります。

EX_AdventureWorks2012のインデックス再構築中にsys.dm_io_virtual_file_statsから計算されたレイテンシ
これで、その間の実際のレイテンシーが高かったことがわかります。これは予想どおりです。その後、通常のワークロードに戻って数時間実行すると、仮想ファイルの統計から計算された平均値は時間の経過とともに減少します。実際、テスト中にキャプチャされた(その後、PALで処理された)PerfMonデータを見ると、平均で大幅なスパイクが見られます。ディスク秒/読み取りおよび平均インデックスの再構築が実行されていた時間に相関するディスク秒/書き込み。ただし、それ以外の場合、レイテンシ値は許容値を大幅に下回っています。
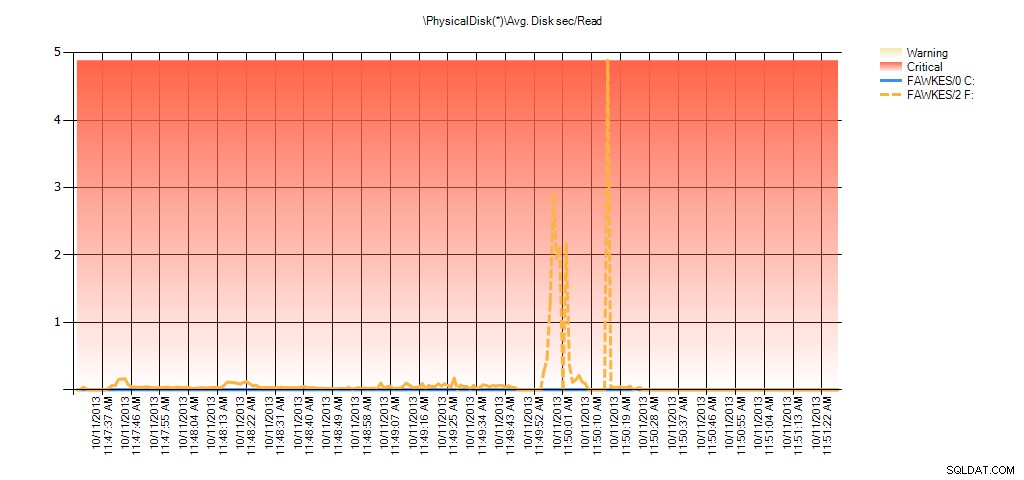
テスト中のEX_AdventureWorks2012の平均ディスク秒/PALからの読み取りの概要
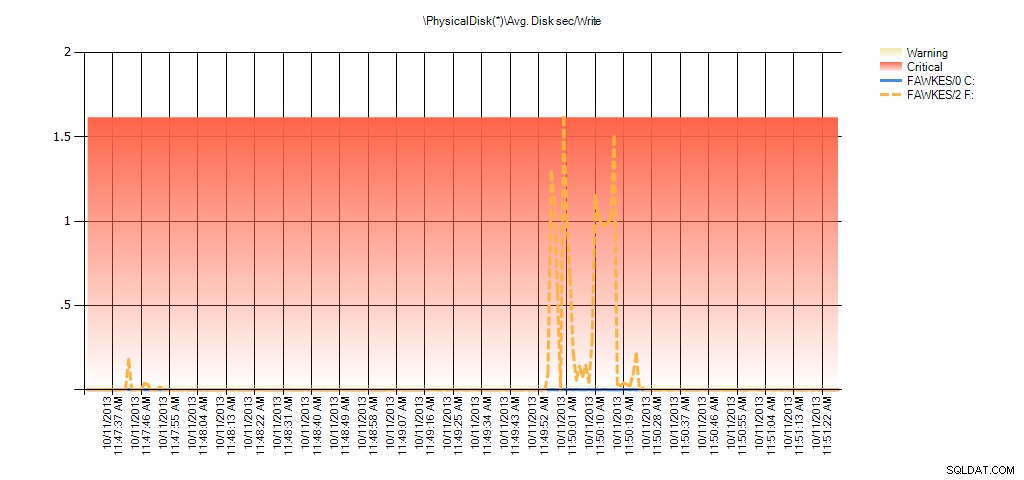
テスト中のEX_AdventureWorks2012のPALからの平均ディスク秒/書き込みの概要
BIG_AdventureWorks2012データベースでも同じ動作を確認できます。インデックスの再構築前と再構築後の仮想ファイル統計スナップショットに基づくレイテンシ情報は次のとおりです。

BIG_AdventureWorks2012のインデックス再構築中にsys.dm_io_virtual_file_statsから計算されたレイテンシ
また、パフォーマンスモニターのデータは、再構築中に同じスパイクを示しています。
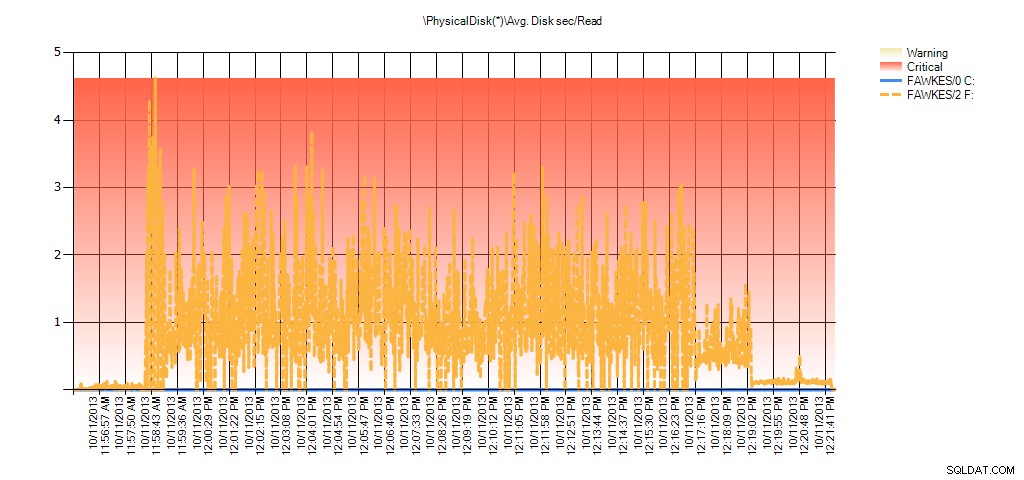
テスト中のBIG_AdventureWorks2012の平均ディスク秒/PALからの読み取りの概要
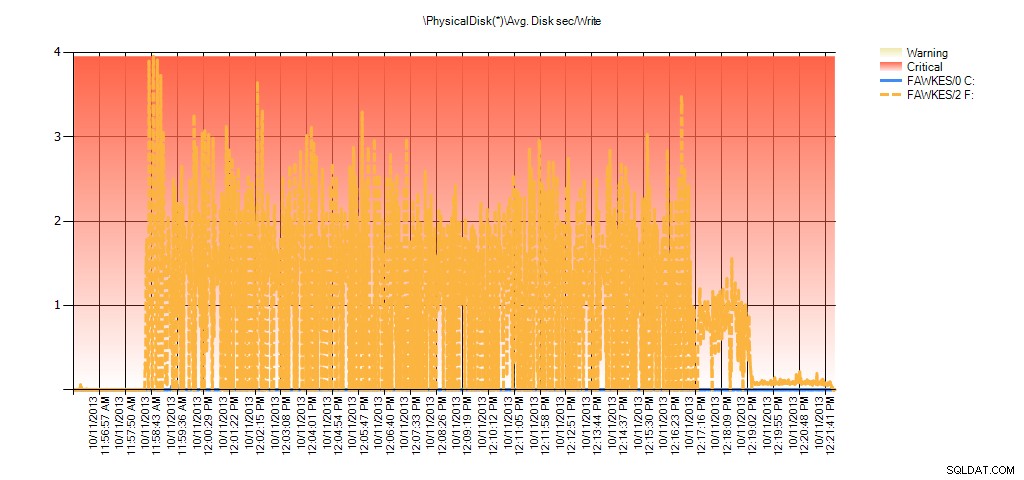
テスト中のBIG_AdventureWorks2012のPALからの平均ディスク秒/書き込みの概要
結論
仮想ファイルの統計は、SQLServerインスタンスのI/Oパフォーマンスを理解するための優れた出発点です。待機統計を確認するときにI/O関連の待機が表示される場合は、sys.dm_io_virtual_file_statsを確認することが論理的な次のステップです。ただし、表示しているデータは集計であることを理解してください 関連するイベント(インスタンスの再起動、データベースのオフラインなど)のいずれかによって統計が最後にクリアされてから。レイテンシが低い場合は、I/Oサブシステムがパフォーマンスの負荷に対応しています。ただし、待ち時間が長い場合は、ストレージが問題であるというのは当然の結論ではありません。