4月に、統計の自動更新を追跡するために使用できるSQLServer内のいくつかのネイティブメソッドについて書きました。私が提供した3つのオプションは、SQLトレース、拡張イベント、およびsys.dm_db_stats_propertiesのスナップショットでした。これらの3つのオプションは引き続き実行可能ですが(SQL Server 2014でも、私の一番の推奨事項はXEですが)、最近いくつかのテストを実行したときに気付いた追加のオプションはSQL SentryPlanExplorerです。
多くの人は、実行中の計画を読むためだけにPlanExplorerを使用します。これはすばらしいことです。プランのレビューに関しては、Management Studioに比べて多くの利点があります。たとえば、上位のオペレーターを並べ替えてカーディナリティの見積もりの問題を簡単に確認できることから、複雑で大規模なプランを処理して1つを選択できることなど、より大きなメリットがあります。計画のレビューを容易にするためのバッチ内のステートメント。ただし、プランの分析を容易にするビジュアルの背後にあるプランエクスプローラーには、クエリを実行して実際のプランを表示する機能もあります(Management Studioで実行して保存するのではありません)。さらに、PEからプランを実行すると、役立つ追加情報が取得されます。
最近の投稿「統計の自動更新がクエリのパフォーマンスにどのように影響するか」で使用したデモから始めましょう。私はAdventureWorks2012データベースから始め、2億行を超えるSalesOrderHeaderテーブルのコピーを作成しました。このテーブルには、SalesOrderIDにクラスター化されたインデックスがあり、CustomerID、OrderDate、SubTotalに非クラスター化されたインデックスがあります。 [繰り返しますが、繰り返しテストを行う場合は、この時点でこのデータベースのバックアップを取り、時間を節約してください。]最初に、テーブル内の現在の行数と、変更する必要のある行数を確認しました。自動更新を呼び出すには:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeaderCIXおよびNCI情報
インデックスの現在の統計ヘッダーも確認しました:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

NCI統計:開始時
テストに使用するストアドプロシージャはすでに作成されていますが、完全を期すために、コードを以下に示します。
