昨年、INSTEADOFTriggersに切り替えることでSQLServerの効率を向上させるというヒントを投稿しました。
特にビジネスロジック違反が多いと予想される場合に、INSTEAD OFトリガーを好む傾向がある大きな理由は、アクションを実行するよりも、アクションを完全に防止する方が安価であると直感的に思われるためです(およびログに記録してください!)、AFTERトリガーを使用して、問題のある行を削除する(または操作全体をロールバックする)場合のみ。そのヒントに示されている結果は、これが実際に当てはまることを示しています。操作の影響を受ける非クラスター化インデックスが増えると、さらに顕著になると思います。
ただし、これは低速のディスクであり、SQL Server 2014の初期のCTPでした。今年、トリガーで行う新しいプレゼンテーションのスライドを準備する際に、SQL Server2014のより新しいビルドで–更新されたハードウェアと組み合わせる–AFTERトリガーとINSTEADOFトリガーの間で同じパフォーマンスのデルタを示すのは少し難しいです。そこで私は、これが1つのスライドに対してこれまでに行ったよりも多くの作業になることをすぐに知っていたにもかかわらず、その理由を発見することに着手しました。
私が言及したいことの1つは、トリガーがtempdbを使用できることです。 さまざまな方法で、これはこれらの違いのいくつかを説明するかもしれません。 AFTERトリガーは、挿入および削除された疑似テーブルのバージョンストアを使用しますが、INSTEAD OFトリガーは、このデータのコピーを内部作業テーブルに作成します。違いは微妙ですが、指摘する価値があります。
変数
次のようなさまざまなシナリオをテストします。
- 3つの異なるトリガー:
- 失敗した特定の行を削除するAFTERトリガー
- いずれかの行に障害が発生した場合にトランザクション全体をロールバックするAFTERトリガー
- 通過する行のみを挿入するINSTEADOFトリガー
- さまざまなリカバリモデルとスナップショットアイソレーション設定:
- SNAPSHOTを有効にしてFULL
- SNAPSHOTを無効にしてFULL
- SNAPSHOTを有効にしたSIMPLE
- SNAPSHOTを無効にしたSIMPLE
- さまざまなディスクレイアウト*:
- SSDのデータ、7200RPMHDDにログオン
- SSDのデータ、SSDにログオン
- 7200 RPM HDDのデータ、SSDにログオン
- 7200 RPM HDDのデータ、7200RPMHDDにログオン
- さまざまな失敗率:
- 全体で10%、25%、50%の故障率:
