以前、ActualRowsReadプロパティについて書きました。これは、インデックスシークによって実際に読み取られる行数を示します。これにより、シーク述語と残差述語を組み合わせた選択性と比較して、シーク述語がどれほど選択的であるかを確認できます。
しかし、Seekオペレーターの内部で実際に何が起こっているのかを見てみましょう。 「実際の行の読み取り」が必ずしも何が起こっているのかを正確に説明しているとは確信していないためです。
顧客の特定のアドレスタイプのアドレスをクエリする例を見たいのですが、ここでの原則は、キーと値のペアテーブルで属性を検索するなど、クエリの形状が適合する場合、他の多くの状況に簡単に適用できます。たとえば。
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
メタデータについては何もお見せしていないことは承知しています。すぐに戻ってきます。このクエリと、そのクエリにどのようなインデックスを付けたいかを考えてみましょう。
まず、CustomerIDを正確に把握しています。このような等式一致は、通常、インデックスの最初の列の優れた候補になります。この列にインデックスがあれば、その顧客の住所に直接飛び込むことができるので、それは安全な仮定だと思います。
次に考慮すべきことは、AddressTypeIDのフィルターです。インデックスのキーに2番目の列を追加することは完全に合理的であるため、それを実行しましょう。インデックスがオンになりました(CustomerID、AddressTypeID)。また、FullAddressも含めて、画像を完成させるためにルックアップを行う必要がないようにします。
そして、私たちは終わったと思います。このクエリの理想的なインデックスは次のとおりであると安全に想定できるはずです。
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
一意のインデックスとして宣言できる可能性があります。その影響については後で説明します。
それでは、テーブルを作成して(このブログ投稿を超えて永続化する必要がないため、tempdbを使用しています)、これをテストしてみましょう。
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
外部キーの制約や、他にどのような列があるのかについては興味がありません。私は自分の理想的なインデックスにのみ興味があります。まだ作成していない場合は、それも作成してください。
私の計画はかなり完璧なようです。
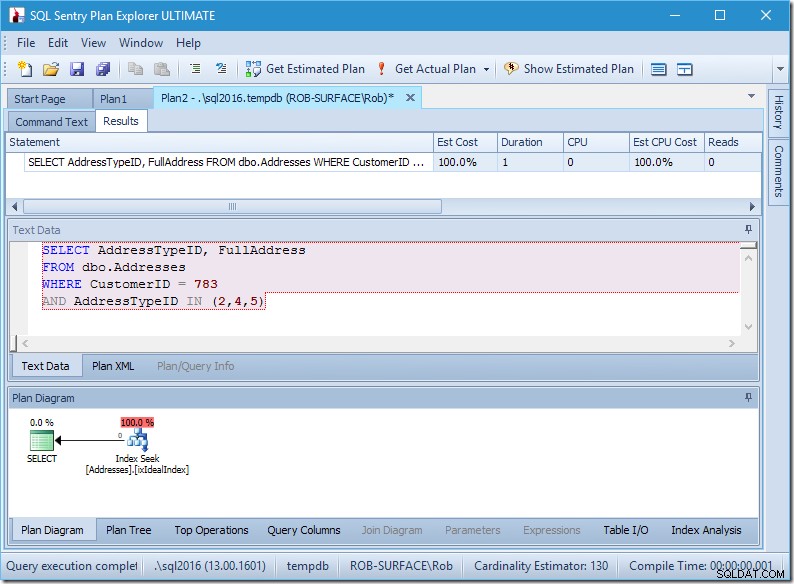
