OVER関数とPARTITIONBY関数はどちらも、指定された基準に従って結果セットを分割するために使用される関数です。
この記事では、これら2つの関数を組み合わせて使用して、非常に特殊な方法でパーティション化されたデータを取得する方法について説明します。
サンプルデータの準備
サンプルクエリを実行するために、最初に「studentdb」という名前のデータベースを作成しましょう。
クエリウィンドウで次のコマンドを実行します。
CREATE DATABASE schooldb;
次に、「studentdb」データベース内に「student」テーブルを作成する必要があります。学生テーブルには、id、name、age、gender、total_scoreの5つの列があります。
いつものように、新しいコードを試す前に、十分にバックアップされていることを確認してください。よくわからない場合は、SQLServerデータベースのバックアップに関するこの記事を参照してください。
次のクエリを実行して、学生テーブルを作成します。
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) 最後に、データベースで作業するためのダミーデータを挿入する必要があります。
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); これで、問題に取り組み、問題を解決するためにOverとPartitionByを使用できるユーザーを確認する準備が整いました。
問題
学生テーブルには10個のレコードがあり、すべての学生の名前、ID、性別を表示します。さらに、各性別に属する学生の総数、平均年齢も表示します。各性別の学生と各性別のtotal_score列の値の合計。
私たちが探している結果セットは次のとおりです。
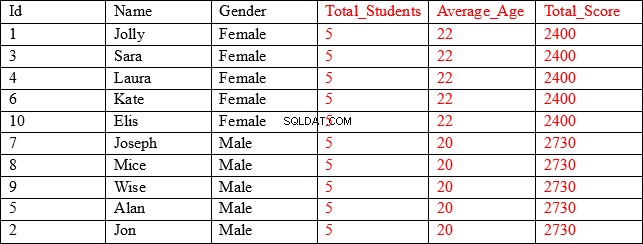
ご覧のとおり、最初の3列(黒で表示)には各レコードの個別の値が含まれ、最後の3列(赤で表示)には性別列でグループ化された集計値が含まれています。たとえば、Average_Age列の最初の5行には、性別が女性であるすべてのレコードの平均年齢と合計スコアが表示されます。
結果セットには、集計されていない列に結合された集計結果が含まれています。
特定の列でグループ化された集計結果を取得するには、通常どおりGROUPBY句を使用できます。
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
性別でグループ化された生徒のTotal_Students、Average_Age、Total_Scoreを取得する方法を見てみましょう。
次の結果が表示されます:

次に、これを拡張して「id」と「name」(SELECTステートメントの非集計列)を追加し、目的の結果が得られるかどうかを確認します。
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
上記のクエリを実行すると、エラーが表示されます:

エラーは、クエリでGROUP BY句を使用しているため、SELECTステートメント内のstudentテーブルのid列が無効であることを示しています。
これは、id列に集計関数を適用するか、GROUPBY句で使用する必要があることを意味します。要するに、このスキームは私たちの問題を解決しません。
JOINステートメントを使用したソリューション
これに対する1つの解決策は、JOINステートメントを使用して、集計された結果を含む列を、集計されていない結果を含む列に結合することです。
これを行うには、性別、Total_Students、Average_Age、および性別でグループ化された学生のTotal_Scoreを取得するサブクエリが必要です。これらの結果は、外部のSELECTステートメントを使用してサブクエリから取得した結果に結合できます。これは、集計結果を含むサブクエリの性別列と学生テーブルの性別列に適用されます。外側のSELECTステートメントには、以下のように、集約されていない列、つまり「id」と「name」が含まれます。
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
上記のクエリは望ましい結果をもたらしますが、最適なソリューションではありません。 JOINステートメントと、スクリプトの複雑さを増すサブクエリを使用する必要がありました。これはエレガントで効率的なソリューションではありません。
より良いアプローチは、OVER句とPARTITIONBY句を組み合わせて使用することです。
OVERとPARTITIONBYを使用したソリューション
OVER句とPARTITIONBY句を使用するには、集計結果を分割する列を指定するだけです。これは、例を使用して最もよく説明されています。
OVERとPARTITIONBYを使用して結果を達成する方法を見てみましょう。
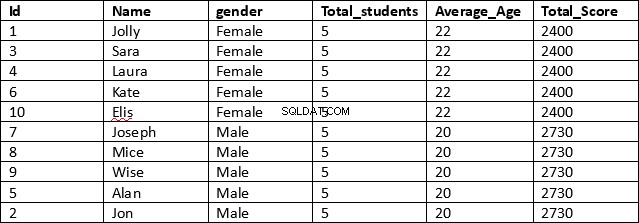
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
これははるかに効率的な結果です。スクリプトの最初の行で、id、name、genderの列が取得されます。これらの列には、集計結果は含まれていません。
次に、集約された結果を含む列に対して、集約された関数を指定し、続いてOVER句を指定し、括弧内にPARTITION BY句を指定し、その後に結果を分割する列の名前を示します。以下。
参照
- Microsoft –OVER句を理解する
- 真夜中のDBA–OVERとPARTITIONBYの概要
- StackOverflow –PARTITIONBYとGROUPBYの違い