何が起こっているのかを実際に知るには、ここに示すようにファイル統計のスナップショットを開始するか、パフォーマンスモニターを使用してリアルタイムでレイテンシーを確認することができます。物理ディスクカウンターの平均をキャプチャするデータコレクターセットをPerfMonで作成するのは非常に簡単です。ディスク秒/読み取りおよび平均データベースファイルをホストするすべてのディスクのディスク秒/読み取り。データコレクターを定期的に開始および停止するようにスケジュールし、 nごとにサンプリングします 秒(例:15)で、適切な時間PerfMonデータをキャプチャしたら、それをPALで実行して、時間の経過に伴う遅延を調べます。
I / Oレイテンシが、I / Oを駆動するメンテナンスタスク中だけでなく、通常のワークロード中に発生することがわかった場合でも、 根本的な問題としてストレージを指摘することはできません。ストレージの待ち時間は、次のようなさまざまな理由で発生する可能性があります。
- SQL Serverは、非効率的なクエリプランやインデックスの欠落の結果として、大量のデータを読み取る必要があります
- インスタンスに割り当てられているメモリが少なすぎるため、メモリに保持できないため、同じデータがディスクから何度も読み取られます
- 暗黙の変換により、インデックスまたはテーブルのスキャンが発生します
- すべての列が必要なわけではない場合、クエリはSELECT*を実行します
- ヒープ内の転送されたレコードの問題により、追加のI/Oが発生します
- インデックスの断片化、ページ分割、または不適切な曲線因子設定によるページ密度の低下により、追加のI/Oが発生します
根本的な原因が何であれ、パフォーマンスについて理解するために不可欠なことは、特にI / Oに関連する場合、問題を特定するために使用できるデータポイントが1つしかないことです。真の問題を見つけるには複数の事実が必要であり、それらをつなぎ合わせると、問題を明らかにするのに役立ちます。
最後に、場合によっては、ストレージの待ち時間が完全に許容できる場合があることに注意してください。より高速なストレージまたはコードの変更を要求する前に、データベースのワークロードパターンとサービスレベルアグリーメント(SLA)を確認してください。ユーザーにレポートを提供するデータウェアハウスの場合、クエリのSLAは、大容量のOLTPシステムに期待される1秒未満の値とはおそらく異なります。 DWソリューションでは、1秒を超えるI / O遅延は完全に許容可能であり、予想される場合があります。ビジネスとそのユーザーの期待を理解し、実行するアクションがある場合はそれを決定します。また、変更が必要な場合は、議論をサポートするために必要な定量的データ、つまり待機統計、仮想ファイル統計、およびパフォーマンスモニターからの待機時間を収集します。