インデックスシークがあります。それだけです。
確かに、データがないため、読み取りもCPUもありません。また、非常に高速に実行されます。これだけでなく、すべてのクエリを調整できれば。
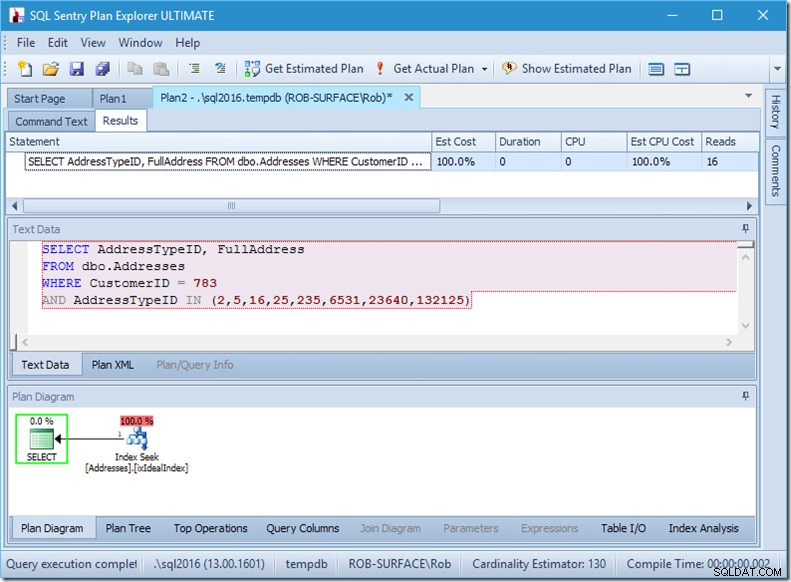
シークのプロパティを見て、もう少し詳しく見てみましょう。
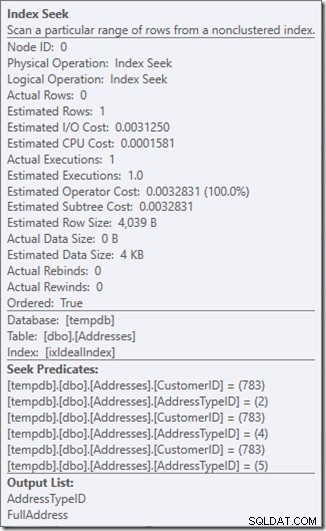
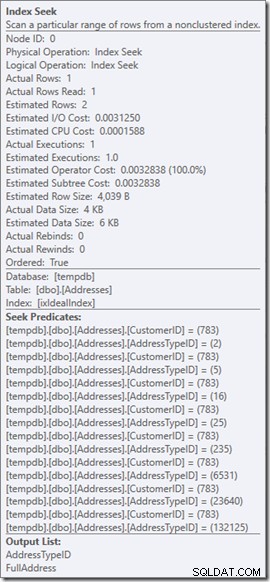
Seek述語を見ることができます。六つある。 CustomerIDについて3つ、AddressTypeIDについて3つ。ここに実際にあるのは、3セットのseek述語であり、単一のSeek演算子内の3つのseek操作を示しています。最初のシークは顧客783とAddressType2を探しています。2番目は783と4を探しており、最後の783と5を探しています。
データすらありませんが、インデックスがどのように使用されるかはわかります。
これによる影響の一部を確認できるように、ダミーデータをいくつか入れてみましょう。タイプ1から6のアドレスを入力します。すべての顧客(2000以上、master..spt_valuesのサイズに基づく) )はタイプ1のアドレスになります。おそらくそれがプライマリアドレスです。 80%にタイプ2のアドレス、60%にタイプ3、というように、タイプ5の場合は最大20%にします。行783は、タイプ1、2、3、および4のアドレスを取得しますが、5は取得しません。ランダムな値を使用したいのですが、例については同じページにいることを確認したいと思います。
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; 次に、データを使用したクエリを見てみましょう。 2列出ています。以前と同じですが、Seek演算子から2つの行が出ており、右上に6つの読み取りがあります。
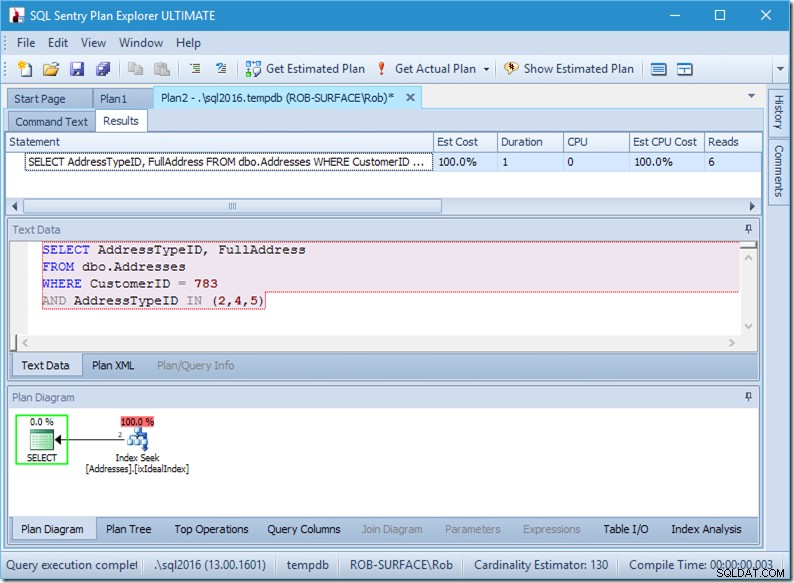
6回の読み取りは私には理にかなっています。小さなテーブルがあり、インデックスは2つのレベルに収まります。 (1人のオペレーター内で)3回のシークを実行しているため、エンジンはルートページを読み取り、どのページに移動するかを見つけてそれを読み取り、それを3回実行します。
2つのAddressTypeIDを探すだけの場合、4つの読み取りだけが表示されます(この場合、1つの行が出力されます)。すばらしい。
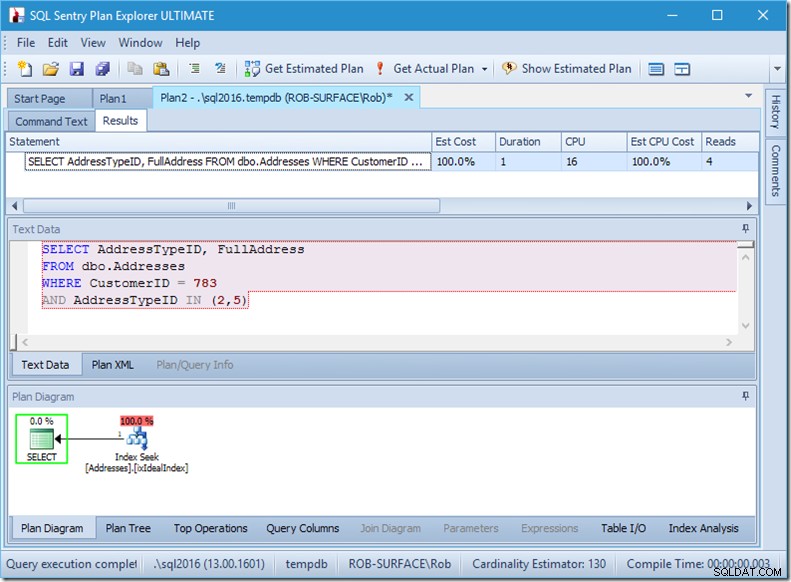
また、8つのアドレスタイプを探している場合は、16が表示されます。
