多くの制限といくつかの重要な実装上の警告がありますが、適切な状況で正しく使用された場合、インデックス付きビューは依然として非常に強力なSQLServer機能です。一般的な使用法の1つは、基になるデータの事前に集計されたビューを提供することです。これにより、ユーザーは、クエリが実行されるたびに基になる結合、フィルター、および集計を処理するコストをかけずに、結果を直接クエリできます。
列型ストレージやバッチモード処理などの新しいEnterpriseEdition機能は、このタイプの多くの大規模なクエリのパフォーマンス特性を変革しましたが、その処理がどれほど効率的であっても、基礎となるすべての処理を完全に回避するよりも高速な結果を得る方法はありません。になっている可能性があります。
インデックス付きビュー(およびそれらのより限定されたいとこ、計算列)が製品に追加される前は、データベースの専門家が複雑なマルチトリガーコードを記述して、重要なクエリの結果を実際のテーブルに表示することがありました。この種の配置は、すべての状況で正しく行うのが難しいことで有名です。特に、基になるデータへの同時変更が頻繁に行われる場合はそうです。
インデックス付きビュー機能を使用すると、これらすべてがはるかに簡単になり、適切に正しく適用されます。データベースエンジンは、インデックス付きビューから読み取られたデータが、基になるクエリおよびテーブルデータと常に一致するようにするために必要なすべてを処理します。
インクリメンタルメンテナンス
SQL Serverは、ベーステーブルのデータが変更されるたびにビューインデックスを適切に自動的に更新することにより、インデックス付きビューデータを基になるクエリと同期させます。この保守作業の費用は、基本データを変更するプロセスによって負担されます。ビューインデックスを維持するために必要な追加の操作は、元の挿入、更新、削除、またはマージ操作の実行プランにサイレントに追加されます。バックグラウンドでは、SQL Serverは、トランザクション分離に関するより微妙な問題も処理します。たとえば、スナップショットまたは読み取りコミットスナップショット分離で実行されているトランザクションの正しい処理を保証します。
「トリガーコードによって維持される要約テーブル」の実装を試みた人なら誰でも知っているように、ビューインデックスを正しく維持するために必要な追加の実行プラン操作を構築することは簡単なことではありません。タスクの複雑さは、インデックス付きビューに非常に多くの制限がある理由の1つです。サポートされる表面積を内部結合、射影、選択(フィルター)、およびSUMとCOUNT_BIGの集計に制限すると、実装の複雑さが大幅に軽減されます。
インデックス付きのビューは段階的に維持されます 。これは、クエリプロセッサがビューに対するベーステーブルの変更の正味の影響を判断し、ビューを最新にするために必要な変更のみを適用することを意味します。単純なケースでは、ベーステーブルの変更と現在ビューに保存されているデータから必要なデルタを計算できます。ビュー定義に結合が含まれている場合、実行プランのインデックス付きビューメンテナンス部分も結合テーブルにアクセスする必要がありますが、適切なベーステーブルインデックスがあれば、これは通常効率的に実行できます。
実装をさらに簡素化するために、SQL Serverは常に同じ基本計画形状を(開始点として)使用して、インデックス付きビューの保守操作を実装します。クエリオプティマイザによって提供される通常の機能を使用して、必要に応じて標準のメンテナンス形状を簡素化および最適化します。次に、これらの概念をまとめるのに役立つ例を見ていきます。
例1-単一行の挿入
次の単純なテーブルとインデックス付きビューがあるとします。
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); そのスクリプトが実行されると、サンプルテーブルのデータは次のようになります。

また、インデックス付きビューには次のものが含まれます。

この設定のインデックス付きビューのメンテナンスプランの最も簡単な例は、ベーステーブルに単一の行を追加するときに発生します。
INSERT dbo.T1
(GroupID, Value)
VALUES
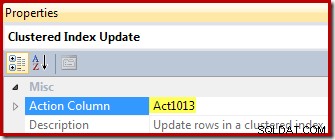
