2012年に、中央値を計算するためのアプローチに焦点を当てたブログ投稿をここに書きました。その投稿では、非常に単純なケースを扱いました。テーブル全体の列の中央値を見つけたいと考えました。それ以来、より実際的な要件は分割された中央値を計算することであると何度も言われてきました。 。基本的な場合と同様に、SQLServerのさまざまなバージョンでこれを解決する方法は複数あります。当然のことながら、一部の製品は他の製品よりもはるかに優れたパフォーマンスを発揮します。
前の例では、一般的な列idとvalがありました。これをより現実的にして、営業担当者と彼らが一定期間に行った販売数があるとしましょう。クエリをテストするために、最初に17行の単純なヒープを作成し、それらがすべて期待どおりの結果を生成することを確認しましょう(SalesPerson 1の中央値は7.5、SalesPerson 2の中央値は6.0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
これが、上記のヒープとサポートするインデックスに対してテストするクエリです(より多くのデータを使用して!)。以前のテストからいくつかのクエリを破棄しました。これらのクエリは、まったくスケーリングされなかったか、パーティション化された中央値(つまり、#tempテーブルを使用した2000_Bと反対の行を使用した2005_A)にうまくマッピングされませんでした。数字)。ただし、以前の投稿に基づいて作成されたDwain Camps(@DwainCSQL)による最近の記事から、いくつかの興味深いアイデアを追加しました。
