今年の私の投稿はすべて、統計を待つためのひざまずく反応に関するものでしたが、この投稿では、私の特定のバグベアであるページ寿命パフォーマンスカウンター(これをPLEと呼びます)について話すために、そのテーマから逸脱しています。 。
PLEとはどういう意味ですか?
インターネット上には、ページの平均余命についてさまざまな種類の誤った記述がありますが、最もひどいのは、値300が心配すべき場所のしきい値であると指定しているものです。
このステートメントが非常に誤解を招く理由を理解するには、PLEが実際に何であるかを理解する必要があります。
PLEの定義は、バッファプールに読み込まれたデータファイルページ(データファイルページのメモリ内キャッシュ)が、別のデータ用のスペースを確保するためにメモリからプッシュされる前にメモリに残ると予想される時間(秒単位)です。ファイルページ。 PLEを考える別の方法は、ディスクから読み取られるページ用の空き領域を確保するためのバッファープールへの圧力を瞬時に測定することです。これらの定義の両方について、数値が大きいほど良いです。
適切なPLEしきい値とは何ですか?
300のPLEは、バッファプール全体が効果的にフラッシュされ、5分ごとに再読み取りされることを意味します。 PLEのしきい値ガイダンスである300が最初にMicrosoftによって提供されたとき、2005/2006年頃、サーバー上の平均メモリ量がはるかに少なかったため、この数値の方が理にかなっている可能性があります。
現在、サーバーに64 GB、128 GB、およびそれ以上の量のメモリが日常的に搭載されている場合、5分ごとにディスクからほぼ同じ量のデータが読み取られると、パフォーマンスが低下する問題が発生する可能性があります。
実際には、PLEが300以下でホバリングするまでに、サーバーはすでに悲惨な状況にあります。 PLEがそれほど低くなる前に、あなたは心配し始めるでしょう。
では、心配する必要があるときに使用するしきい値は何ですか?
まあ、それはただのポイントです。その数はすべての人によって異なるため、しきい値を指定することはできません。あなたが本当に本当に数字を使いたいのなら、私の同僚のジョナサン・ケハイアスは式を思いついた:
(GB / 4単位のバッファプールメモリ)x 300その数でさえいくぶん恣意的であり、あなたのマイレージは変わるでしょう。
数字はお勧めしません。私のアドバイスは、パフォーマンスが望ましいレベルにあるときにPLEを測定することです–それは 使用するしきい値。
では、PLEがそのしきい値を下回るとすぐに心配し始めますか?いいえ。PLEがそのしきい値を下回り、そのしきい値を下回ったままになる場合、または急激に低下して理由がわからない場合は、心配し始めます。
これは、PLEドロップを引き起こす操作がいくつかあるためです(例:DBCC CHECKDBの実行) またはインデックスの再構築でそれができる場合もあります)、心配する必要はありません。ただし、大きなPLEの低下が見られ、その原因がわからない場合は、心配する必要があります。
DBCC CHECKDB 不利になり、使用するデータでバッファプールをフラッシュすることを回避しようとすると、PLEドロップが発生する可能性があります(説明については、このブログ投稿を参照してください)。これは、DBCC CHECKDBのクエリ実行メモリが付与されるためです。 はクエリオプティマイザによって誤って計算され、バッファプールのサイズが大幅に減少し(付与用のメモリがバッファプールから盗まれます)、その結果としてPLEが低下する可能性があります。
PLEをどのように監視しますか?