- 20,000行の単一バッチ挿入
- 2,000行の10バッチ
- 200行の100バッチ
- 20行の1,000バッチ
- 20,000個のシングルトンインサート
*
tempdb低速の7200RPMディスク上の単一のデータファイルです。これは意図的なものであり、tempdbのさまざまな使用によって引き起こされるボトルネックを増幅することを目的としています。 。tempdbのある時点で、このテストを再検討する予定です。 より高速なSSD上にあります。 - 全体で10%、25%、50%の故障率:
わかりました、TL; DRはすでにです!
結果を知りたいだけの場合は、スキップしてください。真ん中のすべては、背景と、テストの設定と実行方法の説明にすぎません。誰もがすべての細目に興味を持っているわけではないことを私は心が痛むことはありません。
シナリオ
この特定の一連のテストでは、実際のシナリオは、ユーザーが画面名を選択するシナリオであり、トリガーは、選択された名前がいくつかのルールに違反する場合をキャッチするように設計されています。たとえば、「ninny-muggins」のバリエーションにすることはできません(ここで想像力を働かせることができます)。
20,000の一意のユーザー名でテーブルを作成しました:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
次に、「いたずらな名前」をチェックするためのソースとなるテーブルを作成しました。この場合は、ninny-muggins-00001です。 ninny-muggins-10000を介して :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
これらのテーブルはmodelで作成しました データベースを作成するたびにローカルに存在するようにデータベースを作成し、上記のシナリオマトリックスをテストするために多くのデータベースを作成する予定です(データベース設定を変更したり、ログを消去したりするだけではありません)。 テスト目的でモデルにオブジェクトを作成する場合は、完了したらそれらのオブジェクトを必ず削除してください。
余談ですが、キー違反やその他のエラー処理は意図的に除外し、挿入が試行されるずっと前に、選択した名前の一意性がチェックされるという素朴な仮定を立てますが、同じトランザクション内で(いたずらな名前の表を事前に確認しておくこともできます。
これをサポートするために、modelで次の3つのほぼ同一のテーブルも作成しました。 、テスト分離の目的で:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