(3, 6); この挿入の実行プランを以下に示します。
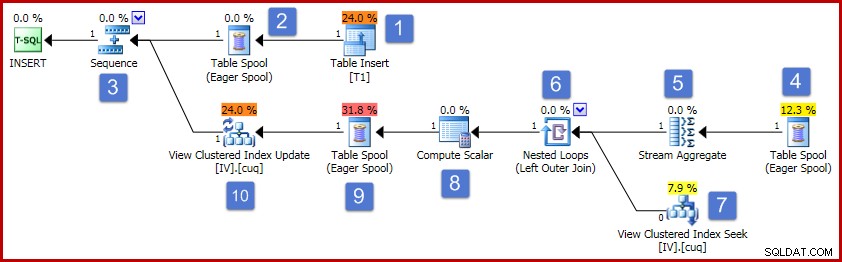
図の番号に従って、この実行プランの操作は次のように進行します。
- テーブル挿入演算子は、新しい行をベーステーブルに追加します。これは、ベーステーブル挿入に関連付けられている唯一のプラン演算子です。残りのすべてのオペレーターは、インデックス付きビューの保守に関心があります。
- Eager Table Spoolは、挿入された行データを一時ストレージに保存します。
- Sequenceオペレーターは、Sequenceの次のブランチがアクティブ化される前に、プランの最上位ブランチが完了するまで実行されることを確認します。この特殊なケース(単一の行を挿入)では、シーケンス(および位置2と4のスプール)を削除して、StreamAggregate入力をTableInsertの出力に直接接続することが有効です。この可能な最適化は実装されていないため、シーケンスとスプールは残ります。
- この熱心なテーブルスプールは、位置2のスプールに関連付けられています(このリンクを明示的に提供するプライマリノードIDプロパティがあります)。スプールは、プライマリスプールによって書き込まれた同じ一時ストレージから行(この場合は1行)を再生します。上記のように、スプールと位置2および4は不要であり、インデックス付きビューのメンテナンス用の汎用テンプレートに存在するという理由だけで機能します。
- Stream Aggregateは、挿入されたセットのValue列データの合計を計算し、ビューキーグループごとに存在する行数をカウントします。出力は、ビューをベースデータと同期させるために必要な増分データです。クエリオプティマイザは単一の値のみが処理されていることを認識しているため、StreamAggregateにはGroupBy要素がないことに注意してください。ただし、オプティマイザは、集計を射影に置き換えるために同様のロジックを適用しません(単一の値の合計は値自体であり、カウントは常に単一行の挿入に対して1つになります)。単一行のデータの合計とカウントの集計を計算することはコストのかかる操作ではないため、この最適化の失敗についてはそれほど心配する必要はありません。
- 結合は、計算された各増分変更を、インデックス付きビューの既存のキーに関連付けます。新しく挿入されたデータがビュー内の既存のデータに対応していない可能性があるため、結合は外部結合です。
- この演算子は、変更する行をビューで見つけます。
- ComputeScalarには2つの重要な責任があります。まず、各増分変更がビュー内の既存の行に影響するかどうか、または新しい行を作成する必要があるかどうかを決定します。これは、外部結合が結合のビュー側からnullを生成したかどうかを確認することによってこれを行います。サンプルの挿入は、現在ビューに存在しないグループ3用であるため、新しい行が作成されます。 Compute Scalarの2番目の機能は、ビュー列の新しい値を計算することです。新しい行をビューに追加する場合、これは単にStreamAggregateからの増分合計の結果です。ビューの既存の行を更新する場合、新しい値は、ビューの行の既存の値にStreamAggregateからの増分合計を加えたものになります。
- この熱心なテーブルスプールはハロウィーンの保護用です。挿入操作が、クエリのデータアクセス側でも参照されるテーブルに影響を与える場合は、正確にするために必要です。単一行のメンテナンス操作によって既存のビュー行が更新される場合、技術的には必要ありませんが、とにかく計画に残ります。
- プランの最後の演算子は更新演算子としてラベル付けされていますが、ノード8のCompute Scalarによって追加された「アクションコード」列の値に応じて、受信する行ごとに挿入または更新のいずれかを実行します。 。より一般的には、この更新演算子は挿入、更新、および削除が可能です。
そこにはかなりの詳細があるので、要約すると:
- 集計グループのデータは、ビューの一意のクラスター化されたキーによって変更されます。キーごとの各列に対するベーステーブルの変更の正味の影響を計算します。
- 外部結合は、キーごとの増分変更をビュー内の既存の行に接続します。