しかし、これらのそれぞれは、実際の行の読み取りが実際の行と正確に一致することを示しています。非効率性はまったくありません!
元のクエリに戻り、アドレスタイプ2、4、5(2行を返す)を探して、シーク内で何が起こっているかを考えてみましょう。
クエリエンジンは、インデックスシークが適切な操作であり、インデックスルートのページ番号が便利であることを理解するための作業をすでに行っていると仮定します。
この時点で、まだそこにない場合は、そのページをメモリにロードします。これは、シークの実行でカウントされる最初の読み取りです。次に、探している行のページ番号を見つけて、そのページを読み込みます。これが2回目の読み取りです。
しかし、「ページ番号を特定する」ビットについてよく説明します。
DBCC IND(2, N'dbo.Address', 2);を使用する (最初の2 tempdbを使用しているため、データベースIDです。 2番目の2 ixIdealIndexのインデックスIDです。 )、ファイル1の712が最も高いIndexLevelを持つページであることがわかります。下のスクリーンショットでは、668ページがルートページであるIndexLevel0であることがわかります。

これで、DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); 712ページの内容を確認します。私のマシンでは、84行が戻ってきて、CustomerID783がファイル5の1004ページにあることがわかります。
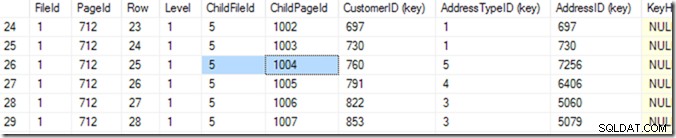
しかし、必要なものが表示されるまでリストをスクロールすることで、これを知ることができます。最初は少し下にスクロールしてから、目的の行が見つかるまで上に戻りました。コンピューターはこれを二分探索と呼んでおり、私よりも少し正確です。 (CustomerID、AddressTypeID)の組み合わせが私が探しているものよりも小さく、次のページが大きいか同じである行を探しています。 2つのページにまたがって一致するものが2つある可能性があるため、「同じ」と言います。そのページに84行(0から83)のデータがあることを知っているので(ページヘッダーでそれを読み取ります)、行41をチェックすることから始めます。そこから、検索する半分を知っています。この例)、行20を読み取ります。さらに数回読み取り(合計で6または7になります)*、行25を認識します(SSMSによって提供される行番号ではなく、この値については「行」という列を参照してください)。 )は小さすぎますが、行26は大きすぎます。したがって、25が答えです!