そして、次の3つのトリガー(テーブルごとに1つ):
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO 選択がロールバックまたは無視されたことをユーザーに通知するために、追加の処理を検討することをお勧めしますが、これも簡単にするために省略されています。
テストセットアップ
テストしたい3つの失敗率を表すサンプルデータを作成し、10%を25、次に50に変更し、これらのテーブルもmodelに追加しました。 :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ 各テーブルには20,000行があり、合格と不合格の名前の組み合わせが異なります。行番号の列を使用すると、データをさまざまなテストのさまざまなバッチサイズに簡単に分割できますが、すべてのテストで失敗率が繰り返されます。
もちろん、結果をキャプチャする場所が必要です。このために個別のデータベースを使用することを選択しました。各テストを複数回実行し、期間をキャプチャするだけです。
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
dbo.Testsにデータを入力しました 次のスクリプトを使用してテーブルを作成します。これにより、さまざまな部分を実行して、現在のテストパラメータに一致するように4つのデータベースを設定できます。 D:\はSSDであり、G:\は7200 RPMディスクであることに注意してください:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) その後、すべてのテストを複数回実行するのは簡単でした:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
私のシステムでは、これには6時間近くかかったので、コースを中断することなく実行できるように準備してください。また、modelに対してアクティブな接続やクエリウィンドウが開いていないことを確認してください データベースを使用しない場合、スクリプトがデータベースを作成しようとしたときにこのエラーが発生する可能性があります。
データベース「モデル」の排他ロックを取得できませんでした。後で操作を再試行してください。
結果
確認すべきデータポイントは多数あります(データの導出に使用されるすべてのクエリは、付録で参照されています)。ここに示されているすべての平均期間は10テストを超えており、宛先テーブルに合計100,000行が挿入されていることに注意してください。
グラフ1-全体的な集計