- 計算スカラーは、新しい行をビューに追加するか、既存の行を更新するかを計算します。ビューの挿入または更新操作の最終的な列の値を計算します。
- ビュー更新オペレーターは、アクションコードの指示に従って、新しい行を挿入するか、既存の行を更新します。
例2–複数行の挿入
信じられないかもしれませんが、上記の単一行の基本テーブル挿入実行プランは、いくつかの簡略化の対象でした。いくつかの可能なさらなる最適化が見落とされましたが(前述のとおり)、クエリオプティマイザーは、一般的なインデックス付きビューのメンテナンステンプレートから一部の操作を削除し、他の操作の複雑さを軽減することができました。
これらの最適化のいくつかは、単一の行を挿入したために許可されましたが、オプティマイザーがベーステーブルに追加されているリテラル値を確認できたため、他の最適化が有効になりました。たとえば、オプティマイザは、挿入されたグループ値がビューのWHERE句の述語を渡すことを確認できます。
ローカル変数に値が「非表示」の2つの行を挿入すると、もう少し複雑な計画が得られます。
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
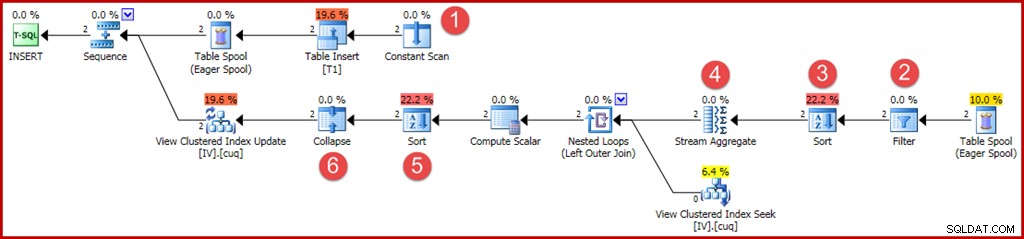
新規または変更された演算子には、以前と同じように注釈が付けられます。
- コンスタントスキャンは、挿入する値を提供します。以前は、単一行挿入の最適化により、この演算子を省略できました。
- ベーステーブルに挿入されたグループがビューのWHERE句と一致することを確認するには、明示的なFilter演算子が必要になります。たまたま、両方の新しい行がテストに合格しますが、オプティマイザーは変数の値を確認してこれを事前に知ることはできません。さらに、プランの将来の再利用では変数の値が異なる可能性があるため、このフィルターをスキップしたプランをキャッシュすることは安全ではありません。
- 行がグループ順にStreamAggregateに到着するようにするには、並べ替えが必要になりました。 1つの行を並べ替えるのは無意味であるため、並べ替えは以前に削除されました。
- Stream Aggregateに、ビューの一意のクラスター化されたキーと一致する「groupby」プロパティが追加されました。
- この並べ替えは、ビューキー、アクションコードの順序で行を表示するために必要です。これは、折りたたみ演算子を正しく操作するために必要です。並べ替えは完全にブロックする演算子であるため、ハロウィーン保護のための熱心なテーブルスプールは必要ありません。
- 新しい折りたたみ演算子は、同じキー値に対する隣接する挿入と削除を1つの更新操作に結合します。この演算子は実際には必須ではありません この場合、削除アクションコードを生成できないため(挿入と更新のみ)。これは見落としであるか、おそらく安全上の理由で残されたもののようです。更新クエリプランの自動生成された部分は非常に複雑になる可能性があるため、確実に知ることは困難です。
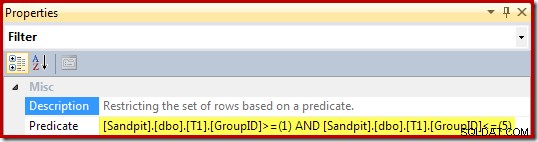
フィルタのプロパティ(ビューのWHERE句から派生)は次のとおりです。
Stream Aggregateは、ビューキーでグループ化し、グループごとの合計とカウントの集計を計算します。
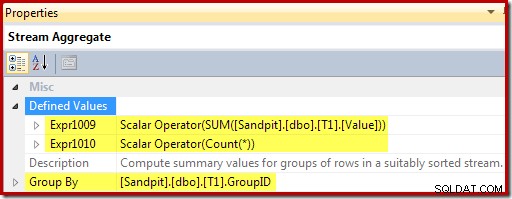
Compute Scalarは、行ごとに実行するアクション(この場合は挿入または更新)を識別し、ビューに挿入または更新する値を計算します。
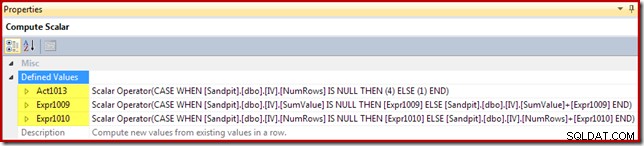
アクションコードには、[Act1xxx]の式ラベルが付けられています。有効な値は、更新の場合は1、削除の場合は3、挿入の場合は4です。ビューに一致する行が見つからなかった場合(つまり、外部結合がNumRows列に対してnullを返した場合)、このアクション式は挿入(コード4)になります。一致する行が見つかった場合、アクションコードは1(更新)です。
NumRowsは、ビューの必須のCOUNT_BIG(*)列に付けられた名前であることに注意してください。ビューからの削除につながる可能性のあるプランでは、Compute Scalarは、この値がゼロになる時期(現在のグループの行がない)を検出し、削除アクションコード(3)を生成します。