これはトリッキーなビットです。ほとんどの人はBuffer Managerに直接アクセスします PerfMonのパフォーマンスオブジェクトとPage life expectancyを監視します カウンター。これは正しいアプローチですか?ほとんどの場合そうではありません。
今日のサーバーの大部分はNUMAアーキテクチャを使用していると思いますが、これはPLEの監視方法に大きな影響を及ぼします。
NUMAが関係している場合、バッファープールはバッファーノードに分割され、SQLServerが「認識」できるNUMAノードごとに1つのバッファーノードがあります。各バッファノードはPLEを個別に追跡し、Buffer Manager:Page life expectancy counterは、バッファノードのPLEの平均です。バッファプールPLE全体を監視しているだけの場合は、バッファノードの1つへの圧力が平均化によってマスクされる可能性があります(これについては、こちらのブログ投稿で説明します)。
したがって、サーバーがNUMAを使用している場合は、個々のBuffer Node:Page life expectancyを監視する必要があります。 カウンター(NUMAノードごとに1つのバッファーノードパフォーマンスオブジェクトがあります)。それ以外の場合は、Buffer Manager:Page life expectancyを適切に監視できます。 カウンター。
さらに優れているのは、SQL Sentry Performance Advisorなどの監視ツールを使用することです。このツールは、サーバー上のNUMAノードを考慮して、ダッシュボードの一部としてこのカウンターを表示し、アラートを簡単に構成できるようにします。
パフォーマンスアドバイザーの使用例
以下は、単一のNUMAノードを持つシステムのPerformanceAdvisorからのスクリーンキャプチャの一部の例です。
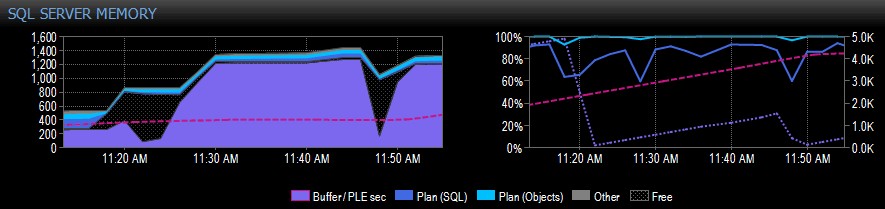
キャプチャの右側にあるピンクの破線は、午前10時30分から午前11時20分までのPLEです。これは、5,000程度まで着実に上昇しており、非常に健全な数値です。午前11時20分直前に大きな落ち込みがあり、その後、午前11時45分まで再び上昇し始め、そこで再び落ち込みます。
これは通常、バッファプールがいっぱいで、すべてのページが使用されている場合に表示されます。その後、クエリが実行され、ディスクから大量の異なるデータが読み取られ、すでにメモリにあるものの多くが置き換えられ、 PLEの急激な低下。このような原因がわからない場合は、さらに詳しく説明するように、調査することをお勧めします。
2番目の例として、以下のスクリーンキャプチャは、サーバーに2つのNUMAノードがあり(2つの紫色のPLEラインがあることがわかります)、パフォーマンスアドバイザを広範囲に使用しているリモートDBAクライアントの1つからのものです。

このクライアントのサーバーでは、毎朝午前5時頃に、インデックスのメンテナンスと整合性チェックのジョブが開始され、PLEが両方のバッファノードにドロップします。これは予想される動作であるため、日中にPLEが再び立ち上がる限り、調査する必要はありません。
PLEドロップについて何ができますか?
PLEの低下の原因がわからない場合は、次のようなことができます。
- 現在問題が発生している場合は、
sys.dm_os_waiting_tasksを使用して、読み取りの原因となっているクエリを調査してください。 DMVは、ページがディスクから読み取られるのを待機しているスレッド(つまり、PAGEIOLATCH_SHを待機しているスレッド)を確認します。 )、それらのクエリを修正します。 - 過去に問題が発生した場合は、sys.dm_exec_query_stats DMVで物理読み取りの数が多いクエリを探すか、その情報を提供できる監視ツール(Performance AdvisorのトップSQLビューなど)を使用してください。次に、それらのクエリを修正します。
- PLEドロップを、データベースのメンテナンスを実行するスケジュールされたエージェントジョブと関連付けます。
-
sys.dm_exec_query_memory_grantsを使用して、クエリ実行メモリメモリの付与が非常に大きいクエリを探します DMVを実行してから、それらのクエリを修正します。
ここでの私の以前の投稿では、#1と#2について詳しく説明しています。サーバーで発生する待機を調査し、クエリプランにリンクするためのスクリプトはここにあります。
「これらのクエリを修正する」はこの投稿の範囲を超えているため、別の機会に、または読者の演習として残しておきます☺
概要
オンラインで読む可能性のある推奨PLEしきい値を信じるという罠にはまらないでください。 PLEの変更に対応する最善の方法は、PLEがあなたのを下回ったときです。 快適さのレベルはそこにあり、そこにとどまります–それは 調査する必要のあるパフォーマンスの問題の兆候。
シリーズの次の記事では、ニージャークパフォーマンスチューニングのもう1つの一般的な原因について説明します。それまでは、トラブルシューティングを行ってください。