*二分探索では、中央のスロットがない場合にブロックを2つに分割し、中央のスロットを削除できるかどうかによって、運が良ければ検索がわずかに速くなる可能性があります。
これで、ファイル5の1004ページに移動できます。その1つでDBCCPAGEを使用しましょう。
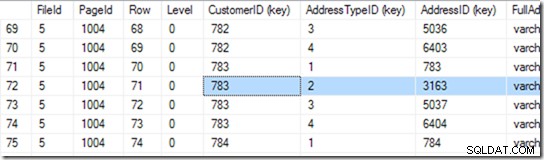
これは私に94行を与えます。別の二分探索を実行して、探している範囲の開始点を見つけます。それを見つけるには、6行または7行を調べる必要があります。
「範囲の始まり?」私はあなたが尋ねるのを聞くことができます。ただし、お客様783のアドレスタイプ2を探しています。
そうですが、このインデックスを一意であるとは宣言していません。したがって、2つある可能性があります。一意の場合、シークはシングルトン検索を実行でき、バイナリ検索中に遭遇する可能性がありますが、この場合、範囲内の最初の行を見つけるために、バイナリ検索を完了する必要があります。この場合、それは行71です。
しかし、ここで止まりません。次に、本当に2つ目があるかどうかを確認する必要があります。したがって、行72も読み取り、CustomerID + AddressTypeiDのペアが実際に大きすぎることを検出し、シークが実行されます。
そしてこれは3回起こります。 3回目は、顧客783と住所タイプ5の行が見つかりませんが、これを事前に認識していないため、シークを完了する必要があります。
したがって、これらの3つのシーク(出力する2つの行を見つけるため)で実際に読み取られる行は、返される数よりもはるかに多くなります。範囲の開始点を見つけるためだけに、インデックスレベル1には約7つ、リーフレベルにはさらに約7つあります。次に、関心のある行を読み取り、その後の行を読み取ります。それは私には16のように聞こえますが、これを3回実行して、約48行になります。