最初のグラフは、さまざまな変数の全体的な集計(平均期間)を個別に示しています(したがって、削除するAFTERトリガーを使用する*すべての*テスト、ロールバックするAFTERトリガーを使用する*すべての*テストなど)。
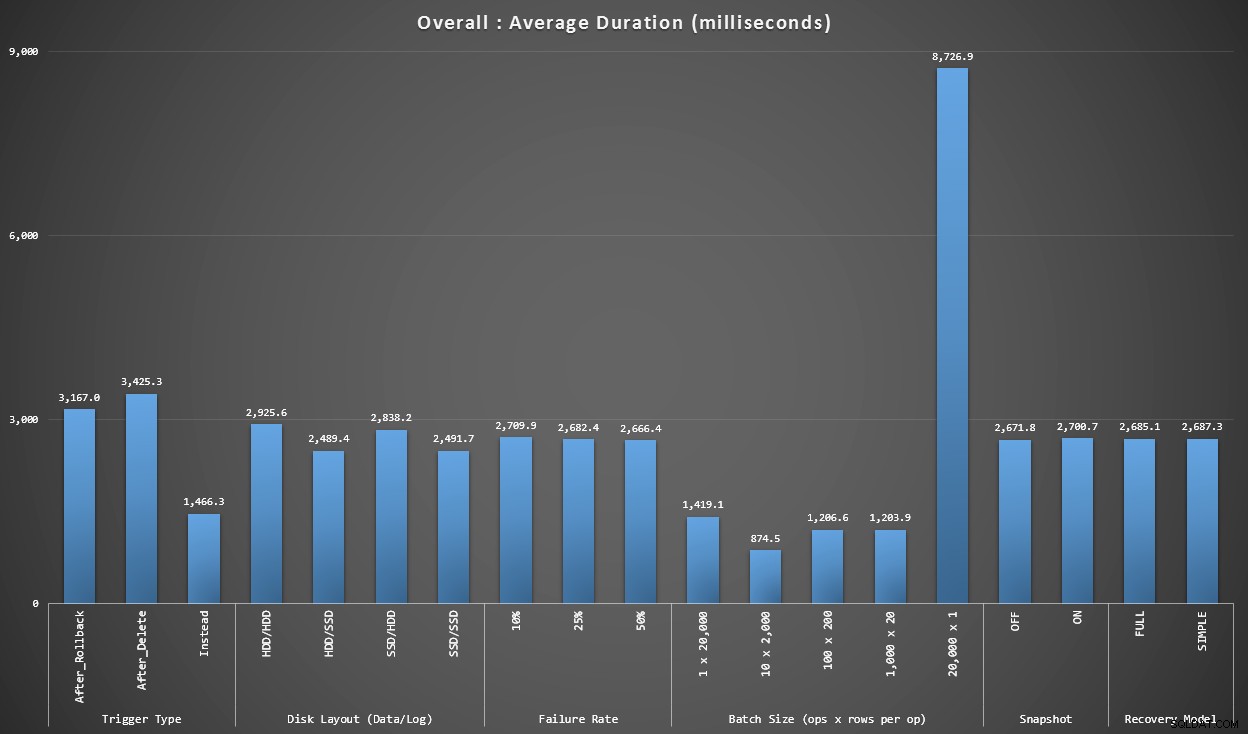
分離された各変数の平均継続時間(ミリ秒)
すぐにいくつかのことが私たちに飛び出します:
- ここでのINSTEADOFトリガーは、両方のAFTERトリガーの2倍の速度です。
- SSDにトランザクションログがあると、少し違いがあります。データファイルの場所ははるかに少ないです。
- 20,000個のシングルトンインサートのバッチは、他のどのバッチ配布よりも7〜8倍遅くなりました。
- 20,000行のシングルバッチ挿入は、シングルトン以外のどのディストリビューションよりも低速でした。
- 障害率、スナップショットアイソレーション、およびリカバリモデルは、パフォーマンスにほとんど影響を与えませんでした。
グラフ2–全体のベスト10
このグラフは、すべての変数を考慮した場合の最速の10の結果を示しています。これらはすべて、行の最大の割合(50%)が失敗するINSTEADOFトリガーです。驚いたことに、最速の(それほど多くはありませんが)データとログの両方が同じHDD(SSDではない)にありました。ここにはディスクレイアウトとリカバリモデルが混在していますが、10個すべてでスナップショットアイソレーションが有効になっており、上位7個の結果はすべて10x2,000行のバッチサイズに関係しています。
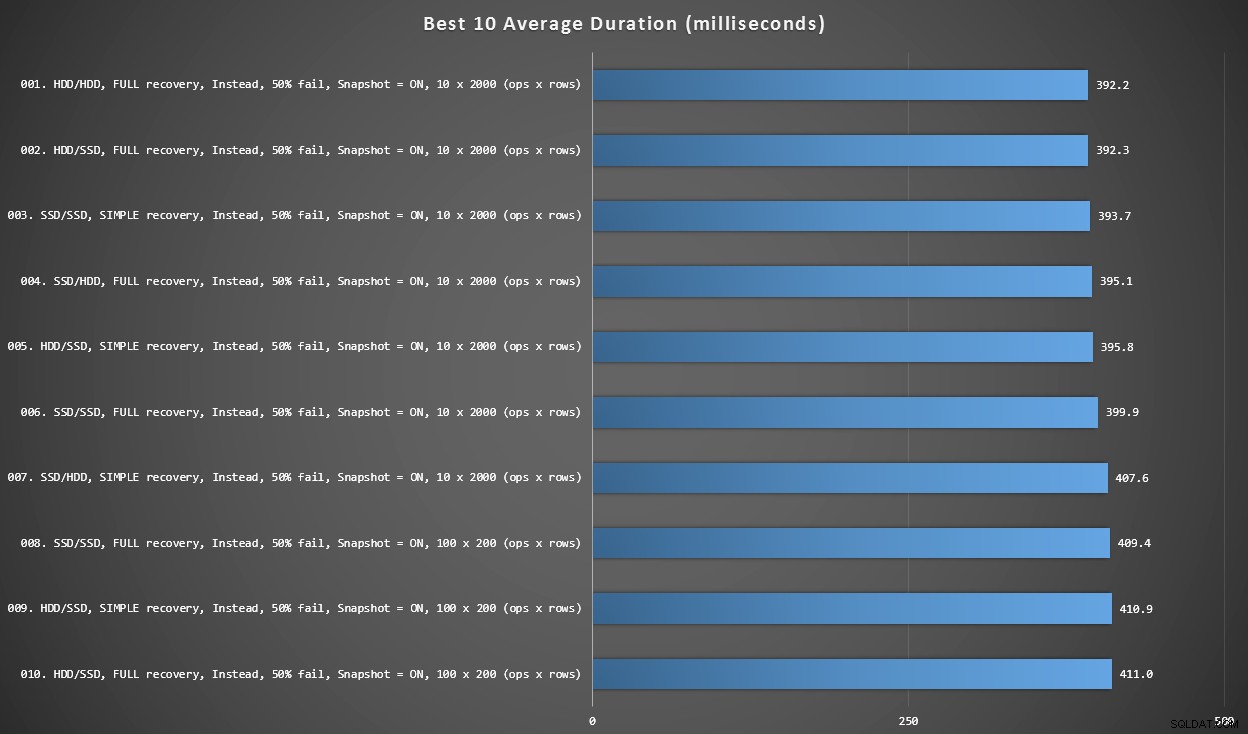
すべての変数を考慮したミリ秒単位のベスト10期間>
最速のAFTERトリガー(100 x 200行のバッチサイズで失敗率が10%のROLLBACKバリアント)は、位置#144(806ミリ秒)で発生しました。
グラフ3–全体で最悪の10
このグラフは、すべての変数を考慮した場合の最も遅い10の結果を示しています。すべてAFTERバリアントであり、すべて20,000個のシングルトンインサートが含まれ、すべて同じ低速HDDにデータとログがあります。
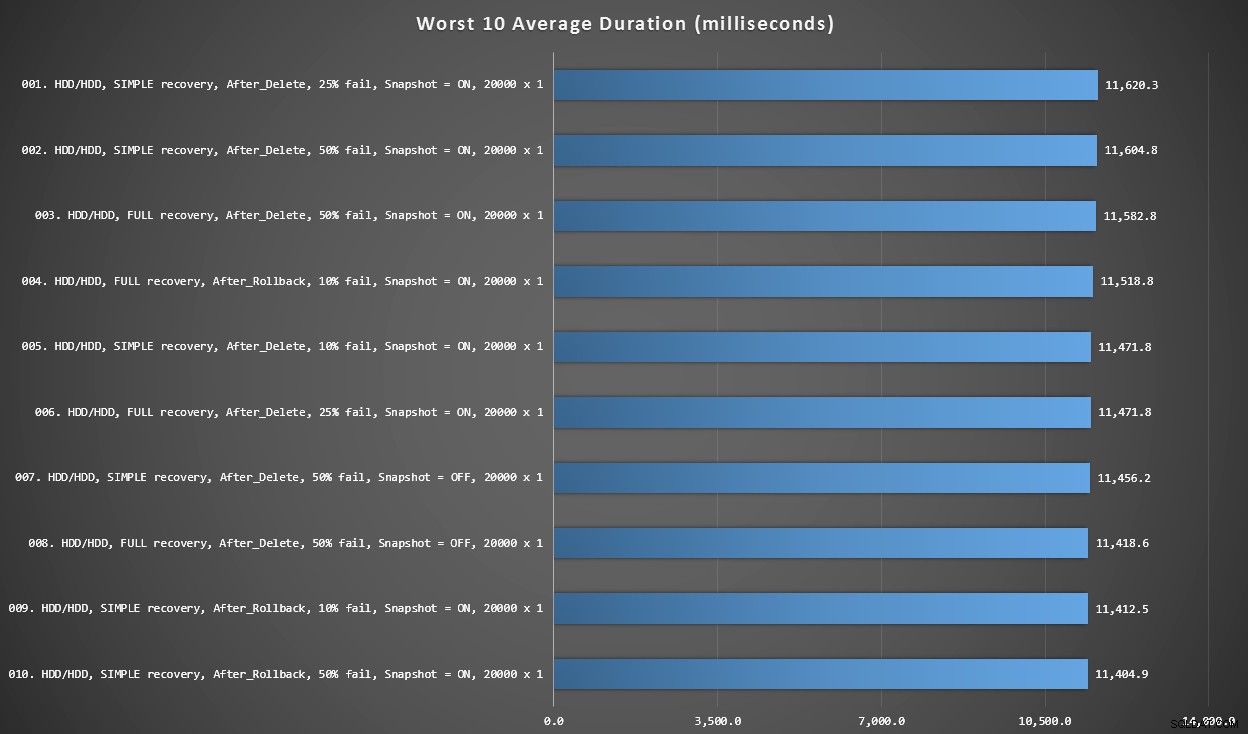
すべての変数を考慮して、ミリ秒単位で最悪の10期間>
最も遅いINSTEADOFテストは5,680ミリ秒の位置#97で、10%が失敗した20,000シングルトンインサートテストでした。 20,000シングルトン挿入バッチサイズを使用した単一のAFTERトリガーがうまくいかなかったことを観察することも興味深いです。実際、96番目に悪い結果は10,219ミリ秒で入ったAFTER(削除)テストでした。次に遅い結果のほぼ2倍です。