残りの式は、ビュー内の合計とカウントの集計を維持します。ただし、式ラベル[Expr1009]と[Expr1010]は新しいものではないことに注意してください。これらは、StreamAggregateによって作成されたラベルを参照します。ロジックは単純です。一致する行が見つからなかった場合、挿入する新しい値は、集計で計算された値だけです。ビュー内で一致する行が見つかった場合、更新された値は、行内の現在の値に集計によって計算された増分を加えたものです。
最後に、ビュー更新演算子(SSMSではクラスター化インデックス更新として表示)は、アクション列参照(Compute Scalarによって定義された[Act1013])を示します。
例3–複数行の更新
これまでは、ベーステーブルへの挿入のみを確認してきました。削除の実行計画は非常に似ていますが、詳細な計算にわずかな違いがあります。したがって、この次の例では、ベーステーブルの更新のメンテナンスプランを確認します。
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); 以前と同様に、このクエリは変数を使用してオプティマイザからリテラル値を非表示にし、一部の簡略化が適用されないようにします。また、2つの別々のグループを更新するように注意して、オプティマイザーが単一のグループ(インデックス付きビューの単一の行)のみが影響を受けることを知っている場合に適用できる最適化を防ぎます。更新クエリの注釈付き実行プランは次のとおりです。
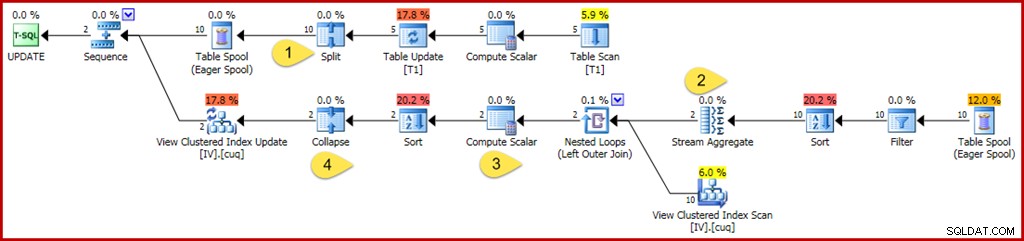
変更点と関心のあるポイントは次のとおりです。
- 新しいSplit演算子は、各ベーステーブル行の更新を個別の削除および挿入操作に変換します。各更新行は2つの別々の行に分割され、プランのこの時点以降の行数が2倍になります。 Splitは、誤った一時的な一意キー違反エラーから保護するために必要なsplit-sort-collapseパターンの一部です。
- Stream Aggregateは、削除または挿入のいずれかを指定できる着信行を考慮して変更されます(分割のため、行のアクションコード列によって決定されます)。挿入行は、合計集計の元の値に寄与します。アクション行の削除では、符号が逆になります。同様に、ここでの行数の集計では、挿入行を+1としてカウントし、削除行を–1としてカウントします。
- Compute Scalarロジックも変更され、グループごとの変更の正味の効果により、マテリアライズドビューに対する最終的な挿入、更新、または削除アクションが必要になる可能性があることを反映しています。この特定の更新クエリによって、このビューに対して行が挿入または削除されることは実際には不可能ですが、それを推測するために必要なロジックは、オプティマイザーの現在の推論能力を超えています。更新クエリまたはビュー定義がわずかに異なると、実際には、ビューアクションの挿入、削除、および更新が混在する可能性があります。
- 折りたたみ演算子は、上記のsplit-sort-collapseパターンでの役割のためだけに強調表示されています。同じキーの削除と挿入のみを折りたたむことに注意してください。折りたたみ後の比類のない削除と挿入は完全に可能です(そしてごく普通のことです)。
以前と同様に、インデックス付きビューのメンテナンス作業を理解するために確認する必要のある主要な演算子プロパティは、フィルター、ストリーム集計、外部結合、および計算スカラーです。
例4–結合を使用した複数行の更新
インデックス付きビューのメンテナンス実行プランの概要を完了するには、複数のテーブルを結合し、選択リストにプロジェクションを含む新しいサンプルビューが必要です。
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); 正確性を確保するために、インデックス付きビューの要件の1つは、合計がnullと評価される可能性のある式を操作できないことです。上記のビュー定義は、その要件を満たすためにISNULLを使用しています。非常に包括的なインデックスメンテナンスプランコンポーネントを生成するサンプル更新クエリを、それが生成する実行プランとともに以下に示します。