SQL Server 2000+
SQL Server 2000で十分に機能し、このテストに含めることができた以前のアプローチの唯一の方法は、「半分の最小値、もう一方の最大値」アプローチでした。
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; 正直に言って、より単純な例で使用した#tempテーブルのバージョンを模倣しようとしましたが、まったく拡張性がありませんでした。 20行または200行では、正常に機能しました。 2000年には、1分近くかかりました。 1,000,000で私は1時間後にあきらめました。後世のためにここに含めました(クリックして表示します)。
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
これは、2つの異なるウィンドウ関数を使用して、営業担当者ごとのシーケンスと全体的な金額を導き出します。
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
これは、Dwain Campsの記事からのもので、上記と同じように、もう少し手の込んだ方法で行われます。これは基本的に、各グループの興味深い行のピボットを解除します。
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
これは、私の以前の投稿へのコメントでのAdam Machanicからの提案に基づいており、上記の彼の記事でDwainによって強化されました。
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
これは上記の「2005+1」に似ていますが、COUNT(*) OVER()を使用する代わりに カウントを導出するために、導出されたテーブル内の分離された集計に対して自己結合を実行します。
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
これは、Dwainの記事へのコメントで、SQLServerの仲間であるMVPのPeter"Peso" Larsson(@SwePeso)からの非常に興味深い貢献でした。 CROSS APPLYを使用します そして新しいOFFSET / FETCH より単純な中央値計算に対するItzikのソリューションよりもさらに興味深く驚くべき方法での機能。
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
最後に、新しいPERCENTILE_CONT()があります。 SQLServer2012で導入された機能。