グラフ4–ログディスクタイプ、シングルトンインサート
上のグラフは、最大の問題点の大まかなアイデアを示していますが、ズームインしすぎているか、十分にズームインしていないかのどちらかです。このグラフは、現実に基づいてデータにフィルターをかけます。ほとんどの場合、このタイプの操作はシングルトン挿入になります。失敗率とログが記録されているディスクの種類で分類すると思いましたが、バッチが20,000の個別の挿入で構成されている行のみを確認してください。
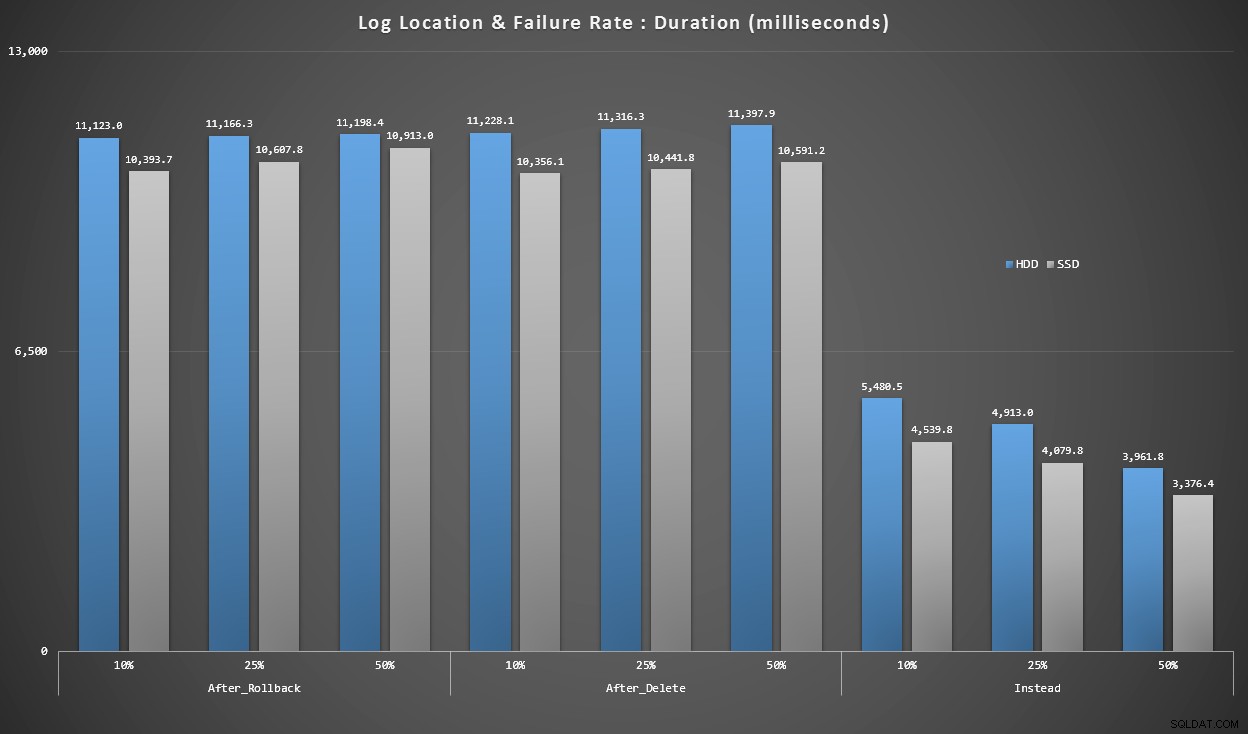
期間(ミリ秒単位)、障害率とログの場所でグループ化、 20,000個の個別挿入用
ここでは、すべてのAFTERトリガーの平均が10〜11秒の範囲(ログの場所によって異なります)であるのに対し、すべてのINSTEADOFトリガーは6秒のマークをはるかに下回っています。
結論
これまでのところ、ほとんどの場合、INSTEAD OFトリガーが勝者であることが明らかです。場合によっては、他の場合よりも勝者が多いようです(たとえば、故障率が上がるにつれて)。回復モデルなどの他の要因は、全体的なパフォーマンスへの影響がはるかに少ないようです。
データを分解する方法について他のアイデアがある場合、またはデータのコピーで独自のスライスとダイシングを実行したい場合は、お知らせください。独自のテストを実行できるようにこの環境の設定についてサポートが必要な場合は、私もサポートします。
このテストは、INSTEAD OFトリガーが確実に検討する価値があることを示していますが、それだけではありません。シナリオごとに最も理にかなっていると思われるロジックを使用して、これらのトリガーを文字通りスラップしましたが、トリガーコードは、他のT-SQLステートメントと同様に、最適な計画に合わせて調整できます。フォローアップの投稿では、AFTERトリガーの競争力を高める可能性のある最適化の可能性について見ていきます。
付録
結果セクションに使用されるクエリ:
グラフ1-全体的な集計
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
グラフ2と3–ベストとワースト10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; グラフ4–ログディスクタイプ、シングルトンインサート
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;