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END 以前は、トレースまたは拡張イベントセッションを開始するか、sys.dm_db_stats_propertiesをテーブルにスナップショットするようにメソッドを設定しました。この例では、上記のストアドプロシージャを数回実行しました:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
次に、プロシージャキャッシュをチェックして実行回数を確認し、キャッシュされたプランも確認しました。
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

SPのキャッシュ情報を計画する:開始時
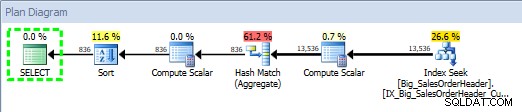
SQL SentryPlanExplorerを使用したストアドプロシージャのクエリプラン
計画は2014-09-2923:23.01に作成されました。
次に、現在の統計を無効にするためにテーブルに6,100万行を追加し、挿入が完了したら、行数を確認しました。

Big_SalesOrderHeader CIXおよびNCI情報:6,100万の挿入後行
ストアドプロシージャを再度実行する前に、実行カウントが変更されていないこと、creation_timeがプランの2014-09-29 23:23.01のままであること、および統計が更新されていないことを確認しました。
SPのキャッシュ情報を計画する:挿入直後

NCI統計:挿入後
さて、前回のブログ投稿では、Management Studioでステートメントを実行しましたが、今回は、プランエクスプローラーから直接クエリを実行し、PEを介して実際のプランをキャプチャしました(下の画像で赤い丸で囲んだオプション)。
>
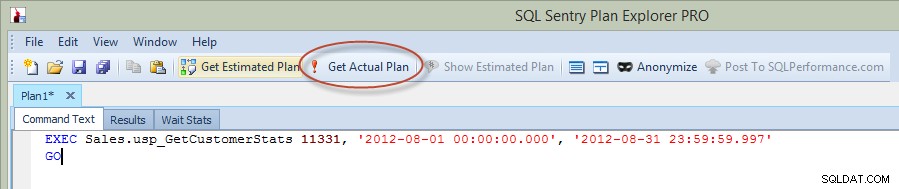
PEからステートメントを実行するときは、接続するインスタンスとデータベースを入力する必要があります。そうすると、クエリが実行され、実際のプランが返されますが、結果は返されません。これは、結果が表示されるManagementStudioとは異なることに注意してください。
ストアドプロシージャを実行した後、出力で計画を取得するだけでなく、実行されたステートメントを確認します。
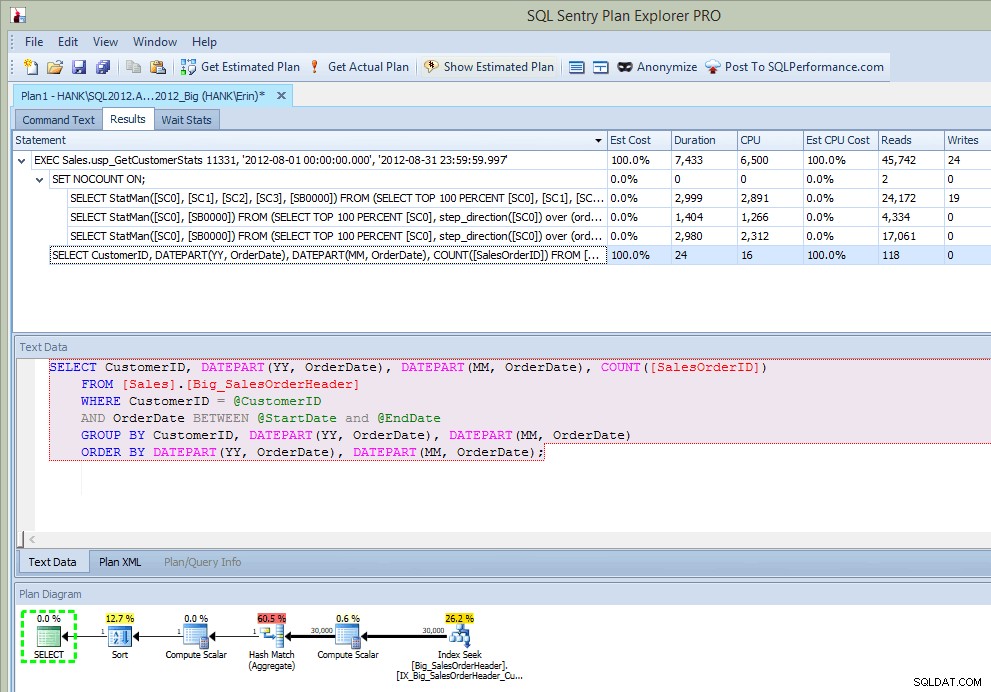
SPの実行後(挿入後)のプランエクスプローラーの出力