ただし、実際に読み取られる行の数は、実際に読み取られる行の数ではなく、残りの述語に対してテストされる、シーク述語によって返される行の数です。その中で、3つのシークによって検出されるのは2行だけです。
この時点で、ここにはある程度の効果がないと考えているかもしれません。 2回目のシークも712ページを読み、そこで同じ6行または7行をチェックしてから、1004ページを読み、それを探し回っていました…3回目のシークと同じです。
したがって、これを1回のシークで取得し、712ページと1004ページをそれぞれ1回だけ読む方がよいでしょう。結局のところ、紙ベースのシステムでこれを行っていたとしたら、顧客783を探して、すべての住所タイプをスキャンしたでしょう。なぜなら、顧客は多くの住所を持っていない傾向があることを私は知っているからです。これは、データベースエンジンよりも優れています。データベースエンジンは、統計を通じてシークが最適であることを認識していますが、理想的なインデックスのように見えるものがあると判断できる場合、シークが1レベル下がるだけであることを認識していません。
クエリを変更して2から5までのアドレスタイプの範囲を取得すると、ほぼ希望する動作が得られます。
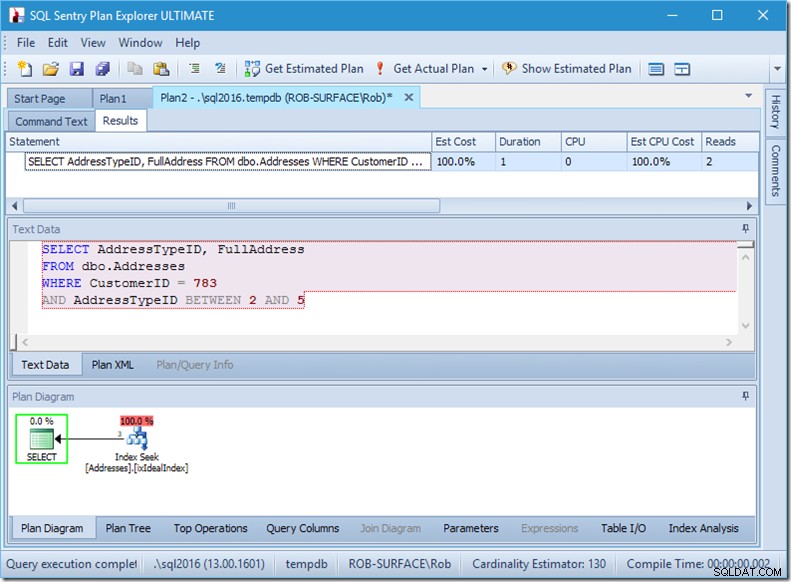
見てください–読み取りは2に減っています、そして私はそれらがどのページであるかを知っています…
…しかし、私の結果は間違っています。アドレスタイプは3ではなく2、4、5だけにしたいので、3を持たないように指示する必要がありますが、これを行う方法には注意する必要があります。次の2つの例を見てください。
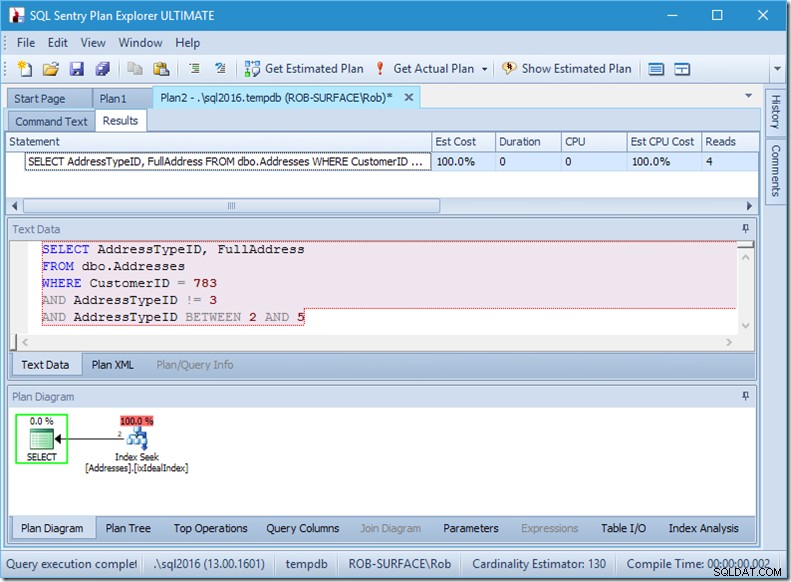