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
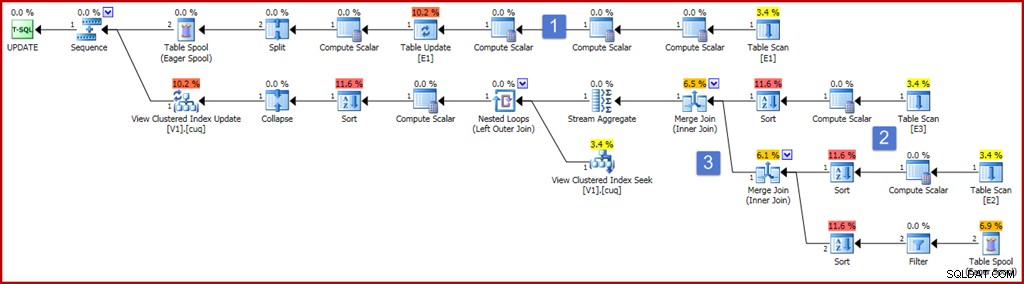
計画は今ではかなり大きく複雑に見えますが、ほとんどの要素はすでに見たとおりです。主な違いは次のとおりです。
- 計画の最上位のブランチには、いくつかの追加のComputeScalar演算子が含まれています。これらはよりコンパクトに配置できますが、基本的には、非グループ化列の更新前の値をキャプチャするために存在します。テーブル更新の左側にあるComputeScalarは、ISNULLプロジェクションが適用された、列「a」の更新後の値をキャプチャします。
- プランのこの領域にある新しいComputeScalarは、各ソーステーブルのISNULL式によって生成された値を計算します。一般に、ビュー内の結合されたテーブルの投影は、ここではComputeScalarsで表されます。プランのこの領域でのソートは、オプティマイザーがコスト上の理由でマージ結合戦略を選択したためにのみ存在します(マージには結合キーでソートされた入力が必要であることを忘れないでください)。
- 2つの結合演算子は新しく、ビュー定義に結合を実装するだけです。これらの結合は常に、ビューに対する変更の増分効果を計算するStreamAggregateの前に表示されます。ベーステーブルを変更すると、結合基準を満たしていた行が結合しなくなる可能性があり、その逆の場合もあることに注意してください。これらの潜在的な複雑さはすべて、Stream Aggregateによって正しく処理され(インデックス付きのビュー制限が与えられた場合)、結合が実行された後、ビューキーごとの変更の概要が生成されます。
最終的な考え
この最後の計画は、インデックス付きビューを維持するためのほぼ完全なテンプレートを表していますが、非クラスター化インデックスをビューに追加すると、ビュー更新オペレーターの出力からスプールされたオペレーターも追加されます。追加の分割(およびビューの非クラスター化インデックスが一意である場合は並べ替えと折りたたみの組み合わせ)を除いて、この可能性について特別なことは何もありません。ベーステーブルクエリに出力句を追加すると、いくつかの興味深い追加の演算子も生成される可能性がありますが、これらはインデックス付きビューのメンテナンス自体に固有のものではありません。
完全な全体的な戦略を要約すると:
- ベーステーブルの変更は通常どおり適用されます。更新前の値が取得される場合があります。
- 分割演算子を使用して、更新を削除/挿入のペアに変換できます。
- 熱心なスプールは、ベーステーブルの変更情報を一時ストレージに保存します。
- 更新されたベーステーブル(スプールから読み取られる)を除いて、ビュー内のすべてのテーブルにアクセスします。
- ビューの投影は、ComputeScalarsで表されます。
- ビューのフィルターが適用されます。フィルタはスキャンにプッシュされるか、残差としてシークされます。
- ビューで指定された結合が実行されます。
- アグリゲートは、クラスター化されたビューキーによってグループ化された正味の増分変更を計算します。
- インクリメンタル変更セットは、ビューに外部結合されています。
- Compute Scalarは、変更ごとにアクションコード(ビューに対する挿入/更新/削除)を計算し、挿入または更新される実際の値を計算します。計算ロジックは、集計の出力とビューへの外部結合の結果に基づいています。
- 変更はビューキーとアクションコードの順序に並べ替えられ、必要に応じて更新に折りたたまれます。
- 最後に、増分変更がビュー自体に適用されます。
これまで見てきたように、クエリオプティマイザで使用できる通常のツールセットは、プランの自動生成された部分に引き続き適用されます。つまり、上記の1つ以上の手順を簡略化、変換、または完全に削除できます。ただし、計画の基本的な形と操作はそのままです。
コード例を順守している場合は、次のスクリプトを使用してクリーンアップできます。
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;