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; 実際のテスト
上記のクエリのパフォーマンスをテストするために、はるかに実質的なテーブルを作成します。 100人のユニークな営業担当者がいて、それぞれ10,000の売上高があり、合計1,000,000行になります。また、(SalesPerson, Amount)に非クラスター化インデックスを追加して、ヒープに対して各クエリをそのまま実行します。 、および同じ列にクラスター化されたインデックスがあります。設定は次のとおりです:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
そして、ヒープ、非クラスター化インデックス、およびクラスター化インデックスに対する上記のクエリの結果は次のとおりです。
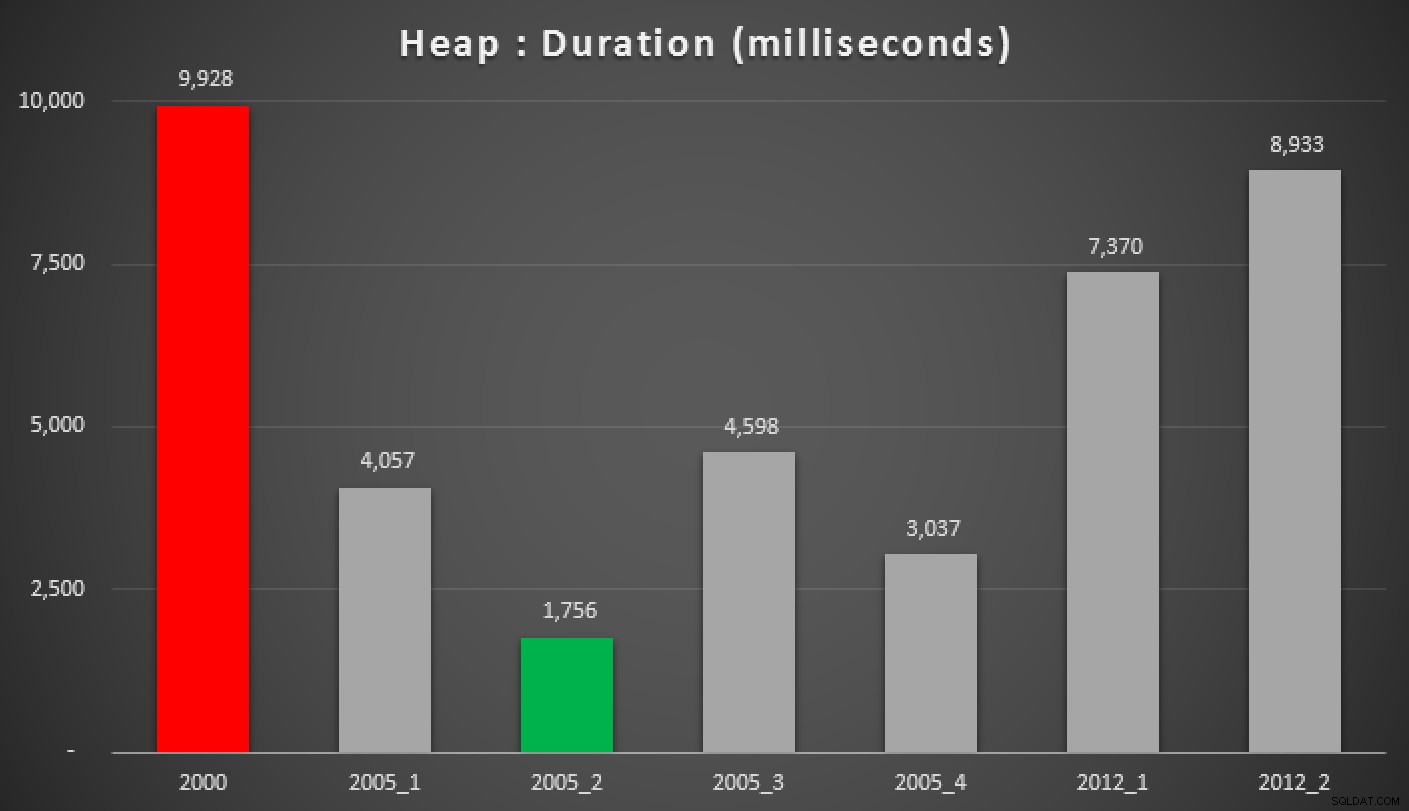
さまざまなグループ化された中央値アプローチの期間(ミリ秒単位)ヒープ)
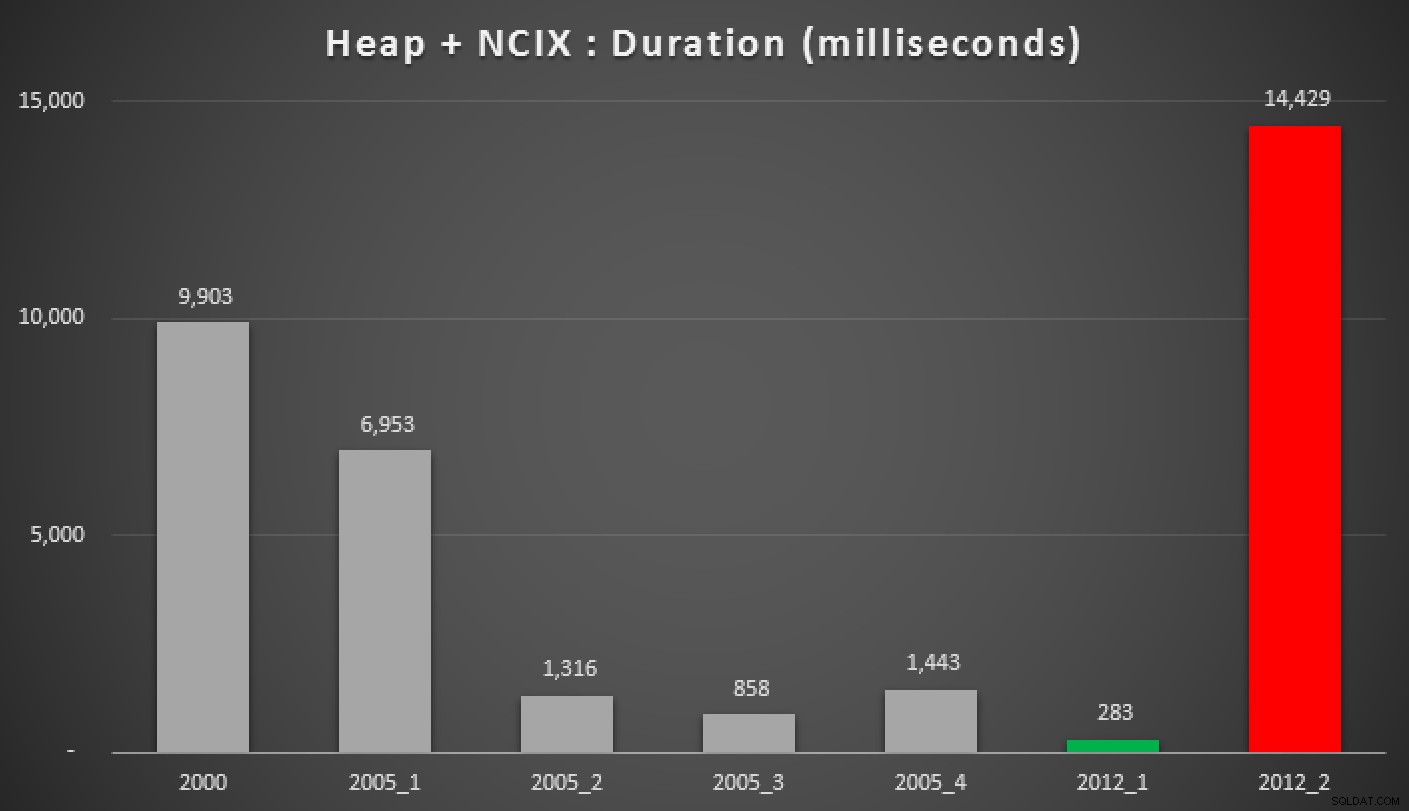
さまざまなグループ化された中央値アプローチの期間(ミリ秒単位)非クラスター化インデックスのヒープ)
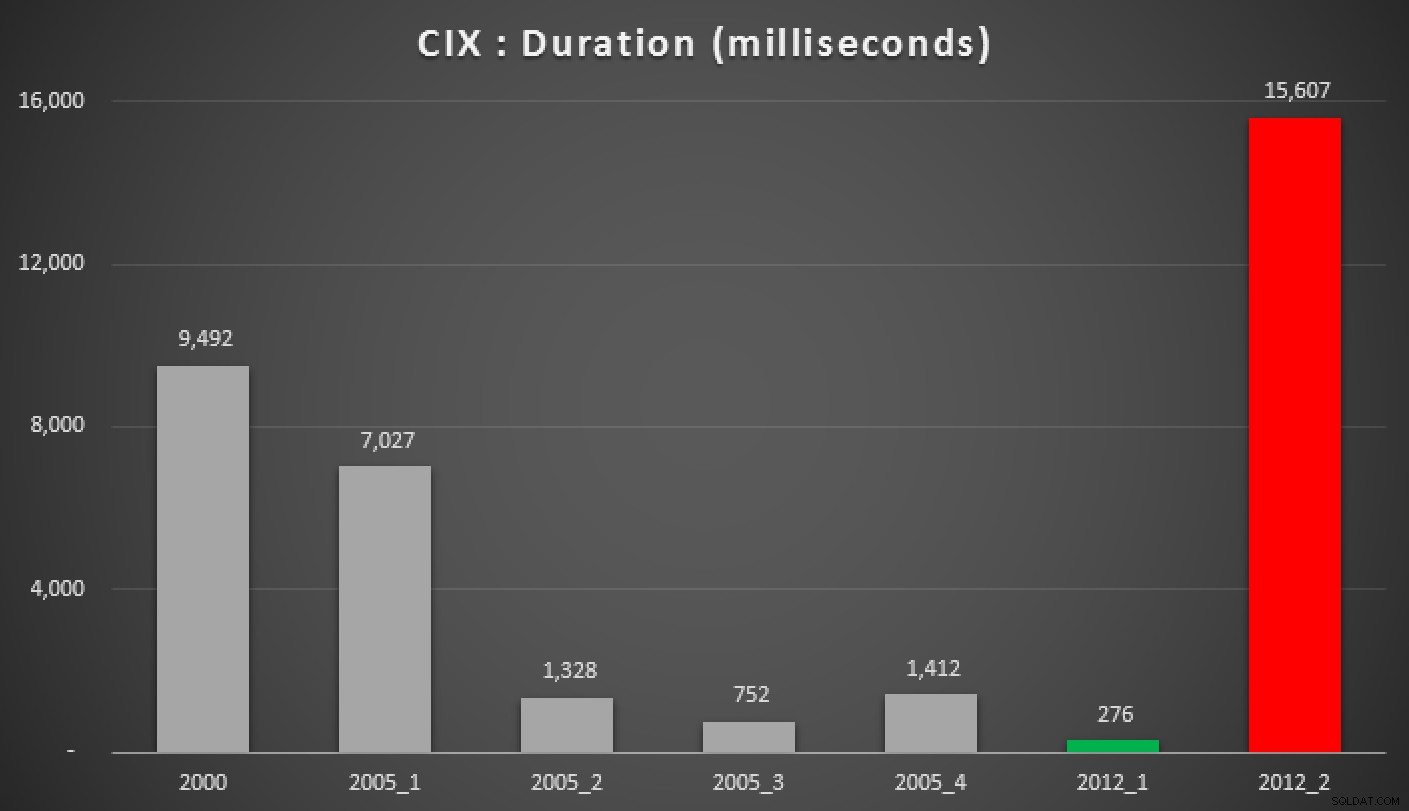
さまざまなグループ化された中央値アプローチの期間(ミリ秒単位)クラスタ化されたインデックス)
ヘカトンはどうですか?