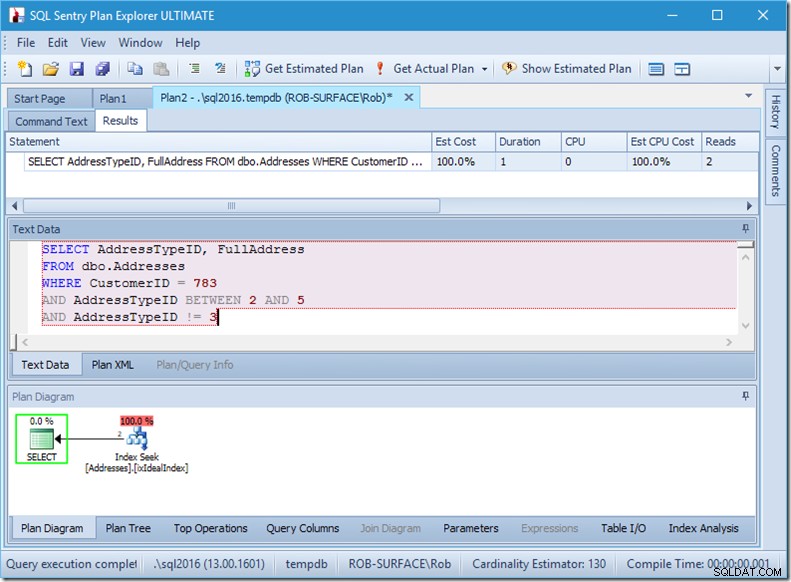
述語の順序は重要ではありませんが、ここでは明らかに重要です。 「not3」を最初に配置すると、2回のシーク(4回の読み取り)が実行されますが、「not 3」を2番目に配置すると、1回のシーク(2回の読み取り)が実行されます。
問題は、AddressTypeID!=3が(AddressTypeID>3またはAddressTypeID<3)に変換されることです。これは、2つの非常に便利なシーク述語と見なされます。
したがって、私の好みは、引数不可能な述語を使用して、アドレスタイプ2、4、および5のみが必要であることを通知することです。これは、AddressTypeIDにゼロを追加するなど、何らかの方法で変更することで実行できます。
>
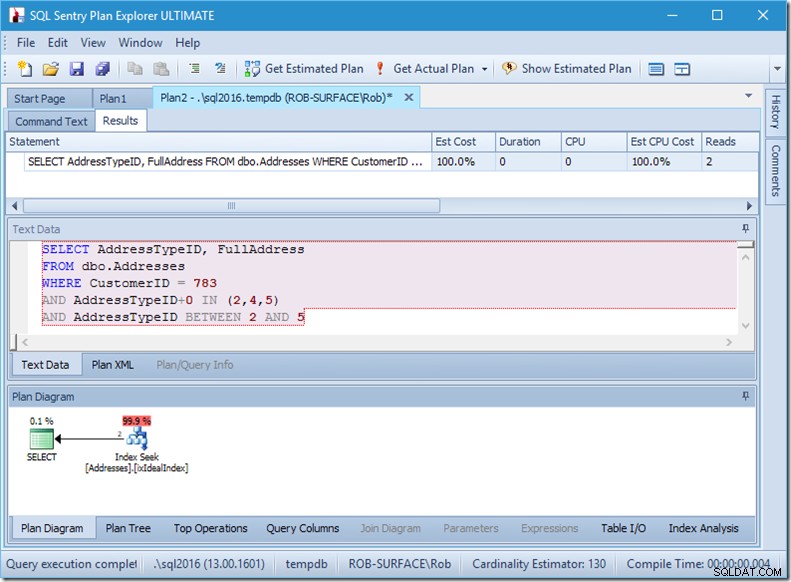
これで、1回のシーク内で適切で狭い範囲のスキャンが可能になりましたが、クエリが必要な行のみを返すことを確認しています。
ああ、でもその実際の行の読み取りプロパティ? Seek Predicateがアドレスタイプ3を検出し、Residual Predicateが拒否するため、これはActualRowsプロパティよりも高くなります。
3つの完全なシークを1つの不完全なシークと交換しましたが、残りの述語で修正しています。
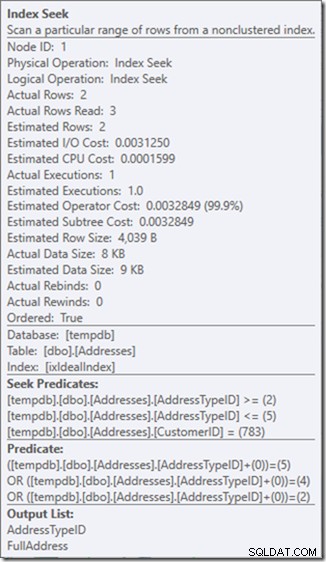
そして、私にとって、それは時々支払う価値のある価格であり、私がはるかに満足しているクエリプランを取得します。読み取りの3分の1しかないにもかかわらず(物理的な読み取りは2つしかないため)、それほど安くはありませんが、実行中の作業について考えると、私が求めているものの方がはるかに快適です。このようにするためです。