これは非常に便利です。ストアドプロシージャで実行されたステートメントを確認するだけでなく、拡張イベントまたはSQLトレースを使用して更新をキャプチャしたときと同じように、統計の更新も確認できます。ステートメントの実行に加えて、CPU、期間、およびIO情報も確認できます。さて、ここでの注意点は、この情報がの場合に表示されることです。 PlanExplorerから統計の更新を呼び出すステートメントを実行します。これは本番環境ではおそらく頻繁には発生しませんが、テストを実行しているときにこれが表示される場合があります(テストには、SELECTクエリの実行だけでなく、INSERT / UPDATE/DELETEクエリも含まれることが望ましいためです。通常のワークロードで参照してください)。ただし、SQL Sentryなどのツールを使用して環境を監視している場合、これらの更新が上位SQLコレクションのしきい値を超えている限りこれらの更新が上位SQLに表示されることがあります。 SQL Sentryには、クエリがトップSQLとしてキャプチャされる前に超える必要があるデフォルトのしきい値があります(たとえば、期間は5秒を超える必要があります)が、これらを変更して、読み取りなどの他のしきい値を追加できます。この例では、テスト目的のみ 、上位SQLの最小期間のしきい値を10ミリ秒に変更し、読み取りのしきい値を500に変更したところ、SQLSentryは統計の更新の一部をキャプチャできました。
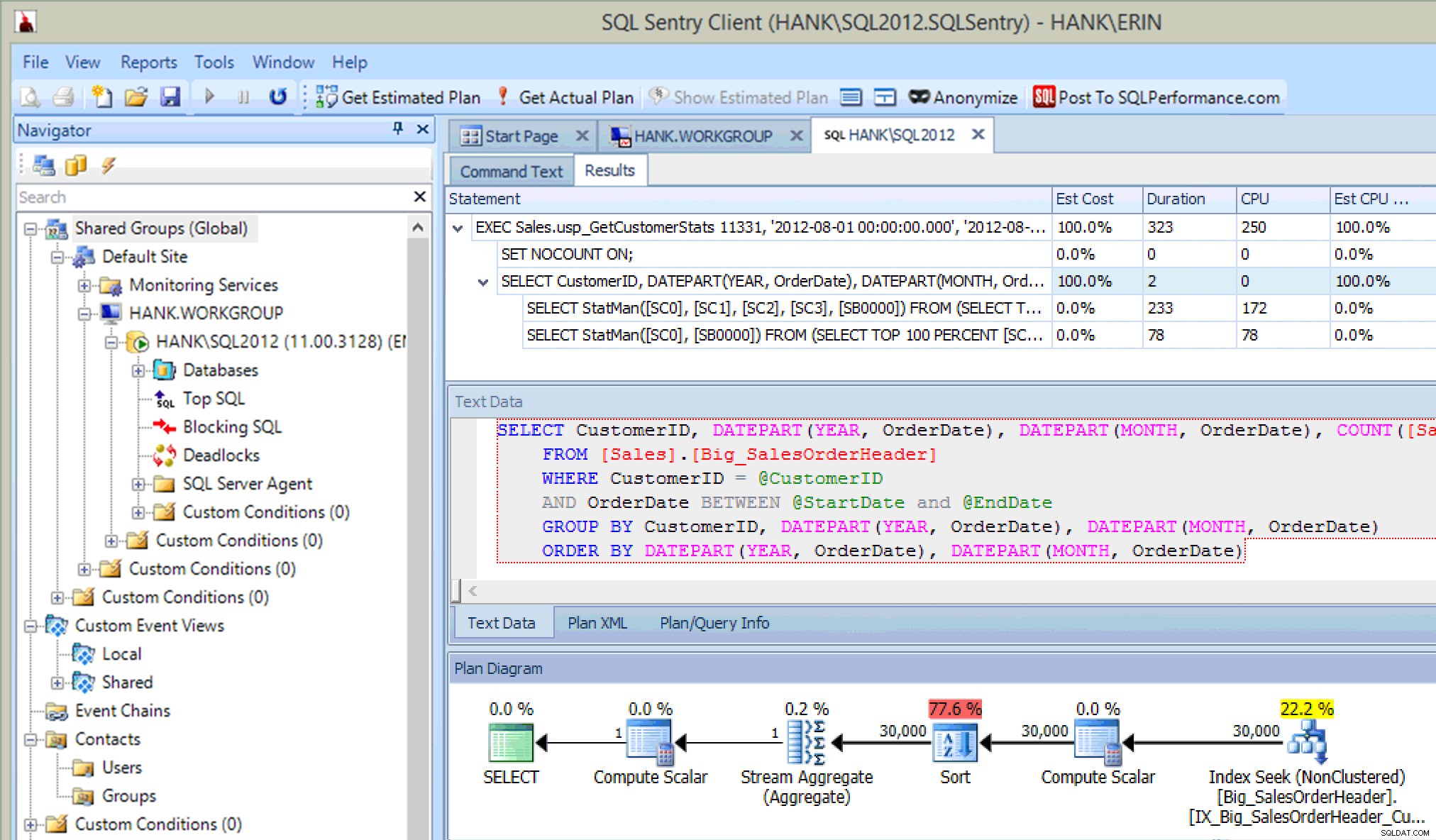
SQLSentryによってキャプチャされた統計の更新
とはいえ、監視がこれらのイベントをキャプチャできるかどうかは、最終的にはシステムリソースと、統計を更新するために読み取る必要のあるデータの量に依存します。統計の更新はこれらのしきい値を超えない可能性があるため、それらを見つけるために、より積極的な調査を行う必要がある場合があります。
概要
私は常にDBAに統計を積極的に管理することを勧めています。つまり、統計を定期的に更新する仕事が整っているということです。ただし、そのジョブが毎晩実行される場合でも(必ずしも推奨しているわけではありません)、一部のテーブルは他のテーブルよりも揮発性が高く、変更数が多いため、統計の更新が1日を通して自動的に行われる可能性があります。これは異常ではなく、テーブルのサイズと変更の量によっては、自動更新がユーザーのクエリに大きな影響を与えない場合があります。 しかし、知る唯一の方法は、それらの更新を監視することです –ネイティブツールまたはサードパーティツールのどちらを使用している場合でも、潜在的な問題を先取りし、問題がエスカレートする前に対処できるようにします。