当然のことながら、SQL Server 2014のこの新機能が、これらのクエリのいずれかで役立つかどうかに興味がありました。そこで、インメモリデータベースを作成しました。2つのインメモリバージョンのSalesテーブル(1つは(SalesPerson, Amount)にハッシュインデックスがあります 、およびその他は(SalesPerson)のみ )、同じテストを再実行しました:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
結果:
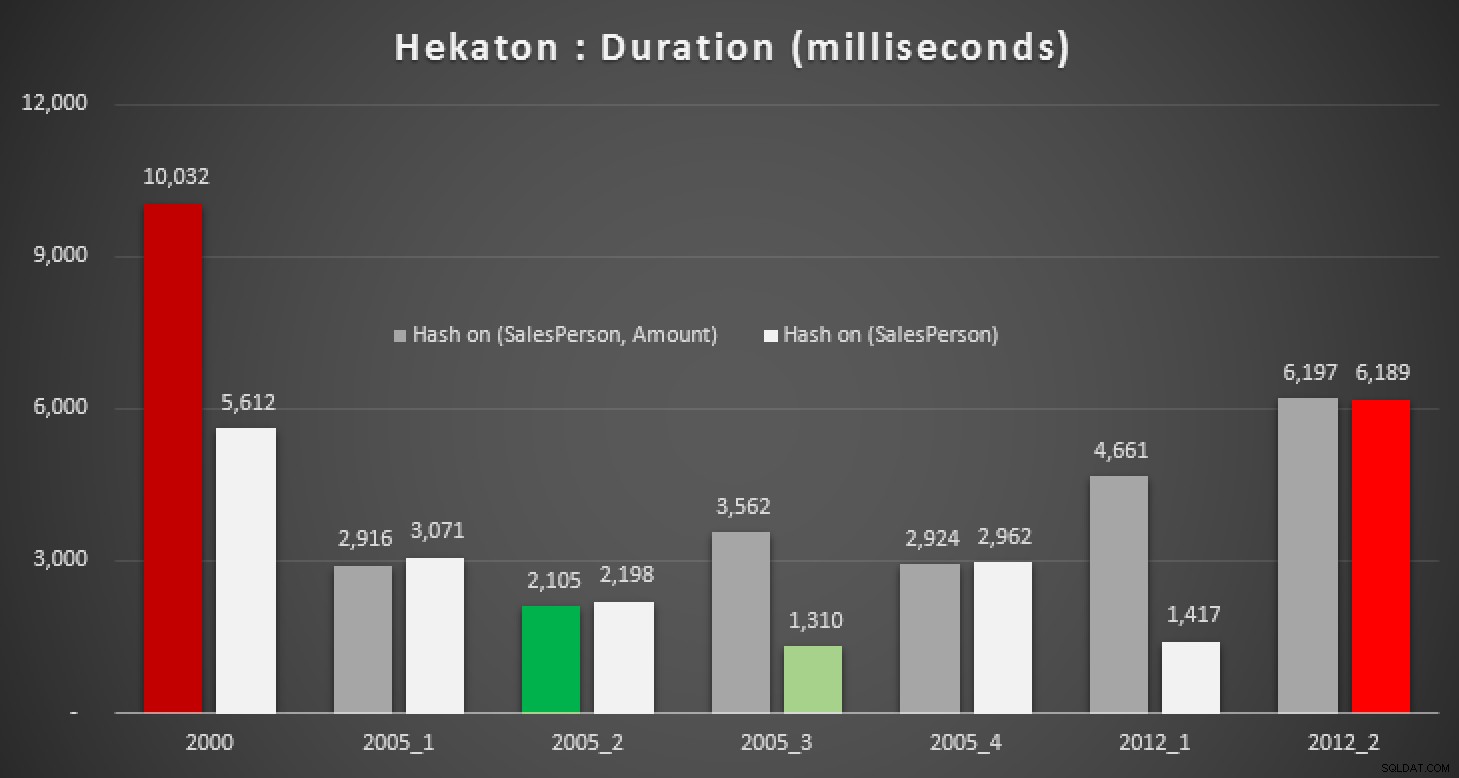
インメモリに対するさまざまな中央値計算の期間(ミリ秒単位)テーブル
適切なハッシュインデックスを使用しても、従来のテーブルに比べて大幅な改善は見られません。さらに、ネイティブにコンパイルされたストアドプロシージャを使用して中央値の問題を解決しようとすることは、上記で使用された言語構造の多くが有効ではないため、簡単な作業ではありません(これらのいくつかにも驚きました)。上記のクエリバリエーションをすべてコンパイルしようとすると、このエラーのパレードが発生しました。いくつかは各手順内で複数回発生し、重複を削除した後でも、これはまだ一種のコミカルです:
メッセージ10794、レベル16、状態47、プロシージャGroupedMedian_2000オプション「DISTINCT」は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2000
サブルーチン(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態48、プロシージャGroupedMedian_2000
オプション「PERCENT」は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2005_1
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態91 、プロシージャGroupedMedian_2005_1
集約関数'ROW_NUMBER'は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態56、プロシージャGroupedMedian_2005_1
演算子'IN'はサポートされていません。ネイティブにコンパイルされたストアドプロシージャ。
Msg 12310、レベル16、状態36、プロシージャGroupedMedian_2005_2
Common Table Expressions(CTE)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12309、レベル16、状態35、プロシージャGroupedMedian_2005_2
フォームのステートメント複数の行を挿入するINSERT…VALUES…は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態53、プロシージャGroupedMedian_2005_2
演算子「APPLY」は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2005_2
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態91、プロシージャGroupedMedian_2005_2
集約関数'ROW_NUMBER'は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12310、レベル16、状態36、プロシージャGroupedMedian_2005_3
Common Table Expressions(CTE)はネイティブにコンパイルされたストアドではサポートされていませんプロシージャ。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2005_3
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態91 、Procedure GroupedMedian_2005_3
集約関数'ROW_NUMBER'は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態53、プロシージャGroupedMedian_2005_3
演算子'APPLY'はサポートされていません。ネイティブにコンパイルされたストアドプロシージャ。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2005_4
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態91、プロシージャGroupedMedian_2005_4
集約関数'ROW_NUMBER'は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態56、プロシージャGroupedMedian_2005_4
演算子'IN'は、ネイティブにコンパイルされたstorではサポートされていませんedプロシージャ。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2012_1
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態38、プロシージャGroupedMedian_2012_1
演算子「OFFSET」はネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態53、プロシージャGroupedMedian_2012_1
演算子「APPLY」ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ12311、レベル16、状態37、プロシージャGroupedMedian_2012_2
サブクエリ(別のクエリ内にネストされたクエリ)は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
メッセージ10794、レベル16、状態90、プロシージャGroupedMedian_2012_2
集約関数'PERCENTILE_CONT'は、ネイティブにコンパイルされたストアドプロシージャではサポートされていません。
現在書かれているように、これらのクエリの1つをネイティブにコンパイルされたストアドプロシージャに移植することはできませんでした。おそらく、別のフォローアップ投稿を探すために何かを調べる必要があります。
結論
Hekatonの結果を破棄し、サポートインデックスが存在する場合、OFFSET/FETCHを使用したPeterLarssonのクエリ( "2012+ 1") これらのテストで遠く離れた勝者として出てきました。パーティション化されていないテストの同等のクエリよりも少し複雑ですが、これは前回観察した結果と一致しました。
同じ場合、2000 MIN/MAX アプローチと2012年のPERCENTILE_CONT() 本物の犬として出てきました。繰り返しますが、以前の単純なケースに対するテストと同じです。
SQL Server 2012をまだ使用していない場合、次善のオプションは「2005+ 3」(サポートインデックスがある場合)またはヒープを処理している場合は「2005+2」です。申し訳ありませんが、主に以前の投稿のメソッドとの混同を避けるために、これらの新しい命名スキームを考え出す必要がありました。
もちろん、これらは非常に特定のスキーマとデータセットに対する私の結果です。他の要因が異なる結果に影響を与える可能性があるため、すべての推奨事項と同様に、スキーマとデータに対してこれらのアプローチをテストする必要があります。
もう1つのメモ
パフォーマンスが低く、ネイティブにコンパイルされたストアドプロシージャでサポートされていないことに加えて、PERCENTILE_CONT()のもう1つの問題点があります。 古い互換性モードでは使用できないということです。試してみると、次のエラーが発生します:
PERCENTILE_CONT関数は、現在の互換モードでは許可されていません。 110モード以上でのみ許可されます。